
大家好,我们来探讨如何爬取虎扑NBA官网数据,并且将数据写入Excel中同时自动生成折线图,主要有以下几个步骤:
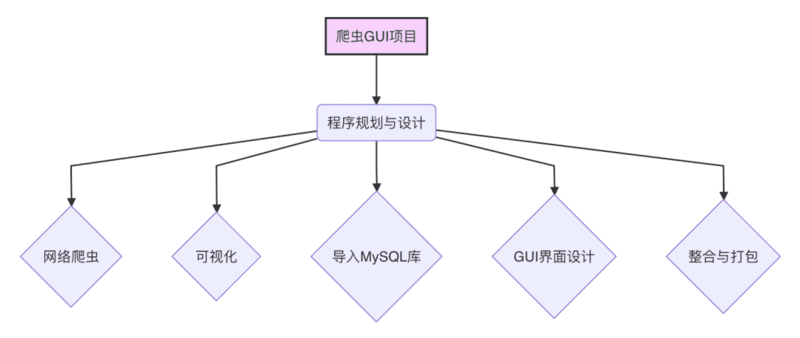
本文将分以下两个部分进行分别讲解:
在虎扑NBA官网球员页面中进行爬虫,获取球员数据。
清洗整理爬取的球员数据,对其进行可视化。
项目主要涉及的Python模块:
requests pandas bs4
爬虫部分
爬虫部分整理思路如下
观察URL1的源代码找到球队名称与对应URL2观察URL2的源代码找到球员对应的URL3观察URL3源代码找到对应球员基本信息与比赛数据并进行筛选存储
其实爬虫就是在html上操作,而html的结构很简单就只有一个,就是一个大框讨一个小框,小框再套小框,这样的一层层嵌套。
目标URL如下:
URL1:http://nba.hupu.com/players/
URL2(此处以湖人球队为例):https://nba.hupu.com/players/...
URL3(此处以詹姆斯为例):https://nba.hupu.com/players/...
先引用模块
from bs4 import BeautifulSoupimport requestsimport xlsxwriterimport os
查看URL1源代码,可以看到球队名词及其对应的URL2在span标签中<span class>
近期有很多朋友通过私信咨询有关Python学习问题。为便于交流,点击蓝色自己加入讨论解答资源基地