原文作者:哪有天生的学霸,一切都是厚积薄发
原文地址:MapReduce介绍
目录
场景
比如有海量的文本文件,如订单,页面点击事件的记录,量特别大,单机版很难搞定,怎么解决海量数据的计算?
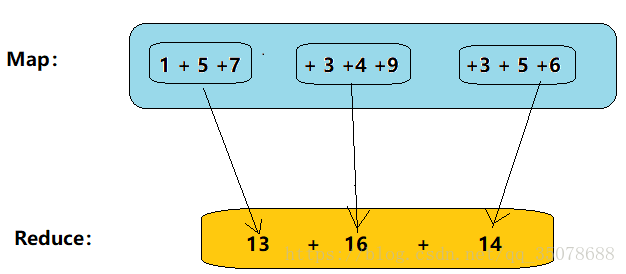
求和: 1 + 5 +7 + 3 +4 +9 +3 + 5 +6
MapReduce产生背景
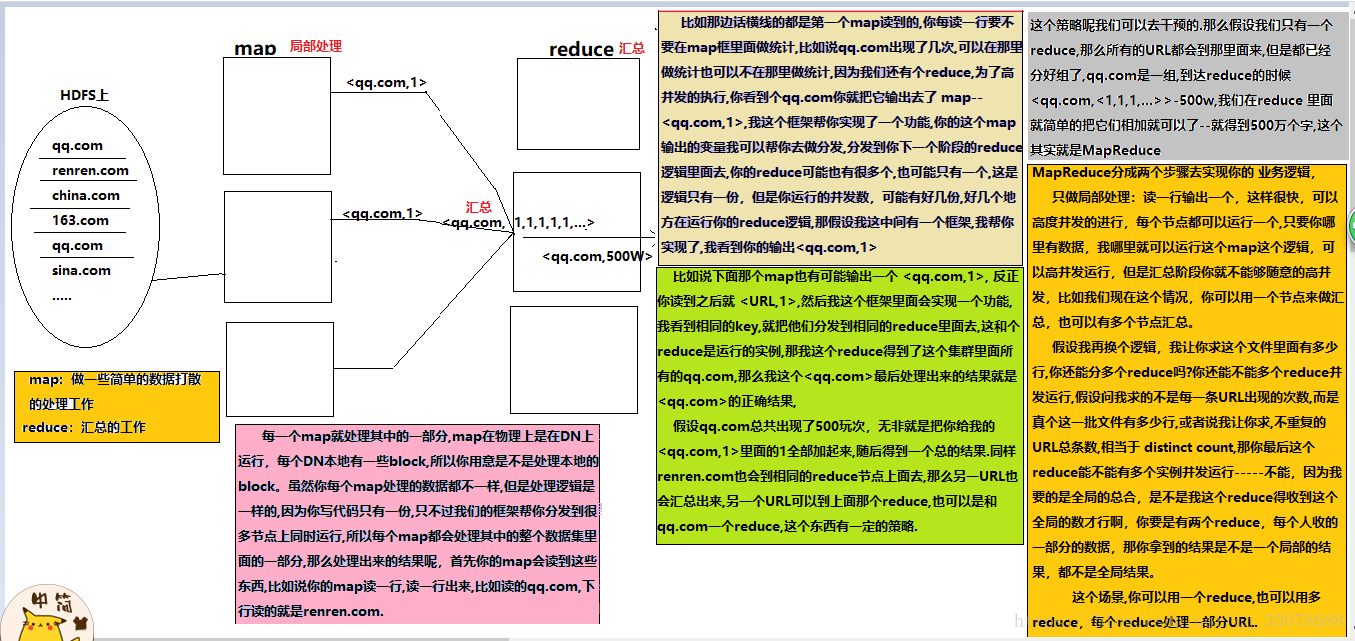
如果让你统计日志里面的出现的某个URL的总次数,让你自己去写个单机版的程序,写个逻辑:无非就是读这个文件一行,然后把那个地方截取出来,截取出来之后,然后可以把它放到一个HashMap里面,用Map去重,看到一条新的URL ,就把它put进去,然后+1,如果下次看到再有就直接+1,没有就put进去,单机版的话逻辑是很好实现,但是数据量一大,你觉得单机版本还能搞定吗?
首先2T的文件,你放在单机上可能存不下来,如果再他多一点呢?比如几千个文件,几十个T,单机存都存不下,那么存在哪里-------hdfs上。因为放在HDFS上可以放很多很多,比如说HDFS上有100个节点,每个节点上能耐挂载8T的硬盘,那就有800T,800T,你每个文件存3个副本的话,你至少也能存100多个T文件,耗费了大概6个T的空间,但是你一旦放到HDFS上就有一个问题:你的文件就会被切散了,被切散到很多的机器上,这个时候,你再对它们进行统计,这个时候,按照原来的逻辑,会不会出现问题?
你的任何一个节点上存的是某个文件的某些块,假设你是在那台机器上去做统计的话,你统计到的永远是局部的数据,那你专门写一个客户端,我的程序运行在这个客户端上,我去读数据,读一点统计一点,到把整个文件都读完了,统计结果也就出来了,问题是那样的话,你的程序又变成了一个单机版的,那你的内存也就不够,因为你要第一点进来统计一点,是不是要保存一些中间数据,那你可能内存也不够了,而且你因为是一个单机版的程序,所以你的速度是不是也很慢,而且你还要不断的从网络里面去拿那些数据,也会很慢,所以这个时候呢?你专门写一个客户端去做统计,肯定是不合适。
那你是不是应该把你的程序分发到集群的每一台DN上去做统计,也就是把运算往数据去移动,而不是把数据移动到运算,把我的运算逻辑移动到数据那端去,数据在哪里,我就在哪里运算,但是这也有一个问题,因为运算也变成了一个分布式的了,你的每一份运算结果都只是局部的结果,那么这个时候也存在问题:
你的代码怎么实现分发到很多机器上去运行,这件事情谁帮你做,如果是要你自己写程序的话,你是不是得有个U盘拷你的jar包,一个计算一个计算的去拷,拷完之后再启动,每个机器都启动jar,等你启动最后一台的时候,前面那台已经运行完了,最后一台才刚开始启动,这个工作你用手动去做是不是不合适啊?所以当你把一个简单的逻辑,变成这种分布式运行的时候,你发现很多问题就来了:
我的代码怎么分发,怎么配置启动环境,怎么启动起来,这个是不是得有一个庞大的系统去做,也就是说你应该额外开发这么一个叫做资源分发和Java启动程序这么一个配置 的系统,这个系统你会吗?写得出来吗?你要是写的话,是不是还得花很多时间,你还要写很多东西,因为你现在的Java不一定是擅长那个领域的 ,那这个耗费的代价就很大了
那个数据,比如刚才那个日志数据,是放到HDFS上面去了,但是不代表HDFS上的每一台DN上面都有这一部分数据里面的内容,因为我们这个集群很大,你这个文件存进去的时候可能只占了其中的30台节点,其中某30台节点上有你这些文件,其他节点上个根本就没有你这些文件,那我们的代码,运行逻辑,最好是放到那30台上面去做统计,你放到其他的那些机器上,它可以运行,但是它的数据必须来源于网络,是不是效率会比较低,也就是说你的代码究竟分发到哪些机器上去运行,是不是也要一个策略的问题,那么这个策略是不是也有一定的算法,那么这个时候,你为了实现你那个简单的逻辑,就再去开发这样一个系统出来是不是也是很大的开发量,再考虑一个问题,假如刚才那两个工作你都做完了,你的代码真的成功的在那30台机器上跑起来了,跑起来之后,其中假设有一台机器宕机了,那么你统计的那一部分局部数据是不是也就没有了,那个局部结果也就没有了,那个局部结果没有,假设你有个汇总的结果还正确吗?没有意义了,也就是说你还得解决一个问题,就是你时时刻刻得却监控着你的程序运行情况,那个节点正常,哪个节点不正常,这个问题也是很复杂的,假设这个问题 你也解决了,还有一个问题:
刚才你的逻辑只是统计出中间结果,这个时候是不是还得汇总啊,汇总就是意味着,你要在那30台节点之间结果里面才能汇总,要么把它们全部调到一台机器上就能进行汇总,但是你调到一台机器上汇总的话,你那一台机器的负载是不是会很高,对吧?假设我调到多态机器汇总,逻辑就变得复杂了,比如说,只要是你们那30台机器上统计,每台机器上的那个URL有多少条,你又把那个所有那个URL的数据全部汇总到某个汇总节点,假如有两个URL,哪个URL分发到那个节点上进行汇总,这个策略是不是也会变得很复杂了,那你还得去做个中间数据的调度系统,那也很麻烦。
那这样的话,我们就发现,哪怕是一个很简单的东西,你也要把它变成一个分布式运行的程序,是不是面临很多很多其他的问题,跟我们逻辑无关的问题,往往这些问题要比解决那个逻辑要复杂得多,那么这些问题解决不是我们擅长的,我们大量的普通程序员还没达到那些程度,这么复杂的问题要写出来是不是很麻烦呢?你不能要求每个程序员都能达到那个功力把,我们不过就是写个简单的逻辑统计这个文本里面哪个URL出现的总次数,很简单的东西,所以呢,MapReduce才是我们这些普通程序员的福音。
就是说当我们面临海量数据处理的时候,那个逻辑也许很简单,但是面临海量数据处理,要我们这个 逻辑代码变成分布式运行,就会变得很复杂,而那些很复杂的事情又不是我们关心的,我关心的只是那个逻辑,那这个时候,就有人把你不擅长的而且又必须解决的,而且跟你的逻辑关系又不大的那些东西全部给封装起来,那么这个时候,我们是不是就直接写逻辑了,就会MapReduce的框架和Yarn,这两个是不是做运算的,由这两个框架把我们刚才讲的那些东西全部封装起来,这个就是MapReduce产生的背景,就是这个问题。
MapReduce功能:
综上,MapReduce提供了以下的主要
- 数据划分和计算任务调度:
系统自动将一个作业(Job)待处理的大数据划分为很多个数据块,每个数据块对应于一个计算任务(Task),并自动 调度计算节点来处理相应的数据块。作业和任务调度功能主要负责分配和调度计算节点(Map节点或Reduce节点),同时负责监控这些节点的执行状态,并 负责Map节点执行的同步控制。
- 数据/代码互定位:
为了减少数据通信,一个基本原则是本地化数据处理,即一个计算节点尽可能处理其本地磁盘上所分布存储的数据,这实现了代码向 数据的迁移;当无法进行这种本地化数据处理时,再寻找其他可用节点并将数据从网络上传送给该节点(数据向代码迁移),但将尽可能从数据所在的本地机架上寻 找可用节点以减少通信延迟。
- 系统优化:
为了减少数据通信开销,中间结果数据进入Reduce节点前会进行一定的合并处理;一个Reduce节点所处理的数据可能会来自多个 Map节点,为了避免Reduce计算阶段发生数据相关性,Map节点输出的中间结果需使用一定的策略进行适当的划分处理,保证相关性数据发送到同一个 Reduce节点;此外,系统还进行一些计算性能优化处理,如对最慢的计算任务采用多备份执行、选最快完成者作为结果。
- 出错检测和恢复:
以低端商用服务器构成的大规模MapReduce计算集群中,节点硬件(主机、磁盘、内存等)出错和软件出错是常态,因此 MapReduce需要能检测并隔离出错节点,并调度分配新的节点接管出错节点的计算任务。同时,系统还将维护数据存储的可靠性,用多备份冗余存储机制提 高数据存储的可靠性,并能及时检测和恢复出错的数据。
总结
把我们很简单的运算逻辑很方便的扩展到海量数据的场景下分布式运算,所以MapReduce程序对我们程序员来说很简单,因为它把那些东西都给封装起来了,你只要写业务逻辑,写业务逻辑还不擅长吗?业务逻辑大部分就是处理文本,处理字符串,我们学的大部分逻辑里面,大部分都是在处理这个问题:处理文本、处理字符串、查询数据库是不是得到一些东西啊。查询一下数据库,处理一下字符串,输出结果,而这个逻辑本身 不用你太多的分布式细节 ,你只要把逻辑写出来就可以了,但是你写MapReduce的时候,必须要符合人家编程的规范,你不能你的写法写,他按他的写法写,每个人的写法都不一样,那MapReduce也没法给你去分发和运行,所以你也要符合他的规范,怎样才算符合规范呢?就说你的代码,你的任意一个逻辑实现都要分成这么两个步骤:
- Map
- Reduce
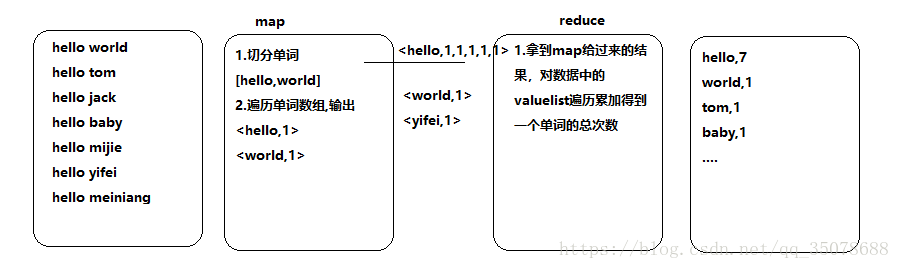
比如说我们统计日志文件里面,相同URL出现的总次数如下图: