目录
协同过滤
协同过滤,简称CF算法是一种借助"集体计算"的途径。它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。其内在思想是相似度的定义。
协同过滤常被应用于推荐系统。这些技术旨在补充用户—商品关联矩阵中所缺失的部分。其中用户和物品由一小部分已知因素描述,用这些因素可以预测缺失值。
协同过滤的类型
- 在基于用户的协同过滤(User CF )方法的中,如果两个用户表现出相似的偏好(即对相同物品的偏好大体相同),那就认为他们的兴趣类似。要对他们中的一个用户推荐一个未知物品。
如用户A、B、C的偏好矩阵如下:
| 用户/物品 |
物品A |
物品B |
物品C |
物品D |
物品E |
| 用户A |
√ |
|
√ |
√ |
|
| 用户B |
√ |
|
|
|
|
| 用户C |
√ |
√ |
√ |
推荐 |
√ |
因为用户A喜欢物品A、物品C、物品D;而用户C喜欢物品A、物品C,算法认为用户A和用户C相似,因此给用户C推荐用户A系统的物品D。
- 同样也可以借助基于物品(Item CF)的方法来做推荐。这种方法通常根据现有用户对物品的偏好或是评级情况,来计算物品之间的某种相似度。 这时,相似用户评级相同的那些物品会被认为更相近。一旦有了物品之间的相似度,便可用用户接触过的物品来表示这个用户,然后找出和这些已知物品相似的那些物品,并将这些物品推荐给用户。同样,与已有物品相似的物品被用来生成一个综合得分,而该得分用于评估未知物品的相似度。
如物品分类:
| 物品名 |
类型 |
| 物品A |
类型A |
| 物品B |
类型B |
| 物品C |
类型C |
| 物品D |
类型A |
| 物品E |
类型B |
用户购买历史矩阵:
| 用户/物品 |
物品A |
物品B |
物品C |
物品D |
物品E |
| 用户A |
√ |
|
√ |
√ |
|
| 用户B |
√ |
|
|
|
|
| 用户C |
√ |
√ |
√ |
推荐 |
√ |
物品A和物品D同属于类型A,用户A购买了物品D,所以把物品D推荐给用户C。
协同过滤的评价方法
(1)平均绝对误差(MAE)
统计精度度量方法中的平均绝对误差(MAE)被广泛用于评价协同过滤推荐系统的推荐质量。因此,推荐质量评价采用了常见的平均绝对误差MAE在测试集上首先运用推荐系统预测出用户的评分,然后根据测试集中用户的实际评分,计算出两者的偏差,即为MAE的值。
假设预测用户评分值为{p1,p2…,pn }对应的实际评分值为 {q1,q2, …,qn },则MAE的计算公式为:
(2)均方根误差RMSE的计算公式为:
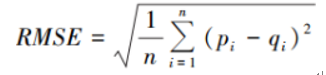
冷启动问题
在产品刚刚上线、新用户到来的时候,如果没有用户在应用上的行为数据,也无法预测其兴趣爱好。另外,当新商品上架也会遇到冷启动的问题,没有收集到任何一个用户对其浏览,点击或者购买的行为,也无从对商品进行推荐。
Spark中协同过滤算法的实现方式
Spark ML中的协同过滤算法基于最小二乘法(Alternating Least Squares 即ALS)实现。
ALS算法属于User-Item CF,也叫做混合CF。它同时考虑了User和Item两个方面,Spark用它学习那些未知的潜在因素。用户和商品的关系,可以抽象为如下的三元组:<User,Item,Rating>。其中,Rating是用户对商品的评分,表征用户对该商品的喜好程度。
假设有一批用户数据,其中包含m个User和n个Item,则我们定义Rating矩阵,其中的元素表示第u个User对第i个Item的评分。
在实际使用中,由于n和m的数量都十分巨大,因此R矩阵的规模很容易就会突破亿项级。传统的矩阵分解方法对于这么大的数据量就很难处理了。另一方面,一个用户也不可能给所有商品评分,因此,R矩阵注定是个稀疏矩阵。
实际中,User和Item都有很多维度,比如User有姓名、性别、年龄等;Item有名称、产地、类别等。计算时需要将R矩阵映射到这些维度上,映射方法参考“奇异值分解”。投影结果如下:

通常,K要比m和n小得多,从而达到降维的目的。我们给算法喂数据时并没有维度信息,维度只是假设存在,因此这里的关联维度又被称为Latent factor。
显式反馈
显式反馈表现为Users对Items的直接评分。
隐式反馈
用户给商品评分是个非常简单的用户行为。在实际中,还有大量的用户行为,同样能够间接反映用户的喜好,比如用户的购买记录、搜索关键字,甚至是鼠标的移动。我们将这些间接用户行为称之为隐式反馈(implicit feedback),以区别于评分这样的显式反馈(explicit feedback)。
隐式反馈有以下几个特点:
1.没有负面反馈(negative feedback)。用户一般会直接忽略不喜欢的商品,而不是给予负面评价。
2.隐式反馈包含大量噪声。比如,电视机在某一时间播放某一节目,然而用户已经睡着了,或者忘了换台。
3.显式反馈表现的是用户的喜好(preference),而隐式反馈表现的是用户的信任(confidence)。比如用户最喜欢的一般是电影,但观看时间最长的却是连续剧。大米购买的比较频繁,量也大,但未必是用户最想吃的食物。
4.隐式反馈非常难以量化。
1)Spark 协同过滤算法
ALS的参数:
- numBlocks:users和items矩阵被分成的块数,各块之间可以平行计算,加快计算速度,默认值是10
- rank:模型中Latent factor 的大小,默认值为10
- maxIter:默认的最大迭代次数,模式是10
- regParam:指定正则化参数,默认是10
- implicitPrefs:指定是否使用隐式反馈,默认为显式反馈;true为使用隐式反馈。
- alpha:当使用隐式反馈时该参数生效;对观察值执行控制基线置信度,默认值为1。
- nonnegative:是否对ALS使用非0约束,默认为false,即不使用。
实例:
输入数据请到 https://github.com/apache/spark/tree/master/data/mllib/als/sample_movielens_ratings.txt 下载
import java.io.File;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.ml.evaluation.RegressionEvaluator;
import org.apache.spark.ml.recommendation.ALS;
import org.apache.spark.ml.recommendation.ALSModel;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class ALStest {
public static void main(String[] args) {
String rootDir = System.getProperty("user.dir") + File.separator;
String fileResourcesDir = rootDir + "resources" + File.separator;
// 训练数据的路径
String filePath = fileResourcesDir + "sample_movielens_ratings.txt";
SparkSession spark = SparkSession.builder().master("local[4]").appName("test").getOrCreate();
JavaRDD<Rating> ratingsRDD = spark.read().textFile(filePath).javaRDD().map(Rating::parseRating);
Dataset<Row> ratings = spark.createDataFrame(ratingsRDD, Rating.class);
Dataset<Row>[] splits = ratings.randomSplit(new double[] { 0.8, 0.2 });
Dataset<Row> training = splits[0];
Dataset<Row> test = splits[1];
//使用训练数据通过ALS算法训练
ALS als = new ALS().setMaxIter(5).setRegParam(0.01).setUserCol("userId").setItemCol("movieId")
.setRatingCol("rating");
ALSModel model = als.fit(training);
// evaluation metrics
//删除冷启动数据,即NaN值的数据
model.setColdStartStrategy("drop");
//在测试数据上进行预测
Dataset<Row> predictions = model.transform(test);
//用均方根误差评估模型
RegressionEvaluator evaluator = new RegressionEvaluator().setMetricName("rmse").setLabelCol("rating")
.setPredictionCol("prediction");
double rmse = evaluator.evaluate(predictions);
//给每个用户推荐Top 10部电影
Dataset<Row> userRecs = model.recommendForAllUsers(10);
//给每部电影推荐Top 10 个用户
Dataset<Row> movieRecs = model.recommendForAllItems(10);
// 给指定用户推荐10部电影
Dataset<Row> users = ratings.select(als.getUserCol()).distinct().limit(3);
Dataset<Row> userSubsetRecs = model.recommendForUserSubset(users, 10);
//给指定电影推荐10个用户
Dataset<Row> movies = ratings.select(als.getItemCol()).distinct().limit(3);
Dataset<Row> movieSubSetRecs = model.recommendForItemSubset(movies, 10);
training.show(false);
predictions.show(false);
userRecs.show(false);
movieRecs.show(false);
System.out.println("均方根误差 = " + rmse);
}
}