CPU调度
前言
这是操作系统中很重要的一章,出的题型也十分的经典。
CPU调度基本概念
CPU-I/O区间周期
进程执行由CPU执行和I/O等待周期组成,进程在这两个状态之间切换。进程执行从CPU区间开始,在这之后是I/O区间,接着是另一个CPU区间,然后是另一个I/O区间,如此进行下去,直到CPU区间通过系统请求终止执行。
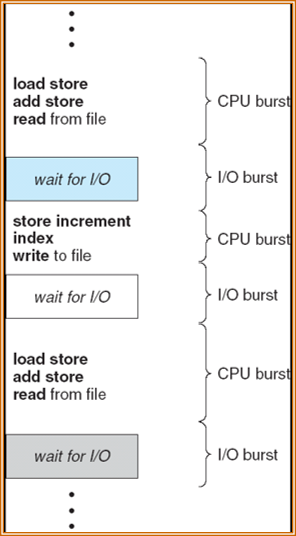
CPU调度程序
CPU调度程序即以前提到过的短期调度程序:调度程序从内存中选择一个能够执行的进程,并为之分配CPU。
这一部分相当于复习呀
就绪队列不必是先进先出队列。正如研究各种调度算法时将看到的,就绪队列可实现为FIFO队列、优先队列、树或简单的无序链表。就绪队列内的所有进程都要排队以等待在CPU上运行。队列中的记录通常为进程控制块(PCB)。
抢占调度
调度方案可以是非抢占的或抢占的。
CPU调度决策可在如下4中环境下发生:
- 当一个进程从运行状态切换到等待状态(I/O请求,或调用wait()等待下一个进程的终止)。
- 当一个进程从运行状态切换到就绪状态(当出现中断时)。
- 当一个进程从等待状态切换到就绪状态(I\O完成)。
- 当一个进程终止时。
当调度发生在第1和第4中情况时,称为非抢占的;当调度发生在第2和第3种情况时,称为抢占的。
分派程序
分派程序: 分派程序是一个模块,用来将CPU的控制交给由短期调度程序选择的进程。
功能:
- 切换上下文
- 切换到用户模式
- 跳转到用户程序的合适位置,以重新启动程序。
CPU调度准则
- CPU使用率: 需要使CPU尽可能的忙碌。
- 吞吐量: 一个时间单元内所完成的进程的数量。
- 周转时间: 从进程提交到进程完成的时间段称为周转时间。周转时间为所有时间段之和,包括等待进入内存、在就绪队列中等待、在CPU上执行和I/O执行。周转时间 = 等待时间+执行时间 = 结束时间 - 进入队列时间。
- 等待时间: 等待时间为在就绪队列中等待所花费时间之和。
- 相应时间: 对于交互系统,周转时间并不是最佳准则。从提交请求到产生第一响应的时间,称为响应时间。
CPU调度算法
本章的重中之重
1. 先到先服务(first-come,first-served, FCFS)
对于就绪队列,先到先服务可以利用FIFO队列简单实现。

FCFS弊端: 采用FCFS的平均等待时间较长。当执行一个大进程时,所有的进程都要等待大进程释放CPU,称为护航效果(convoy effect),这样会导致CPU和设备的使用率变得很低。
2. 最短作业优先调度(shortest-job-first, SJF)
SJF将每个进程与其下一个CPU区间段相关联。当CPU空闲时,他会赋给具有最短CPU区间的进程。如果两个进程具有同样长度,那么可以使用FCFS调度来处理。
SJF特点:
- SJF调度算法的平均等待时间是最小的,同时系统的吞吐量也增大了。
- 有利于短进程,不利于常进程,长进程可能导致饥饿(又叫做无穷阻塞,指可以运行但缺乏CPU的进程)。
- SJF真正的困难在于很难知道下一个CPU区间的长度,所以它很难实现。
- 使用近似算法实现的SJF经常用于长期调度。
SJF近似算法: 下一个区间通常可预测为以前CPU区间的测量长度的指数平均。
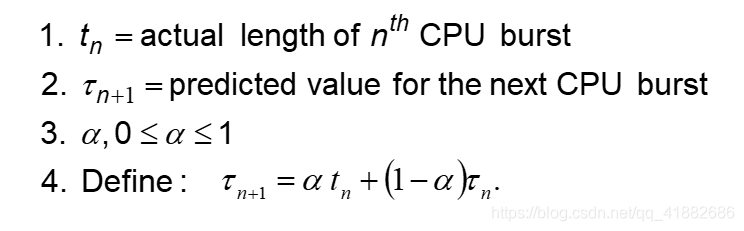
非抢占式SJF

抢占式SJF

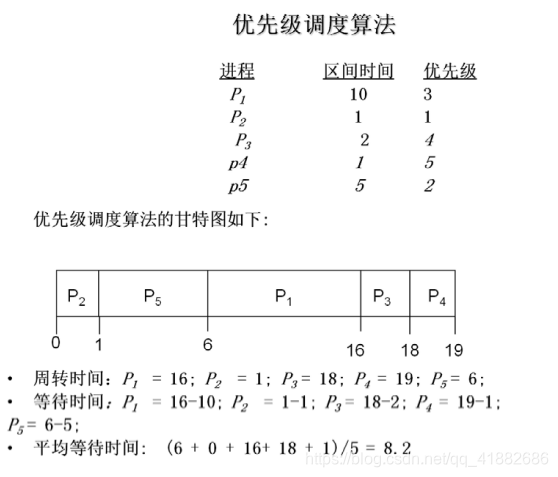
3. 优先级调度(priority scheduling algorithm)
优先级调度: SJF算法可作为通用优先级调度算法的一个特例。每个进程都有一个优先级与其关联,具有最高优先级的进程会分配到CPU。具有相同优先级的进程按FCFS顺序调度。SJF算法属于简单优先级算法,其优先级为预测CPU区间的倒数。CPU区间越大,优先级越小。 (在笔者这一版课本中,小数字表示高优先级 )
优先级调度的缺点及解决方法:
缺点:和SJF算法一样,优先级调度也会导致饥饿问题,优先级低的进程可能永远也等不到CPU的分配。
解决方法: 低优先级进程无穷等待问题的解决之一是老化(aging):随着等待时长的增加,逐渐增加在系统中等待时间很长的进程的优先级。
4. 轮转法调度(round-robin,RR)
轮转法类似于FCFS,但是增加了抢占以切换进程。抢占的机制是定义一个较小的时间单元称为时间片,当分配给一个进程的时间片结束时,切换进程。如果进程在时间片内运行结束,那么多余的时间片回收,然后切换进程。

上下文切换问题
RR算法的性能很大程度上依赖于时间片的大小。在极端情况下,如果时间片非常大,那么RR算法与FCFS算法一样。如果时间片很小,那么RR算法称为处理器共享。同时,还必须考虑到上下文切换对RR调度的影响。

根据经验,80%的CPU区间应小于时间片。
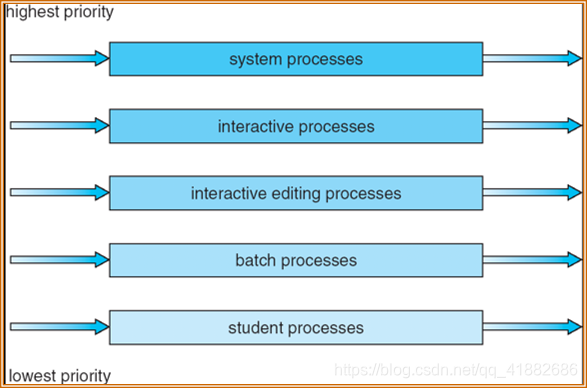
5. 多级队列调度
举个例子,对于前台进程和后台进程。这两种不同类型的进程具有不同响应时间要求,也有不同的调度需要。
多级队列调度算法: 将就绪队列分成多个独立队列。根据进程的属性,比如内存大小,优先级,进程类型,一个进程被永久地分配到一个队列。每个队列有自己的调度算法。
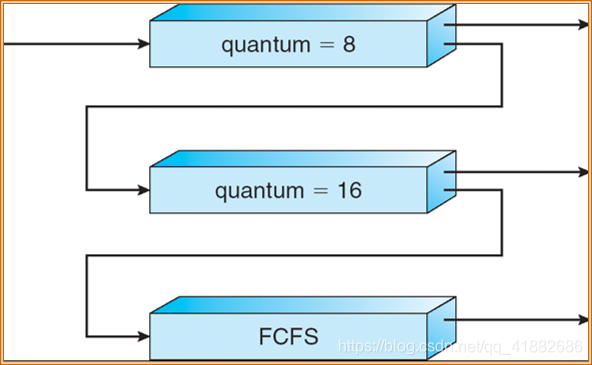
6. 多级反馈队列调度
与多级队列调度算法不同的时,进程在多级反馈队列中被分配到一个队列之后,还可以转移到其它队列。在队列之中转移也是一种老化的实现方式。
多处理器调度
与单处理器调度相比,多处理器的调度更为复杂,目前,与单处理器中的CPU调度算法一样,没有最好的解决方案。
非对称多处理: 让一个处理器处理所有的调度决定、I/O处理及其它活动,其它的处理器只执行用户代码。
对称多处理: 每个处理器自我调度。所有进程可能处于一个共同的就绪队列中,或每个处理器有自己的私有就绪进程队列。
处理器亲和性: 努力让一个进程在同一个处理器上运行,避免进程在处理器之间转移。
负载平衡:设法让工作负载平均地分配到SMP系统中的所有处理器上。
对称多线程: 在Intel处理器中,它也没称为超线程技术。SMT的思想是在同一个物理处理器上生成多个逻辑处理器,向操作系统呈现一个多逻辑处理器的视图。每个逻辑处理器都有它自己的架构状态,包括通用目的和机器状态寄存器。进一步讲,每个逻辑处理器负责自己的中断处理,这意味着中断被送到逻辑处理器所处理,而不是物理处理器。
线程调度
用户线程和内核线程的区别之一在于它们是如何被调度的。
**进程竞争范围(process-contention scope, PCS): ** 指线程库调度用户级线程到一个有效的LWP上运行。 且CPU竞争发生在属于相同进程的线程之间。
**系统竞争范围(system-contention scope, SCS): ** 当线程库调度用户线程到有效的LWP时,并不意味着线程实际上就在CPU上运行,着需要操作系统将内核线程调度到CPU上,即系统竞争范围。