深度学习常用Python库介绍
简介
Python被大量应用在数据挖掘和深度学习领域,其中使用极其广泛的是Numpy、pandas、Matplotlib、PIL等库。

numpy(Numerical Python的简称)是高性能科学计算和数据分析的基础包,是Python科学计算库的基础。包含了强大的N维数组对象和向量运算,主要用于矩阵运算。
pandas是建立在numpy基础上的高效数据分析处理库,是Python的重要数据分析库。
Matplotlib是一个主要用于绘制二维图形的Python库,由各种可视化类构成,内部结构复杂的可视化基础包。用途:绘图、可视化
PIL库是一个具有强大图像处理能力的第三方库。用途:图像处理

推荐链接1.:baidu AI Studio - 一站式AI开发实训平台:https://aistudio.baidu.com/aistudio/index
推荐链接2:飞桨PaddlePaddle - 源于产业实践的开源深度学习平台:https://www.paddlepaddle.org.cn/
推荐链接3:百度AI开放平台:https://ai.baidu.com/productlis
Numpy库
NumPy是使用Python进行科学计算的基础软件包。更多学习,可参考numpy中文网:https://www.numpy.org.cn/
1.数组创建与查看数组基本信息
(1)可以使用array函数从常规Python列表或元组中创建数组。得到的数组的类型是从Python列表中元素的类型推导出来的。
创建数组最简单的办法就是使用array函数。它接受一切序列型的对象(包括其他数组),然后产生一个新的含有传入数据的numpy数组。其中,嵌套序列(比如由一组等长列表组成的列表)将会被转换为一个多维数组
import numpy as np
#将列表转换为数组
array = np.array([[1,2,3],
[4,5,6]])
print(array)
[[1 2 3]
[4 5 6]]
import numpy as np
#将元组转换为数组
array = np.array(((1,2,3),
(4,5,6)))
print(array)
[[1 2 3]
[4 5 6]]
错误示例:
a = np.array(1,2,3,4) #因为这个不是列表也不是元组
ValueError: only 2 non-keyword arguments accepted
(2)通常,数组的元素最初是未知的,但它的大小是已知的。因此,NumPy提供了几个函数来创建具有初始占位符内容的数组。
zeros():可以创建指定长度或者形状的全0数组
ones():可以创建指定长度或者形状的全1数组
empty():创建一个数组,其初始内容是随机的,取决于内存的状态
zeroarray = np.zeros((2,3))
print(zeroarray)
[[0. 0. 0.]
[0. 0. 0.]]
onearray = np.ones((3,4),dtype='int64')
print(onearray)
[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]
emptyarray = np.empty((3,4))
print(emptyarray)#里面的每个元素都是随机生成3
[[6.93129723e-310 4.68616485e-310 0.00000000e+000 4.79243676e-322]
[4.68616490e-310 6.93129723e-310 6.93125436e-310 4.68616371e-310]
[4.68616372e-310 6.93126581e-310 1.38338381e-322 6.93129741e-310]]
(3)为了创建数字组成的数组,NumPy提供了一个类似于range的函数,该函数返回数组而不是列表。
array = np.arange( 10, 31, 5 )
print(array)
[10 15 20 25 30]
(4)输出数组的一些信息,如维度、形状、元素个数、元素类型等
array = np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]])
print(array)
#数组维度
print(array.ndim)
#数组形状
print(array.shape)
#数组元素个数
print(array.size)
#数组元素类型
print(array.dtype)
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
2
(4, 3)
12
int64
(5)重新定义数字的形状
array1 = np.arange(6).reshape([2,3])#0-5,只有一个数默认步长为1
print(array1)
array2 = np.array([[1,2,3],[4,5,6]],dtype=np.int64).reshape([3,2])
print(array2)
[[0 1 2]
[3 4 5]]
[[1 2]
[3 4]
[5 6]]
2.数组的计算
数组很重要,因为它可以使我们不用编写循环即可对数据执行批量运算。这通常叫做矢量化(vectorization)。
大小相等的数组之间的任何算术运算都会将运算应用到元素级。同样,数组与标量的算术运算也会将那个标量值传播到各个元素.
(1)矩阵的基础运算:
arr1 = np.array([[1,2,3],[4,5,6]])
arr2 = np.ones([2,3],dtype=np.int64)
print(arr1 + arr2)
print(arr1 - arr2)
print(arr1 * arr2)
print(arr1 / arr2)
print(arr1 ** 2)
[[2 3 4]
[5 6 7]]
[[0 1 2]
[3 4 5]]
[[1 2 3]
[4 5 6]]
[[1. 2. 3.]
[4. 5. 6.]]
[[ 1 4 9]
[16 25 36]]
(2) 矩阵乘法:
#矩阵乘法
arr3 = np.array([[1,2,3],[4,5,6]])
arr4 = np.ones([3,2],dtype=np.int64)
print(arr3)
print(arr4)
print(np.dot(arr3,arr4))
[[1 2 3]
[4 5 6]]
[[1 1]
[1 1]
[1 1]]
[[ 6 6]
[15 15]]
(3) 矩阵的其他计算:
print(arr3)
print(np.sum(arr3,axis=1)) #axis=1,每一行求和 axie=0,每一列求和
print(np.max(arr3))
print(np.min(arr3))
print(np.mean(arr3))
print(np.argmax(arr3))
print(np.argmin(arr3))
[[1 2 3]
[4 5 6]]
[ 6 15]
6
1
3.5
5
0
arr3_tran = arr3.transpose()
print(arr3_tran)
print(arr3.flatten())
[[1 4]
[2 5]
[3 6]]
[1 2 3 4 5 6]
3.数组的索引与切片
arr5 = np.arange(0,6).reshape([2,3])
print(arr5)
print(arr5[1])
print(arr5[1][2])
print(arr5[1,2])
print(arr5[1,:])
print(arr5[:,1])
print(arr5[1,0:2])
[[0 1 2]
[3 4 5]]
[3 4 5]
5
5
[3 4 5]
[1 4]
[3 4]
padas库
pandas是python第三方库,提供高性能易用数据类型和分析工具。
pandas基于numpy实现,常与numpy和matplotlib一同使用
更多学习,请参考pandas中文网:https://www.pypandas.cn/

1.Series
(1)Series是一种类似于一维数组的对象,它由一维数组(各种numpy数据类型)以及一组与之相关的数据标签(即索引)组成.
可理解为带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。
import pandas as pd
import numpy as np
s = pd.Series(['a','b','c','d','e'])
print(s)
0 a
1 b
2 c
3 d
4 e
dtype: object
(2)Seris中可以使用index设置索引列表。与字典不同的是,Seris允许索引重复:
#与字典不同的是:Series允许索引重复
s = pd.Series(['a','b','c','d','e'],index=[100,200,100,400,500])
print(s)
100 a
200 b
100 c
400 d
500 e
dtype: object
(3)Series 可以用字典实例化:
d = {'b': 1, 'a': 0, 'c': 2}
pd.Series(d)
b 1
a 0
c 2
dtype: int64
(4)可以通过Series的values和index属性获取其数组表示形式和索引对象:
print(s.values)
print(s.index)
[1 2 3 4 5]
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
#与普通numpy数组相比,可以通过索引的方式选取Series中的单个或一组值
print(s[100])
print(s[[400, 500]])
100 a
100 c
dtype: object
400 d
500 e
dtype: object
s = pd.Series(np.array([1,2,3,4,5]), index=['a', 'b', 'c', 'd', 'e'])
print(s)
#对应元素求和
print(s+s)
#对应元素乘
print(s*3)
a 1
b 2
c 3
d 4
e 5
dtype: int64
a 2
b 4
c 6
d 8
e 10
dtype: int64
a 3
b 6
c 9
d 12
e 15
dtype: int64
(5)Series中最重要的一个功能是:它会在算术运算中自动对齐不同索引的数据。因此,Series 和多维数组的主要区别在于, Series 之间的操作会自动基于标签对齐数据。因此,不用顾及执行计算操作的 Series 是否有相同的标签。
obj1 = pd.Series({"Ohio": 35000, "Oregon": 16000, "Texas": 71000, "Utah": 5000})
obj2 = pd.Series({"California": np.nan, "Ohio": 35000, "Oregon": 16000, "Texas": 71000})
print(obj1 + obj2)
California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN
dtype: float64
s = pd.Series(np.array([1,2,3,4,5]), index=['a', 'b', 'c', 'd', 'e'])
print(s[1:])
print(s[:-1])
print(s[1:] + s[:-1])
b 2
c 3
d 4
e 5
dtype: int64
a 1
b 2
c 3
d 4
dtype: int64
a NaN
b 4.0
c 6.0
d 8.0
e NaN
2.DataFrame
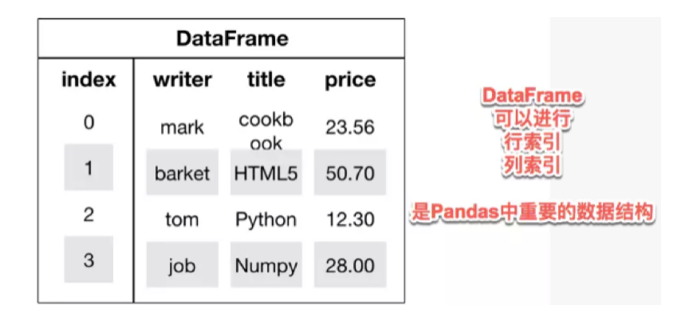
DataFrame是一个表格型的数据结构,类似于Excel或sql表,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等),DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
(1)用多维数组字典、列表字典生成 DataFrame:
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], 'year': [2000, 2001, 2002, 2001, 2002], 'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = pd.DataFrame(data)
print(frame)
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
#如果指定了列顺序,则DataFrame的列就会按照指定顺序进行排列
frame1 = pd.DataFrame(data, columns=['year', 'state', 'pop'])
print(frame1)
year state pop
0 2000 Ohio 1.5
1 2001 Ohio 1.7
2 2002 Ohio 3.6
3 2001 Nevada 2.4
4 2002 Nevada 2.9
(2)跟原Series一样,如果传入的列在数据中找不到,就会产生NAN值:
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five'])
print(frame2)
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
(3)用 Series 字典或字典生成 DataFrame:
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
print(pd.DataFrame(d))
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
#通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series,返回的Series拥有原DataFrame相同的索引
print(frame2['state'])
one Ohio
two Ohio
three Ohio
four Nevada
five Nevada
Name: state, dtype: object
(4)列可以通过赋值的方式进行修改,例如,给那个空的“delt”列赋上一个标量值或一组值:
frame2['debt'] = 16.5
print(frame2)
year state pop debt
one 2000 Ohio 1.5 16.5
two 2001 Ohio 1.7 16.5
three 2002 Ohio 3.6 16.5
four 2001 Nevada 2.4 16.5
five 2002 Nevada 2.9 16.5
print(frame2)
frame2['new'] = frame2['debt' ]* frame2['pop']
print(frame2)
year state pop debt
one 2000 Ohio 1.5 16.5
two 2001 Ohio 1.7 16.5
three 2002 Ohio 3.6 16.5
four 2001 Nevada 2.4 16.5
five 2002 Nevada 2.9 16.5
year state pop debt new
one 2000 Ohio 1.5 16.5 24.75
two 2001 Ohio 1.7 16.5 28.05
three 2002 Ohio 3.6 16.5 59.40
four 2001 Nevada 2.4 16.5 39.60
five 2002 Nevada 2.9 16.5 47.85
frame2['debt'] = np.arange(5.)
print(frame2)
year state pop debt new
one 2000 Ohio 1.5 0.0 24.75
two 2001 Ohio 1.7 1.0 28.05
three 2002 Ohio 3.6 2.0 59.40
four 2001 Nevada 2.4 3.0 39.60
five 2002 Nevada 2.9 4.0 47.85
PIL库
PIL库是一个具有强大图像处理能力的第三方库。其中,Image 是 PIL 库中代表一个图像的类(对象)。
图像的组成:由RGB三原色组成,RGB图像中,一种彩色由R、G、B三原色按照比例混合而成。0-255区分不同亮度的颜色。
图像的数组表示:图像是一个由像素组成的矩阵,每个元素是一个RGB值。
(1)安装PIL库
#安装pillow
#!pip install pillow
(2) 展示图片,并获取图像的模式,长宽。
from PIL import Image
import matplotlib.pyplot as plt
#显示matplotlib生成的图形
%matplotlib inline
#读取图片
img = Image.open('/home/aistudio/work/yushuxin.jpg')
#显示图片
#img.show() #自动调用计算机上显示图片的工具
plt.imshow(img)
plt.show(img)
#获得图像的模式
img_mode = img.mode
print(img_mode)
width,height = img.size
print(width,height)
输出:

(3)图片旋转
from PIL import Image
import matplotlib.pyplot as plt
#显示matplotlib生成的图形
%matplotlib inline
#读取图片
img = Image.open('/home/aistudio/work/yushuxin.jpg')
#显示图片
plt.imshow(img)
plt.show(img)
#将图片旋转45度
img_rotate = img.rotate(45)
#显示旋转后的图片
plt.imshow(img_rotate)
plt.show(img_rotate)
输出:

(4)图片剪切
from PIL import Image
#打开图片
img1 = Image.open('/home/aistudio/work/yushuxin.jpg')
#剪切 crop()四个参数分别是:(左上角点的x坐标,左上角点的y坐标,右下角点的x坐标,右下角点的y坐标)
img1_crop_result = img1.crop((126,0,381,249))
#保存图片
img1_crop_result.save('/home/aistudio/work/yushuxin_crop_result.jpg')
#展示图片
plt.imshow(img1_crop_result)
plt.show(img1_crop_result)
输出:

(5)图片缩放
from PIL import Image
#打开图片
img2 = Image.open('/home/aistudio/work/yushuxin.jpg')
width,height = img2.size
#缩放
img2_resize_result = img2.resize((int(width*0.6),int(height*0.6)),Image.ANTIALIAS)
print(img2_resize_result.size)
#保存图片
img2_resize_result.save('/home/aistudio/work/yushuxin_resize_result.jpg')
#展示图片
plt.imshow(img2_resize_result)
plt.show(img2_resize_result)
输出:

(6)镜像效果:左右旋转、上下旋转
from PIL import Image
#打开图片
img3 = Image.open('/home/aistudio/work/yushuxin.jpg')
#左右镜像
img3_lr = img3.transpose(Image.FLIP_LEFT_RIGHT)
#展示左右镜像图片
plt.imshow(img3_lr)
plt.show(img3_lr)
#上下镜像
img3_bt = img3.transpose(Image.FLIP_TOP_BOTTOM)
#展示上下镜像图片
plt.imshow(img3_bt)
plt.show(img3_bt)
输出:

Matplotlib库
Matplotlib库由各种可视化类构成,内部结构复杂。其中,matplotlib.pylot是绘制各类可视化图形的命令字库。
更多学习,可参考Matplotlib中文网:https://www.matplotlib.org.cn
(1)安装
#!pip install matplotlib
(2)生成单个函数图像
import matplotlib.pyplot as plt
import numpy as np
#显示matplotlib生成的图形
%matplotlib inline
x = np.linspace(-1,1,50) #等差数列
y = 2*x + 1
#传入x,y,通过plot()绘制出折线图
plt.plot(x,y)
#显示图形
plt.show()

(3)生成多幅并列的函数图像
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-1,1,50) #等差数列
y1 = 2*x + 1
y2 = x**2
plt.figure()
plt.plot(x,y1)
plt.figure(figsize=(7,5))
plt.plot(x,y2)
plt.show()

(4)在一个画布上绘制多个函数图像
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(7,5))
plt.plot(x,y1,color='red',linewidth=1)
plt.plot(x,y2,color='blue',linewidth=5)
plt.xlabel('x',fontsize=20)
plt.ylabel('y',fontsize=20)
plt.show()

(5)为图像添加图例
import matplotlib.pyplot as plt
import numpy as np
l1, = plt.plot(x,y1,color='red',linewidth=1)
l2, = plt.plot(x,y2,color='blue',linewidth=5)
plt.legend(handles=[l1,l2],labels=['aa','bb'],loc='best')
plt.xlabel('x')
plt.ylabel('y')
# plt.xlim((0,1)) #x轴只截取一段进行显示
# plt.ylim((0,1)) #y轴只截取一段进行显示
plt.show()

(6)绘制散点图
# dots1 = np.array([2,3,4,5,6])
# dots2 = np.array([2,3,4,5,6])
dots1 =np.random.rand(50)
dots2 =np.random.rand(50)
plt.scatter(dots1,dots2,c='red',alpha=0.5) #c表示颜色,alpha表示透明度
plt.show()

(7)绘制直方图
x = np.arange(10)
y = 2**x+10
plt.bar(x,y,facecolor='#9999ff',edgecolor='white')
plt.show()

(8)为直方图添加数据显示
x = np.arange(10)
y = 2**x+10
plt.bar(x,y,facecolor='#9999ff',edgecolor='white')
for ax,ay in zip(x,y):
plt.text(ax,ay,'%.1f' % ay,ha='center',va='bottom')
plt.show()

