好啦,通过昨天的学习我们已经对于python这个语言有了一定的了解,但对于深度学习来说,还是不够了,除了那些课下特别用工的同学哈 。那么今天呢,主要介绍的五大数据类型,以及python编程的一些技能。
文章目录
一.对五大数据类型的常用操作。
1.数字
Python Number 数据类型用于存储数值。
Python Number 数据类型用于存储数值,包括整型、长整型、浮点型、复数。
(1)Python math 模块:Python 中数学运算常用的函数基本都在 math 模块
import math
print(math.ceil(4.1)) #返回数字的上入整数
print(math.floor(4.9)) #返回数字的下舍整数
print(math.fabs(-10)) #返回数字的绝对值
print(math.sqrt(9)) #返回数字的平方根
print(math.exp(1)) #返回e的x次幂
(2)Python随机数
首先import random,使用random()方法即可随机生成一个[0,1)范围内的实数
import random
ran = random.random()
print(ran)
调用 random.random() 生成随机数时,每一次生成的数都是随机的。但是,当预先使用 random.seed(x) 设定好种子之后,其中的 x 可以是任意数字,此时使用 random() 生成的随机数将会是同一个。
print ("------- 设置种子 seed -------")
random.seed(10)
print ("Random number with seed 10 : ", random.random())
# 生成同一个随机数
random.seed(10)
print ("Random number with seed 10 : ", random.random())
randint()生成一个随机整数
ran = random.randint(1,20)
print(ran)
二.字符串
字符串连接:+
a = "Hello "
b = "World "
print(a + b)
print(a,b)
重复输出字符串:*
a = "Hello "
print(a * 3)
通过索引获取字符串中字符[]
a = "Hello "
print(a[0])
字符串截取[:] 牢记:左闭右开
a = "Hello "
print(a[1:4])
判断字符串中是否包含给定的字符: in, not in
a = "Hello "
print('e' in a)
print('e' not in a)
join():以字符作为分隔符,将字符串中所有的元素合并为一个新的字符串
new_str = '-'.join('Hello')
print(new_str)
转义字符 \,\t是空格,'表示转义’,即把‘作为字符串输出来而不是作为功能的引号
print("The \t is a tab")
print('I\'m going to the movies')
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。
print('''I'm going to the movies''')
html = '''
<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>ERROR</H3>
<B>%s</B><P>
<FORM><INPUT TYPE=button VALUE=Back
ONCLICK="window.history.back()"></FORM>
</BODY></HTML>
'''
print(html)
三、列表
作用:类似其他语言中的数组
声明一个列表,并通过下标或索引获取元素
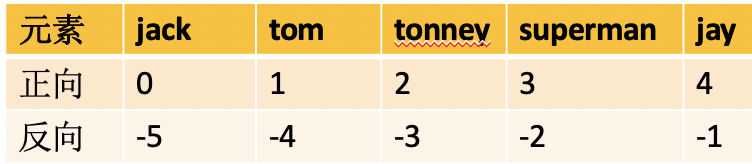
#声明一个列表
names = ['jack','tom','tonney','superman','jay']
#通过下标或索引获取元素
print(names[0])
print(names[1])
#获取最后一个元素
print(names[-1])
print(names[len(names)-1])
#获取第一个元素
print(names[-5])
#遍历列表,获取元素
for name in names:
print(name)
#查询names里面有没有superman
for name in names:
if name == 'superman':
print('有超人')
break
else:
print('有超人')
#更简单的方法,来查询names里有没有superman
if 'superman' in names:
print('有超人')
else:
print('有超人')
列表元素添加
#声明一个空列表
girls = []
#append(),末尾追加
girls.append('杨超越')
print(girls)
#extend(),一次添加多个。把一个列表添加到另一个列表 ,列表合并。
models = ['刘雯','奚梦瑶']
girls.extend(models)
#girls = girls + models
print(girls)
#insert():指定位置添加
girls.insert(1,'虞书欣')
print(girls)
列表元素修改,通过下标找到元素,然后用=赋值
fruits = ['apple','pear','香蕉','pineapple','草莓']
print(fruits)
fruits[-1] = 'strawberry'
print(fruits)
'''
将fruits列表中的‘香蕉’替换为‘banana’
'''
#这个是无效的
for fruit in fruits:
if '香蕉' in fruit:
fruit = 'banana'
print(fruits)
for i in range(len(fruits)):
if '香蕉' in fruits[i]:
fruits[i] = 'banana'
break
print(fruits)
列表元素删除
words = ['cat','hello','pen','pencil','ruler']
del words[1]
print(words)
words = ['cat','hello','pen','pencil','ruler']
words.remove('cat')
print(words)
words = ['cat','hello','pen','pencil','ruler']
#删除第二个元素
words.pop(1)
print(words)
列表切片
在Python中处理列表的部分元素,称之为切片。
创建切片,可指定要使用的第一个元素和最后一个元素的索引。注意:左闭右开
将截取的结果再次存放在一个列表中,所以还是返回列表

animals = ['cat','dog','tiger','snake','mouse','bird']
print(animals[2:5])
print(animals[-1:])
print(animals[-3:-1])
print(animals[-5:-1:2])
print(animals[::-2])
列表排序
随机生成10个不同的整数,并进行排序
'''
生成10个不同的随机整数,并存至列表中
'''
import random
random_list = []
#这么写的话会存在一定的问题,最后可能列表里没有10个数
for i in range(10):
ran = random.randint(1,20)
if ran not in random_list:
random_list.append(ran)
print(random_list)
import random
random_list = []
#下面这种做法就解决上面的问题啦
i = 0
while i < 10:
ran = random.randint(1,20)
if ran not in random_list:
random_list.append(ran)
i+=1
print(random_list)
#然后进行排序,默认升序
new_list = sorted(random_list)
print(new_list)
#降序
new_list = sorted(random_list,reverse =True)
print(new_list)
元组
与列表类似,但元组中的内容不可修改
tuple1 = ()
print(type(tuple1))
注意:元组中只有一个元素时,需要在后面加逗号!
tuple2 = ('hello')
print(type(tuple2)) #这个将会是一个str类型
tuple3 = ('hello',)
print(type(tuple3)) # 这样就好啦
import random
random_list = []
for i in range(10):
ran = random.randint(1,20)
random_list.append(ran)
print(random_list)
random_tuple = tuple(random_list)
print(random_tuple)
元组不能修改,所以不存在往元组里加入元素。
那作为容器的元组,如何存放元素?
import random
random_list = []
for i in range(10):
ran = random.randint(1,20)
random_list.append(ran)
print(random_list)
random_tuple = tuple(random_list)
print(random_tuple)
print(random_tuple)
print(random_tuple[0])
print(random_tuple[-1])
print(random_tuple[1:-3])
print(random_tuple[::-1])
元组的修改:
t1 = (1,2,3)+(4,5)
print(t1)
t2 = (1,2) * 2
print(t2)
元组的一些函数:
print(max(random_tuple))
print(min(random_tuple))
print(sum(random_tuple))
print(len(random_tuple))
#统计元组中4的个数
print(random_tuple.count(4))
#元组中4所对应的下标,如果不存在,则会报错
print(random_tuple.index(4))
#判断元组中是否存在1这个元素
print(4 in random_tuple)
#返回元组中4所对应的下标,不会报错
if(4 in random_tuple):
print(random_tuple.index(4))
` ``
元组的拆包与装包
```python
#定义一个元组
t3 = (1,2,3)
#将元组赋值给变量a,b,c
a,b,c = t3
#打印a,b,c
print(a,b,c)
#当元组中元素个数与变量个数不一致时
#定义一个元组,包含5个元素
t4 = (1,2,3,4,5)
#将t4[0],t4[1]分别赋值给a,b;其余的元素装包后赋值给c
a,b,*c = t4
print(a,b,c)
print(c)
print(*c)
字典
#定义一个空字典
dict1 = {
}
dict2 = {
'name':'杨超越','weight':45,'age':25}
print(dict2['name'])
#list可以转成字典,但前提是列表中元素都要成对出现
dict3 = dict([('name','杨超越'),('weight',45)])
print(dict3)
#{'name': '杨超越', 'weight': 45}
dict4 = {
}
dict4['name'] = '虞书欣'
dict4['weight'] = 43
print(dict4)
#{'name': '虞书欣', 'weight': 43}
#修改字典
dict4['weight'] = 44
print(dict4)
字典的操作
#字典里的函数 items() keys() values()
dict5 = {
'杨超越':165,'虞书欣':166,'上官喜爱':164}
print(dict5.items())
for key,value in dict5.items():
if value > 165:
print(key)
#values() 取出字典中所有的值,保存到列表中
results = dict5.values()
print(results)
#求小姐姐的平均身高
heights = dict5.values()
print(heights)
total = sum(heights)
avg = total/len(heights)
print(avg)
names = dict5.keys()
print(names)
#print(dict5['赵小棠'])
print(dict5.get('赵小棠'))
print(dict5.get('赵小棠',170)) #如果能够取到值,则返回字典中的值,否则返回默认值170
dict6 = {
'杨超越':165,'虞书欣':166,'上官喜爱':164}
del dict6['杨超越']
print(dict6)
result = dict6.pop('虞书欣')
print(result)
print(dict6)
Python面向对象
定义一个类Animals:
(1)init()定义构造函数,与其他面向对象语言不同的是,Python语言中,会明确地把代表自身实例的self作为第一个参数传入
(2)创建一个实例化对象 cat,init()方法接收参数
(3)使用点号 . 来访问对象的属性。
class Animal:
def __init__(self,name):
self.name = name
print('动物名称实例化')
def eat(self):
print(self.name +'要吃东西啦!')
def drink(self):
print(self.name +'要喝水啦!')
cat = Animal('miaomiao')
print(cat.name)
cat.eat()
cat.drink()
def __init__(self,name):
self.name = name
print ('调用父类构造函数')
def eat(self):
print('调用父类方法')
class Student(Person): # 定义子类
def __init__(self):
print ('调用子类构造方法')
def study(self):
print('调用子类方法')
s = Student() # 实例化子类
s.study() # 调用子类的方法
s.eat() # 调用父类方法
Python JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。
json.dumps 用于将 Python 对象编码成 JSON 字符串。
import json
data = [ {
'b' : 2, 'd' : 4, 'a' : 1, 'c' : 3, 'e' : 5 } ]
json = json.dumps(data)
print(json)
#[{"b": 2, "d": 4, "a": 1, "c": 3, "e": 5}]
为了提高可读性,dumps方法提供了一些可选的参数。
sort_keys=True表示按照字典排序(a到z)输出。
indent参数,代表缩进的位数
separators参数的作用是去掉,和:后面的空格,传输过程中数据越精简越好
import json
data = [ {
'b' : 2, 'd' : 4, 'a' : 1, 'c' : 3, 'e' : 5 } ]
json = json.dumps(data, sort_keys=True, indent=4,separators=(',', ':'))
print(json)
/*[
{
"a":1,
"b":2,
"c":3,
"d":4,
"e":5
}
]**/
json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}'
text = json.loads(jsonData) #将string转换为dict
print(text)
Python异常处理
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理
try:
fh = open("/home/aistudio/data/testfile01.txt", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print('Error: 没有找到文件或读取文件失败')
else:
print ('内容写入文件成功')
fh.close()
finally中的内容,退出try时总会执行
try:
f = open("/home/aistudio/data/testfile02.txt", "w")
f.write("这是一个测试文件,用于测试异常!!")
finally:
print('关闭文件')
f.close()
第二天的作业
1.完成《青春有你2》选手图片爬取,将爬取图片进行保存
2.打印爬取的所有图片的绝对路径,以及爬取的图片总数
好吧,作业所涉及的内容也是老师上课没有讲到的——网络爬虫。网络爬虫呢是深度学习里至关重要的一步,深度学习需要大量的数据,网络爬虫可以很快的获得我们需要的这些数据。这里介绍一下基本的网络爬虫:
网络爬虫小讲:
爬虫的基本流程
参考文档
介绍一下爬虫最常用的两个模块
request模块:
requests是python实现的简单易用的HTTP库,官网地址:http://cn.python-requests.org/zh_CN/latest/
requests.get(url)可以发送一个http get请求,返回服务器响应内容——网页的源码啦。
BeautifulSoup库:
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库。网址:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml。
BeautifulSoup(markup, “html.parser”)或者BeautifulSoup(markup, “lxml”),推荐使用lxml作为解析器,因为效率更高。markup就是获取的网页代码。这样就能得到一个BeautifulSoup对象,我们通过这个漂亮的对象找网页里东西就非常方便啦。
漂亮的对象包含一下五种元素
这里我们就简单使用一下
print('a标签类型是:', type(soup.a)) # 查看a标签的类型
print('第一个a标签的属性是:', soup.a.attrs) # 获取a标签的所有属性(注意到格式是字典)
print('a标签属性的类型是:', type(soup.a.attrs)) # 查看a标签属性的类型
print('a标签的class属性是:', soup.a.attrs['class']) # 因为是字典,通过字典的方式获取a标签的class属性
print('a标签的href属性是:', soup.a.attrs['href']) # 同样,通过字典的方式获取a标签的href属性
还有两个个常用的方法是find和find_all.
*find()返回的是第一个匹配的标签结果
*find_all()返回的是所有匹配结果的列表
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
一般只用前2个参数:tag,attributes。
tag是html标签,如a,p,span,div等
attributes:标签的属性如:.findAll(“span”, {“class”: “green”})
作业遇到的小问题:
1.一开始只在选手界面进行图片获取,导致爬取到的图片很少。而且不都是选手的照片。
其实得点进最右边选择的照片里才能知获取很多选手的照片。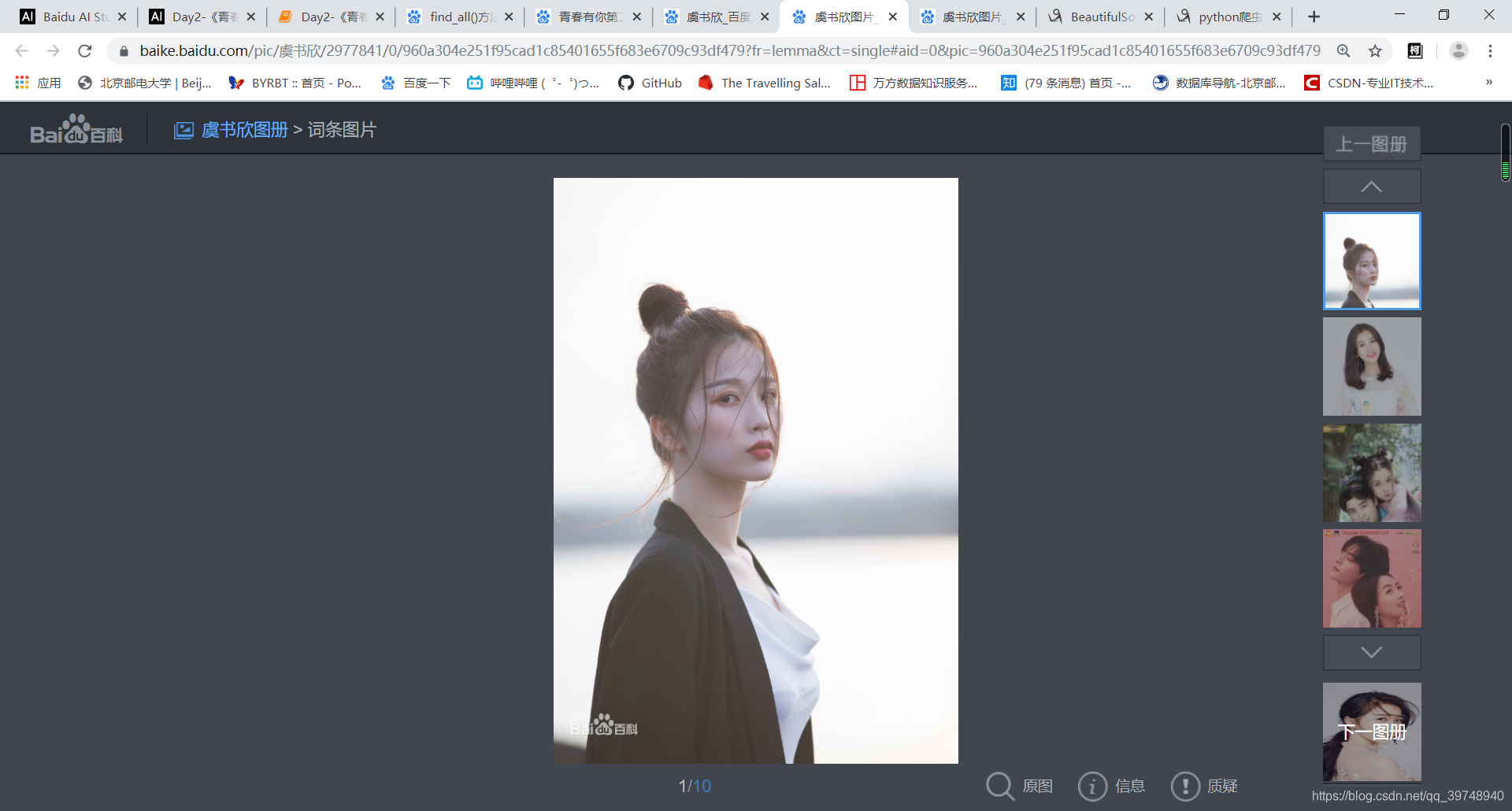
好啦,以上就是今天的全部内容啦,觉得总结的好的同学求点赞,遇到问题或者觉得我哪里没写对的同学欢迎评论或者私聊。那么明天见啦。