PyTorch - 27 - 带PyTorch的CNN Confusion Matrix - 神经网络编程
- Confusion Matrix Requirements
- Get Predictions For The Entire Training Set
- Building A Function To Get Predictions For ALL Samples
- Locally Disabling PyTorch Gradient Tracking
- Using The Predictions Tensor
- Building The Confusion Matrix
- Plotting The Confusion Matrix
- Interpreting The Confusion Matrix
- Conclusion
Confusion Matrix Requirements
我们现在所处的位置。
- 准备数据
- 建立模型
- 训练模型
- 分析模型的结果
a. 建立,绘制和解释混淆矩阵
有关所有代码设置的详细信息,请务必参阅本课程的上一集。

我们将看到如何使用这个预测张量以及每个样本的标签来创建一个混淆矩阵。 这个混淆矩阵将使我们能够看到网络相互混淆的类别。 事不宜迟,让我们开始吧。
要为整个数据集创建一个混淆矩阵,我们需要一个预测张量,该张量的单个维度与训练集的长度相同。
> len(train_set)
60000
对于我们训练集中的每个样本,该预测张量将包含十个预测(每种服装类别一个)。获得此张量后,我们可以使用标签张量生成混淆矩阵。
> len(train_set.targets)
60000
混淆矩阵将向我们显示模型在哪里变得混乱。更具体地说,混淆矩阵将向我们显示模型正确预测的类别和模型错误预测的类别。对于不正确的预测,我们将能够看到模型预测的类别,这将向我们显示哪些类别使模型感到困惑。
Get Predictions For The Entire Training Set
为了获得所有训练集样本的预测,我们需要将所有样本通过网络转发。为此,可以创建一个具有batch_size = 1的DataLoader。这将立即将单个批次传递到网络,并将为我们提供所有训练集样本所需的预测张量。
但是,如果要在不同的数据集上进行训练,则取决于计算资源和训练集的大小,我们需要一种方法来对较小的批次进行预测并收集结果。为了收集结果,我们将使用torch.cat()函数将输出张量连接在一起,以获得单个预测张量。让我们构建一个函数来执行此操作。
Building A Function To Get Predictions For ALL Samples
我们将创建一个名为get_all_preds()的函数,并将传递一个模型和一个数据加载器。该模型将用于获取预测,数据加载器将用于从训练集中提供批次。
所有功能需要做的是遍历数据加载器,将批处理传递到模型,并将每个批处理的结果连接到预测张量,该张量将返回给调用方。
@torch.no_grad()
def get_all_preds(model, loader):
all_preds = torch.tensor([])
for batch in loader:
images, labels = batch
preds = model(images)
all_preds = torch.cat(
(all_preds, preds)
,dim=0
)
return all_preds
此函数的植入会创建一个空张量all_preds来保存输出预测。然后,迭代来自数据加载器的批处理,并将输出预测与all_preds张量连接在一起。最后,所有预测all_preds被返回给调用者。
请注意,在顶部,我们已使用@ torch.no_grad()PyTorch装饰对函数进行了注释。这是因为我们希望此函数执行省略梯度跟踪。
这是因为梯度跟踪使用内存,并且在推理(在不训练的情况下获得预测)期间,无需跟踪计算图。 装饰是在执行特定功能时局部关闭渐变跟踪功能的一种方法。
Locally Disabling PyTorch Gradient Tracking
我们现在准备打电话来获取训练集的预测。 我们需要做的就是创建一个具有合理批处理大小的数据加载器,并将模型和数据加载器传递给get_all_preds()函数。

在上一集中,我们了解了在不需要时如何使用PyTorch的渐变跟踪功能,并在开始训练过程时将其重新打开。
每当我们要使用向后()函数来计算梯度时,我们特别需要梯度计算功能。 否则,将其关闭是一个好主意,因为将其关闭会减少计算的内存消耗,例如 当我们使用网络进行预测(推理)时。

我们可以在代码中针对特定或局部斑点禁用梯度计算,例如 就像我们刚刚看到的带注释功能一样。 再举一个例子,我们可以使用带有上下文管理器关键字的Python来指定指定的代码块应不包括梯度计算。
with torch.no_grad():
prediction_loader = torch.utils.data.DataLoader(train_set, batch_size=10000)
train_preds = get_all_preds(network, prediction_loader)
这两个选项均有效。 让我们保留所有这些并获得我们的预测。
Using The Predictions Tensor
现在,有了预测张量,我们可以将其传递给我们在上一集中创建的get_num_correct()函数以及训练集标签,以获取正确预测的总数。
> preds_correct = get_num_correct(train_preds, train_set.targets)
> print('total correct:', preds_correct)
> print('accuracy:', preds_correct / len(train_set))
total correct: 53578
accuracy: 0.8929666666666667
我们可以看到正确预测的总数,并通过除以训练集中的样本数来打印准确性。
Building The Confusion Matrix
我们建立混淆矩阵的任务是将预测值的数量与真实值(目标)进行比较。
这将创建一个充当热图的矩阵,告诉我们预测值相对于真实值的下降位置。
为此,我们需要具有目标张量和train_preds张量中的预测标签。
> train_set.targets
tensor([9, 0, 0, ..., 3, 0, 5])
> train_preds.argmax(dim=1)
tensor([9, 0, 0, ..., 3, 0, 5])
现在,如果我们逐元素比较两个张量,我们可以看到预测的标签是否与目标匹配。此外,如果我们要计算预测标签与目标标签的数量,则两个张量内的值将作为矩阵的坐标。让我们沿着第二维堆叠这两个张量,以便我们可以有60,000个有序对。
> stacked = torch.stack(
(
train_set.targets
,train_preds.argmax(dim=1)
)
,dim=1
)
> stacked.shape
torch.Size([60000, 2])
> stacked
tensor([
[9, 9],
[0, 0],
[0, 0],
...,
[3, 3],
[0, 0],
[5, 5]
])
> stacked[0].tolist()
[9, 9]
现在,我们可以遍历这些对,并计算矩阵中每个位置的出现次数。让我们创建矩阵。由于我们有十个预测类别,因此将有一个十乘十的矩阵。检查此处以了解stack()函数。
> cmt = torch.zeros(10,10, dtype=torch.int64)
> cmt
tensor([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
现在,我们将遍历预测目标对,并在每次发生特定位置时向矩阵内的值添加一个。
for p in stacked:
tl, pl = p.tolist()
cmt[tl, pl] = cmt[tl, pl] + 1
这为我们提供了以下混淆矩阵张量。
> cmt
tensor([
[5637, 3, 96, 75, 20, 10, 86, 0, 73, 0],
[ 40, 5843, 3, 75, 16, 8, 5, 0, 10, 0],
[ 87, 4, 4500, 70, 1069, 8, 156, 0, 106, 0],
[ 339, 61, 19, 5269, 203, 10, 72, 2, 25, 0],
[ 23, 9, 263, 209, 5217, 2, 238, 0, 39, 0],
[ 0, 0, 0, 1, 0, 5604, 0, 333, 13, 49],
[1827, 7, 716, 104, 792, 3, 2370, 0, 181, 0],
[ 0, 0, 0, 0, 0, 22, 0, 5867, 4, 107],
[ 32, 1, 13, 15, 19, 5, 17, 11, 5887, 0],
[ 0, 0, 0, 0, 0, 28, 0, 234, 6, 5732]
])
请注意,下面的示例将具有不同的值,因为这两个示例是在不同的时间创建的。
Plotting The Confusion Matrix
为了将实际的混淆矩阵生成为numpy.ndarray,我们使用sklearn.metrics库中的confusion_matrix()函数。让我们将其与其他需要的导入一起导入。
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from resources.plotcm import plot_confusion_matrix
对于最后一次导入,请注意plotcm是一个文件plotcm.py,位于当前目录中一个名为resources的文件夹中。在plotcm.py文件中,有一个称为plot_confusion_matrix()的函数,我们将调用该函数。您将需要在系统上实现此功能。我们将在稍后讨论如何执行此操作。首先,让我们生成混淆矩阵。
我们可以像这样生成混淆矩阵:
> cm = confusion_matrix(train_set.targets, train_preds.argmax(dim=1))
> print(type(cm))
> cm
<class 'numpy.ndarray'>
Out[74]:
array([[5431, 14, 88, 145, 26, 7, 241, 0, 48, 0],
[ 4, 5896, 6, 75, 8, 0, 8, 0, 3, 0],
[ 92, 6, 5002, 76, 565, 1, 232, 1, 25, 0],
[ 191, 49, 23, 5504, 162, 1, 61, 0, 7, 2],
[ 15, 12, 267, 213, 5305, 1, 168, 0, 19, 0],
[ 0, 0, 0, 0, 0, 5847, 0, 112, 3, 38],
[1159, 16, 523, 189, 676, 0, 3396, 0, 41, 0],
[ 0, 0, 0, 0, 0, 99, 0, 5540, 0, 361],
[ 28, 6, 29, 15, 32, 23, 26, 14, 5827, 0],
[ 0, 0, 0, 0, 1, 61, 0, 107, 1, 5830]],
dtype=int64)
PyTorch张量是类似数组的Python对象,因此我们可以将它们直接传递给confusion_matrix()函数。我们针对train_preds张量的第一维传递训练集标签张量(目标)和argmax,这给了我们混淆矩阵数据结构。
要实际绘制混淆矩阵,我们需要一些自定义代码,这些代码已放入名为plotcm的本地文件中。该函数称为plot_confusion_matrix()。 plotcm.py文件需要包含以下内容,并且位于当前目录的resources文件夹中。
请注意,您也可以只将此代码复制到笔记本中,或者避免导入。
plotcm.py:
import itertools
import numpy as np
import matplotlib.pyplot as plt
def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues):
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt), horizontalalignment="center", color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
资料来源-scikit-learn.org
对于导入,我们这样做:
from plotcm import plot_confusion_matrix
我们已经准备好绘制混淆矩阵,但是首先我们需要创建一个预测类名称列表,以传递给plot_confusion_matrix()函数。下表给出了我们的预测类及其相应的索引:
| 索引 | 标签 |
|---|---|
| 0 | T恤/上衣 |
| 1 | 裤子 |
| 2 | 头衫 |
| 3 | 礼服 |
| 4 | 外套 |
| 5 | 凉鞋 |
| 6 | 衬衫 |
| 7 | 运动鞋 |
| 8 | 包 |
| 9 | 踝靴 |

这使我们可以调用以绘制矩阵:
> plt.figure(figsize=(10,10))
> plot_confusion_matrix(cm, train_set.classes)
Confusion matrix, without normalization
[[5431 14 88 145 26 7 241 0 48 0]
[ 4 5896 6 75 8 0 8 0 3 0]
[ 92 6 5002 76 565 1 232 1 25 0]
[ 191 49 23 5504 162 1 61 0 7 2]
[ 15 12 267 213 5305 1 168 0 19 0]
[ 0 0 0 0 0 5847 0 112 3 38]
[1159 16 523 189 676 0 3396 0 41 0]
[ 0 0 0 0 0 99 0 5540 0 361]
[ 28 6 29 15 32 23 26 14 5827 0]
[ 0 0 0 0 1 61 0 107 1 5830]]
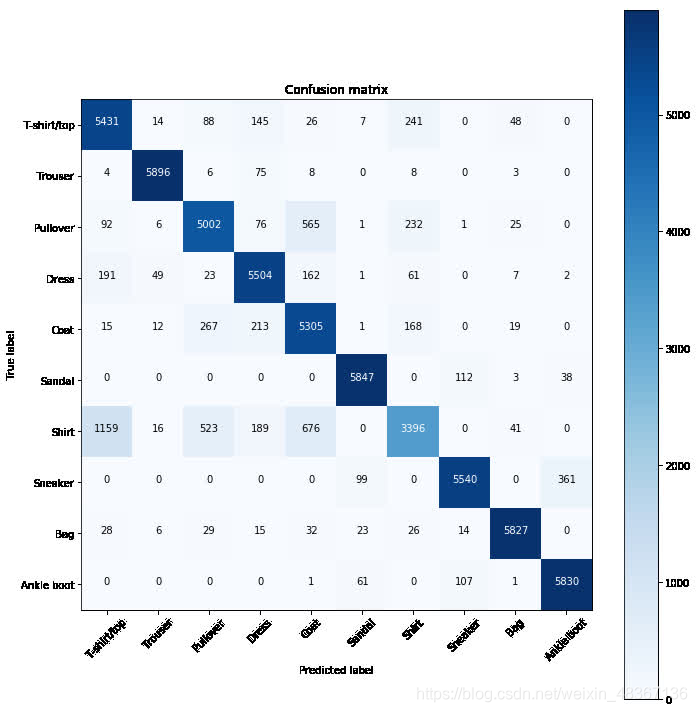
Interpreting The Confusion Matrix
混淆矩阵具有三个轴:
- 预测标签(类)
- 真实标签
- 热图值(彩色)
预测标签和真实标签向我们显示了我们正在处理的预测类。矩阵对角线表示矩阵中预测和真值相同的位置,因此这是我们希望热图更暗的位置。
任何不在对角线上的值都是不正确的预测,因为预测和真实标签不匹配。要读取该图,我们可以使用以下步骤:
- 在水平轴上选择一个预测标签。
- 检查该标签的对角线位置以查看正确的总数。
- 检查其他非对角线位置以查看网络混乱之处。
例如,网络正在将T恤/上衣与衬衫混淆,但并未将T恤/上衣与以下东西混淆:
- 脚踝靴
- 运动鞋
- 凉鞋
如果我们考虑一下,这很有意义。随着我们模型的学习,我们将看到对角线之外的数字越来越小。
Conclusion
在本系列的这一点上,我们已经完成了许多在PyTorch中构建和训练CNN的工作。恭喜!