项目描述
以电商数据为基础,详细介绍数据处理流程,结合hive数仓、spark开发采用多种方式实现大数据分析。
数据源可通过日志采集、爬虫、数据库中取得,经过数据清洗转换导入数据仓库,通过数仓中数据分析得到数据总结,用于企业决策。本项目基于以下表类进行电商数仓分析,分为orders(用户行为表),trains(订单表),products(商品表),departments(品类表),order_products__prior(用户历史行为表),实现多维度数仓分析。
数据仓库概念:
数据仓库(Data WareHouse),简写DW,为企业决策制定过程,提供所有系统数据支持的战略集合,通过对数据仓库中的数据分析,帮助企业改进业务流程,控制成本,提高产品质量。
数据仓里不是数据的最终目的地,而是为数据最终目的地做好准备,这些准备对数据:清洗,转义,分类,重组,合并,拆分,统计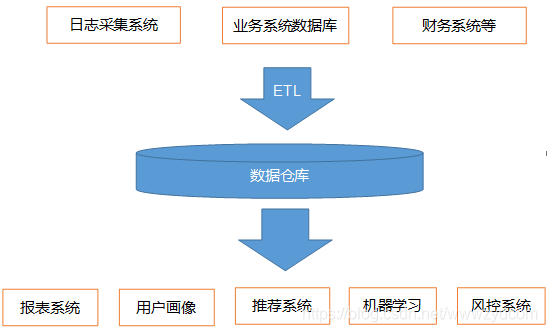
[infobox title="一、数据表"]
1.orders.csv (数据仓库中定位:用户行为表)
order_id:订单号
user_id:用户id
eval_set:订单的行为(历史产生的或者训练所需要的)
order_number:用户购买订单的先后顺序
order_dow:order day of week ,订单在星期几进行购买的(0-6)

order_hour_of_day:订单在哪个小时段产生的(0-23)
days_since_prior_order:表示后一个订单距离前一个订单的相隔天数
order_id,user_id,eval_set,order_number,order_dow,order_hour_of_day,days_since_prior_order
2539329,1,prior,1,2,08,
2398795,1,prior,2,3,07,15.0
473747,1,prior,3,3,12,21.0
2254736,1,prior,4,4,07,29.0
431534,1,prior,5,4,15,28.0
2.trains.csv
order_id:订单号
product_id:商品ID
add_to_cart_order:加入购物车的位置
reordered:这个订单是否重复购买(1 表示是 0 表示否)
order_id,product_id,add_to_cart_order,reordered
1,49302,1,1
1,11109,2,1
1,10246,3,0
1,49683,4,0
3.products.csv(数据仓库定位:商品维度表)
product_id:商品ID
product_name:商品名称
aisle_id:货架id
department_id:该商品数据属于哪个品类,日用品,或者生活用品等
product_id,product_name,aisle_id,department_id
1,Chocolate Sandwich Cookies,61,19
2,All-Seasons Salt,104,13
3,Robust Golden Unsweetened Oolong Tea,94,7
4,Smart Ones Classic Favorites Mini Rigatoni With Vodka Cream Sauce,38,1
5,Green Chile Anytime Sauce,5,13
4.departments.csv(品类维度表)
department_id:部门id, 品类id
department: 品类名称
department_id,department
1,frozen
2,other
3,bakery
5.order_products__prior.csv(用户历史行为数据)
order_id,product_id,add_to_cart_order,reordered
2,33120,1,1
2,28985,2,1
2,9327,3,0
[/infobox]
[infobox title="二、数据分析"]
1.将orders,trains建表,将数据导入到hive中?
建orders表
create table badou.orders(
order_id string
,user_id string
,eval_set string
,order_number string
,order_dow string
,order_hour_of_day string
,days_since_prior_order string)
row format delimited fields terminated by ','
lines terminated by '\n'
1.加载本地数据 overwrite 覆盖 into 追加
load data local inpath '/badou20/03hive/data/orders.csv'
overwrite into table orders
select * from orders limit 10;
hive> select * from orders limit 10;
OK
order_id user_id eval_set order_number order_dow order_hour_of_day days_since_prior_order
2539329 1 prior 1 2 08
2398795 1 prior 2 3 07 15.0
473747 1 prior 3 3 12 21.0
2254736 1 prior 4 4 07 29.0
431534 1 prior 5 4 15 28.0
2.加载hdfs数据(无local)
load data inpath '/orders.csv'
overwrite into table orders
建trains表
create table badou.trains(
order_id string,
product_id string,
add_to_cart_order string,
reordered string)
row format delimited fields terminated by ','
lines terminated by '\n'
load data local inpath '/badou20/03hive/data/order_products__train.csv'
overwrite into table trains
2.如何去掉表中第一行的脏数据?(原数据第一行为列名,导入时要删除)
方式一:shell命令
思想:在load数据之前,针对异常数据进行处理 sed '1d' orders.csv
head -10 orders.csv > tmp.csv
cat tmp.csv
sed '1d' tmp.csv > tmp_res.csv
cat tmp_res.csv
方式二:HQL (hive sql)
insert overwrite table badou.orders
select * from orders where order_id !='order_id'
insert overwrite table badou.trains
select * from trains where order_id !='order_id'
3.每个(groupby分组)用户有多少个订单(count(distinct))?
user_id order_id => user_id order_cnt
分组:针对不同类别进行归类,常用的 group by
结果: order count => order_cnt
select user_id, ordert_cnt 两列
第二列写法下面都可
, count(distinct order_id) order_cnt
--,count(*) order_cnt
--,count(1) order_cnt
--,count(order_id) order_cnt
完整语句:
select
user_id
, count(distinct order_id) order_cnt
from orders
group by user_id
order by order_cnt desc
limit 10
结果:两个job,Total MapReduce CPU Time Spent: 1 minutes 4 seconds 370 msec
133983 100
181936 100
14923 100
55827 100
4.每个用户一个订单平均是多少商品?
我今天购买了2个order,一个是10个商品,另一个是4个商品
(10+4)一个订单对应多少个商品 / 2
结果:一个用户购买了几个商品=7
a.先使用 priors 表,计算一个订单有多少个商品? 对应 10,4
注意:使用聚合函数(count、sum、avg、max、min )的时候要结合group by 进行使用
select
order_id,count(distinct product_id) pro_cnt
from priors
group by order_id
limit 10;
b.将priors表和order表通过order_id进行关联,将步骤a中商品数量带到用户上面
结果:用户对应的商品量
select
od.user_id, t.pro_cnt
from orders od
inner join (
select
order_id, count(1) as pro_cnt
from priors
group by order_id
limit 10000
) t
on od.order_id=t.order_id
limit 10;
c.针对步骤b,进行用户对应的商品量 sum求和
select
od.user_id, sum(t.pro_cnt) as sum_prods
from orders od
inner join (
select
order_id, count(1) as pro_cnt
from priors
group by order_id
limit 10000
) t
on od.order_id=t.order_id
group by od.user_id
limit 10;
d.计算平均
结果:用户的商品数量 / 用户的订单数量
select
od.user_id
, sum(t.pro_cnt) / count(1) as sc_prod
, avg(pro_cnt) as avg_prod
from orders od
inner join (
select
order_id, count(1) as pro_cnt
from priors
group by order_id
limit 10000
) t
on od.order_id=t.order_id
group by od.user_id
limit 10;
inner join : 多个表进行内连接
where :提取我们关注的数据
5.每个用户在一周中的购买订单的分布(列转行) ? dow => day of week 0-6 代表周一到周日
order_dow
orderday, pro_cnt
2020-12-19 1000000
2020-12-18 1000010
user_id, dow0, dow1, dow2, dow3,dow4,dow5,dow6
1 0 3 2 2 4 0 0
2 0 5 5 2 1 1 0
注意:实际开发中,一定是最先开始使用小批量数据进行验证,验证代码逻辑的正确性,然后全量跑!!
user_id order_dow
1 0 sum=0+1=1
1 0 sum=1+1=2
1 1
2 1
方式一:
select
user_id
, sum(case when order_dow='0' then 1 else 0 end) dow0
, sum(case when order_dow='1' then 1 else 0 end) dow1
, sum(case when order_dow='2' then 1 else 0 end) dow2
, sum(case when order_dow='3' then 1 else 0 end) dow3
, sum(case when order_dow='4' then 1 else 0 end) dow4
, sum(case when order_dow='5' then 1 else 0 end) dow5
, sum(case when order_dow='6' then 1 else 0 end) dow6
from orders
-- where user_id in ('1','2','3')
group by user_id
方式一:
select
user_id
, sum(if( order_dow='0',1,0)) dow0
, sum(if( order_dow='1',1,0)) dow1
, sum(if( order_dow='2',1,0)) dow2
, sum(if( order_dow='3',1,0)) dow3
, sum(if( order_dow='4',1,0)) dow4
, sum(if( order_dow='5',1,0)) dow5
, sum(if( order_dow='6',1,0)) dow6
from orders
where user_id in ('1','2','3')
group by user_id
抽样验证结果的准确性:
user_id dow0 dow1 dow2 dow3 dow4 dow5 dow6
1 0 3 2 2 4 0 0
2 0 6 5 2 1 1 0
课堂需求:某个时间段查看每个用户购买了哪些商品?
分析:user_id, product_id
orders : order_id, user_id
trains:order_id, product_id
select
ord.user_id, tr.product_id
from orders ord
inner join trains tr
on ord.order_id=tr.order_id
where order_hour_of_day = '10'
limit 10
CREATE TABLE `udata`(
`user_id` string,
`item_id` string,
`rating` string,
`timestamp` string)
ROW FORMAT DELIMITED
注意:timestamp关键字,建表使用 ``
881250949 -- > 1997-12-04 23:55:49
在udata表通过timestamp进行先后顺序的标记区分:
需求: 在推荐时候,想知道距离现在最近 或者最远的时间是什么时候?
select
max(`timestamp`) max_timestamp, min(`timestamp`) min_timestamp
from udata
max_timestamp min_timestamp
893286638 874724710
需求:得到某一个用户具体的评论天数,结果该用户在哪些天比较活跃,可能①用户确实很活跃 ② 用户可能存在刷单的情况,刷评价
user_id ['2020-12-19','2020-12-18',....]
24*60*60
collect_list : 不去重,将所有的user_id进行收集
select collect_list('1,2,3')
select
user_id, collect_list(cast(days as int)) as day_list
from
(select
user_id
, (cast(893286638 as bigint) - cast(`timestamp` as bigint)) / (24*60*60) * rating as days
from udata
) t
group by user_id
limit 10;
需求: 用户购买的商品数量大于100的数量有哪些?
union all: 数据合并,但是数据不去重, 注意 union all 前后的字段类型和字段个数必须保持一致
union:数据合并并且去重
方式一:
select
user_id, count(distinct product_id) pro_cnt
from
(
-- 订单训练数据 场景 整合两个新老系统数据
select
a.user_id,b.product_id
from orders as a
left join trains b
on a.order_id=b.order_id
union all
-- 订单历史数据
select
a.user_id,b.product_id
from orders as a
left join priors b
on a.order_id=b.order_id
) t
group by user_id
having pro_cnt >= 100
limit 10;
方式二:引入 with关键字,作用:涉及到逻辑很复杂,嵌套关系特别多使用,提高代码阅读性,便于排查问题
通过with修饰的可以理解为临时表或者临时数据集
with user_pro_cnt_tmp as (
select * from
(-- 订单训练数据
select
a.user_id,b.product_id
from orders as a
left join trains b
on a.order_id=b.order_id
union all
-- 订单历史数据
select
a.user_id,b.product_id
from orders as a
left join priors b
on a.order_id=b.order_id
) t
)
--, order_pro_tmp as (
--), ....
select
user_id
, count(distinct product_id) pro_cnt
from user_pro_cnt_tmp
group by user_id
having pro_cnt >= 100
limit 10;
[/infobox]