混淆矩阵
在机器学习领域中,混淆矩阵(confusion matrix)是一种评价分类模型好坏的形象化展示工具。其中,矩阵的每一列表示的是模型预测的样本情况;矩阵的每一行表示的样本的真实情况。
举个经典的二分类例子:
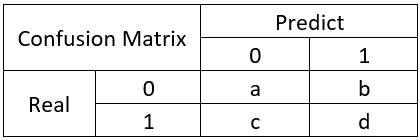
混淆矩阵是除了ROC曲线和AUC之外的另一个判断分类好坏程度的方法,通过混淆矩阵我们可以很清楚的看出每一类样本的识别正误情况。
混淆矩阵比模型的精度的评价指标更能够详细地反映出模型的”好坏”。模型的精度指标,在正负样本数量不均衡的情况下,会出现容易误导的结果。
基本概念
【1】 True Positive
真正类(TP),样本的真实类别是正类,并且模型识别的结果也是正类。
【2】False Negative
假负类(FN),样本的真实类别是正类,但是模型将其识别成为负类。
【3】 False Positive
假正类(FP),样本的真实类别是负类,但是模型将其识别成为正类。
【4】True Negative
真负类(TN),样本的真实类别是负类,并且模型将其识别成为负类。
评价指标
【1】Accuracy(正确率)
模型的精度,即模型识别正确的个数 / 样本的总个数 。一般情况下,模型的精度越高,说明模型的效果越好。
【2】Precision(准确率)
=查准率 ,在模型识别为正类的样本中,真正为正类的样本所占的比例。 一般情况下,查准率越高,说明模型的效果越好。
关于Accuracy(正确率)和Precision(准确率)的区别:
分类正确率(Accuracy),不管是哪个类别,只要预测正确,其数量都放在分子上,而分母是全部数据数量,这说明正确率是对全部数据的判断。
而准确率在分类中对应的是某个类别,分子是预测该类别正确的数量,分母是预测为该类别的全部数据的数量。
或者说,Accuracy是对分类器整体上的正确率的评价,而Precision是分类器预测为某一个类别的正确率的评价。
【3】Recall(召回率)
=查全率,表示的是,模型识别为正类的样本的数量,占总的正类样本数量的比值。 一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。
【4】Specificity
表示的是,模型识别为负类的样本的数量,占总的负类样本数量的比值。
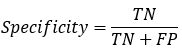
【5】Fβ_Score
准确率和召回率的调和平均,比较常用的是F1。
【6】F1_Score
β=1的情况,F1-Score的值是从0到1的,1是最好,0是最差