一、linux调度算法
CFS调度器Completely Fair Scheduler. 这个也是在2.6内核中引入的,具体为2.6.23,即从此版本开始,内核使用CFS作为它的默认调度器。CFS它不计算优先级,而是通过计算进程消耗的CPU时间(标准化以后的虚拟CPU时间)来确定谁来调度。从而到达所谓的公平性。
-
绝对公平性:
cfs定义了一种新的模型,其基本思路很简单,他把CPU当做一种资源,并记录下每一个进程对该资源使用的情况,在调度时,调度器总是选择消耗资源最少的进程来运行。这就是所谓的“完全公平”。但这种绝对的公平有时也是一种不公平,因为有些进程的工作比其他进程更重要,我们希望能按照权重来分配CPU资源。 -
相对公平性:
为了区别不同优先级的进程,就是会根据各个进程的权重分配运行时间。进程的运行时间计算公式为:分配给进程的运行时间 = 调度周期 * 进程权重 / 所有进程权重之和。
实现原理:
每个CPU都有一个运行队列cfs_rq(里面是就绪状态的进程),Linux采用了一颗红黑树(对于多核调度,实际上每一个核有一个自己的红黑树),记录下每一个进程的vruntime,需要调度时,从红黑树中选取一个vruntime最小的进程出来运行。具体的,我们来看下从实际运行时间到vruntime的换算公式
vruntime = 实际运行时间 * 1024 / 进程权重 。
权重: 对每一个进程,有一个整型static_prio表示用户设置的静态优先级,内核里它与nice值是对应的。权重由nice值确定,具体的,权重跟进程nice值之间有一一对应的关系,nice可以由内核动态调整。
//nice值共有40个,与权重之间,每一个nice值相差10%左右。
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
vruntime: 实际上vruntime就是根据权重将实际运行时间标准化,标准化之后,各个进程对资源的消耗情况就可以直接通过比较vruntime来知道,比如某个进程的vruntime比较小,我们就可以知道这个进程消耗CPU资源比较少,反之消耗CPU资源就比较多。有了vruntime的概念后,调度算法就非常简单了,谁的vruntime值较小就说明它以前占用cpu的时间较短,受到了“不公平”对待,因此下一个运行进程就是它。这样既能公平选择进程,又能保证高优先级进程获得较多的运行时间。这就是CFS的主要思想了。或者可以这么理解:CFS的思想就是让每个调度实体(分组调度的情形下就是进程,以后就说进程了)的vruntime互相追赶,而每个调度实体的vruntime增加速度不同,权重越大的增加的越慢,这样就能获得更多的cpu执行时间。具体实现上,Linux采用了一颗红黑树(对于多核调度,实际上每一个核有一个自己的红黑树),记录下每一个进程的vruntime,需要调度时,从红黑树中选取一个vruntime最小的进程出来运行。

-
在休眠进程被唤醒时重新设置vruntime值,以min_vruntime值为基础,给予一定的补偿,但不能补偿太多。
-
CFS的唤醒抢占 特性决定的,即sched_features的WAKEUP_PREEMPT位。由于休眠进程在唤醒时会获得vruntime的补偿,所以它在醒来的时候有能力抢占CPU是大概率事件,这也是CFS调度算法的本意,即保证交互式进程的响应速度,因为交互式进程等待用户输入会频繁休眠。除了交互式进程以外,主动休眠的进程同样也会在唤醒时获得补偿,例如通过调用sleep()、nanosleep()的方式,定时醒来完成特定任务,这类进程往往并不要求快速响应,但是CFS不会把它们与交互式进程区分开来,它们同样也会在每次唤醒时获得vruntime补偿,这有可能会导致其它更重要的应用进程被抢占,有损整体性能。禁用唤醒抢占 特性之后,刚唤醒的进程不会立即抢占运行中的进程,而是要等到运行进程用完时间片之后。
-
为了避免过于短暂的进程切换造成太大的消耗,CFS设定了进程占用CPU的最小时间值,sched_min_granularity_ns,正在CPU上运行的进程如果不足这个时间是不可以被调离CPU的。
-
在多CPU的系统上,不同的CPU的负载不一样,有的CPU更忙一些,而每个CPU都有自己的运行队列,每个队列中的进程的vruntime也走得有快有慢,比如我们对比每个运行队列的min_vruntime值,都会有不同:如果一个进程从min_vruntime更小的CPU (A) 上迁移到min_vruntime更大的CPU (B) 上,可能就会占便宜了,因为CPU (B) 的运行队列中进程的vruntime普遍比较大,迁移过来的进程就会获得更多的CPU时间片。这显然不太公平。CFS是这样做的:
- 当进程从一个CPU的运行队列中出来 (dequeue_entity) 的时候, 它的vruntime要减去队列的min_vruntime值;
- 而当进程加入另一个CPU的运行队列 ( enqueue_entiry) 时,它的vruntime要加上该队列的min_vruntime值。
-
假如新进程的vruntime初值为0的话,比老进程的值小很多,那么它在相当长的时间内都会保持抢占CPU的优势,老进程就要饿死了,这显然是不公平的。CFS是这样做的: 每个CPU的运行队列cfs_rq都维护一个min_vruntime字段,记录该运行队列中所有进程的vruntime最小值,新进程的初始vruntime值就以它所在运行队列的min_vruntime为基础来设置,与老进程保持在合理的差距范围内。
新进程的vruntime初值的设置与两个参数有关:
sched_child_runs_first:规定fork之后让子进程先于父进程运行;
sched_features的START_DEBIT位:规定新进程的第一次运行要有延迟。
二、windows调度算法
windows调度单位是线程, 采用基于动态优先级的、抢占式调度,结合时间配额的调整。
- 就绪线程按优先级进入相应队列
- 系统总是选择优先级最高的就绪线程运行
- 同一优先级的各线程按时间片轮转进行调度
- 多CPU系统中允许多个线程并行运行
优先级: Windows内核使用32个优先级分别来表示线程要求执行的紧迫性,用0~31的数字表示。根据优先级的功能不同,可以分为3组:16个实时优先级别(16~31),15个可变优先级(1~15),1个系统优先级(0),为内存页清零线程保留。

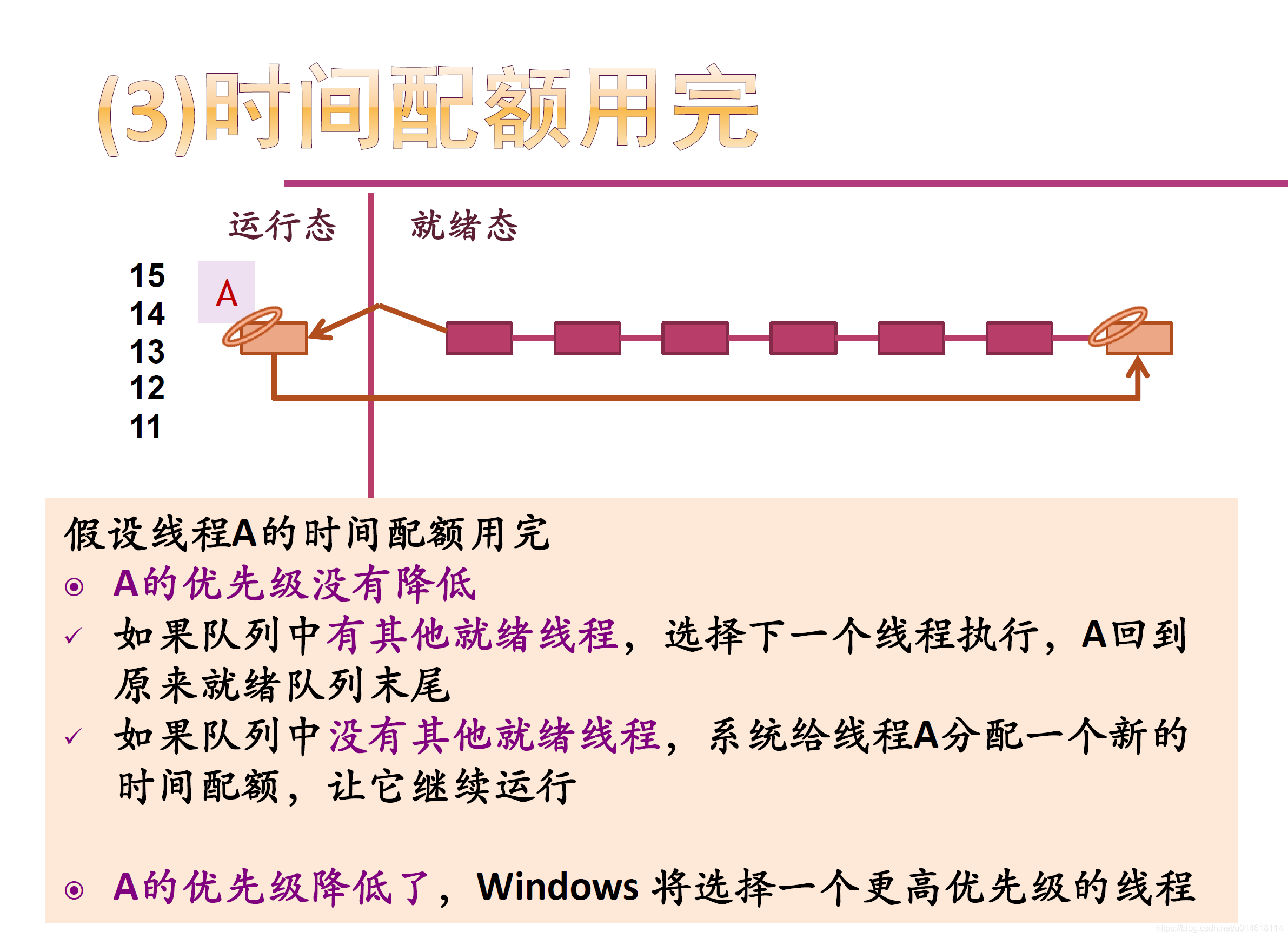
时间配额: 时间配额不是一个时间长度值,而一个称为配额单位(quantum unit)的整数 。一个线程用完了自己的时间配额时,如果没有其他相同优先级的线程,Windows将重新给该线程分配一个新的时间配额,让它继续运行 。
引发线程调度的条件:
- 一个线程的优先级改变了
- 一个线程改变了它的亲和(Affinity)处理机集合
下列5种情况,Windows 会提升线程的当前优先级:
- I/O操作完成
- 信号量或事件等待结束
- 前台进程中的线程完成一个等待操作
- 由于窗口活动而唤醒窗口线程
- 线程处于就绪态超过了一定的时间还没有运行 —— “饥饿”现象
调度策略: 主动切换 、抢占 、时间配额用完


三、多核调度之负载均衡
一个程序在运行时,只在一个CPU核上运行?还是交替在多个CPU核上运行呢?Linux内核是如何在多核间调度进程的呢?实际上,如果你没有对你的进程做过特殊处理的话,LINUX内核是有可能把它放到多个CPU处理器上运行的,这是内核的负载均衡。每个处理器上有一个runqueue队列,表示这颗处理器上处于run状态的进程链表,在多处理器的内核中,就会有多个runqueue,而如果他们的大小很不均衡,就会触发内核的load_balance函数。这个函数会把某个CPU处理器上过多的进程移到runqueue元素相对少的CPU处理器上。
什么时候会发生负载均衡呢?
1、当cpu1上的runqueue里一个可运行进程都没有的时候。这点很好理解,cpu1无事可作了,这时在cpu1上会调用load_balance,发现在cpu0上还有许多进程等待运行,那么它会从cpu0上的可运行进程里找到优先级最高的进程,拿到自己的runqueue里开始执行。
2、第1种情形不适用于运行队列一直不为空的情况。例如,cpu0上一直有10个可运行进程,cpu1上一直有1个可运行进程,显然,cpu0上的进程们得到了不公平的对待,它们拿到cpu的时间要小得多,第1种情形下的load_balance也一直不会调用。所以,实际上,每经过一个时钟节拍,内核会调用scheduler_tick函数,而这个函数会做许多事,例如减少当前正在执行的进程的时间片,在函数结尾处则会调用rebalance_tick函数。rebalance_tick函数决定以什么样的频率执行负载均衡。
当idle标志位是SCHED_IDLE时,表示当前CPU处理器空闲,就会以很高的频繁来调用load_balance(1、2个时钟节拍),反之表示当前CPU并不空闲,会以很低的频繁调用load_balance(10-100ms)。具体的数值要看上面的interval了。如果你没有对你的进程做过特殊处理的话,LINUX内核是有可能把它放到多个CPU处理器上运行的,但是,有时我们如果希望我们的进程一直运行在某个CPU处理器上,可以做到吗?内核提供了这样的系统调用。系统调用sched_getaffinity会返回当前进程使用的cpu掩码,而sched_setaffinity则可以设定该进程只能在哪几颗cpu处理器上执行。
四、CPU调度的亲和性
在多核CPU结构中,每个核心有各自的L1、L2缓存,而L3缓存是共用的。如果一个进程在核心间来回切换,各个核心的缓存命中率就会受到影响。相反如果进程不管如何调度,都始终可以在一个核心上执行,那么其数据的L1、L2 缓存的命中率可以显著提高。

在 Linux 系统里,可以使用 CPU_* 系列函数和 sched_setaffinity() 可以实现绑定进程和核心的绑定。