一、 引言
工作中,随着数据库表数据量的增大,我们会发现,对表数据的读写操作会变得越来越慢,有时候查询一条数据会耗费几十秒或几分钟才查出结果,甚至多点击几次查询还会出现宕机。
这个时候,我们可能首先会想到通过对表结构、业务代码、索引、SQL语句等方面进行优化,以此来提高读写操作响应速度。然而,对于表数据量相对较大的情况,我们发现优化效果有限,并未达到预期效果。
此时,我们可以考虑是否可以通冷热分离来提升读写、查询效率。
二、 什么是冷热分离?
为了更好的理解冷热分离的概念,我们先了解下什么是热数据,什么是冷数据。
热数据
热数据指的是需要即时对用户进行分发的数据,即从数据源抓取之后经过数据处理,需要即时存储到可快速分发的存储介质供API或直接面向用户的系统使用。
热数据需要重点保障服务质量和稳定性,为了保证数据的时效性,在数据处理上也是优先级高的数据。
冷数据
冷数据指的是不需要即时发给用户的数据。
这些数不会原样分发给用户,它们需要经过长期的积累,使我们可以从中得到基于此更高层次的分析。
冷热分离
冷热分离指的是在处理数据时将数据库分为冷库和热库,冷库指用于存放走到了终态的数据(冷数据)的数据库,热库用于存放还需要修改的数据(热数据)的数据库。
三、 什么情况下使用冷热分离?
从冷热分离的定义我们可以知道当业务需求涉及到冷热数据,表数据量增长速度快或数据量较大时, 我们就该考虑是否使用冷热分离解决方案了。比如:
1)数据走到终态后,只有读没有写的需求。
2)用户能够接受新旧数据分开实现业务,比如查询新旧数据的时候分开操作。
四、 冷热分离实现思路
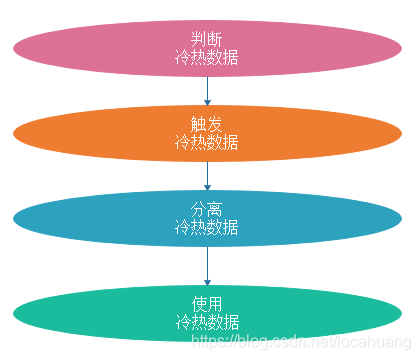
4.1 如何判断一个数据到底是冷数据还是热数据?
一个数据是冷数据还是热数据,需要根据实际的业务需求来制定判定条件。满足热数据条件的归为热数据,满足冷数据条件的归为冷数据。
判定条件可以是表里的1个字段或多个字段组合的方式组成。
时间、状态等都是比较适合用作判定条件的字段。
比如,我们管理一个订单系统,针对订单主表,我们可以使用下面两种方式作为冷热数据的界定:
- 方式1:使用“下单时间”字段作为判定条件,3个月内的订单数据作为热数据,3个月前的订单数据作为冷数据。
- 方式2:使用“完结状态”字段作为判定条件,未完结的订单作为热数据,已完结的订单作为冷数据。
关于判断冷热数据的逻辑,这里还有 2 个注意要点必须说明:
1)如果一个数据被标识为冷数据,业务代码不会再对它进行写操作;
2)不会同时存在读冷/热数据的需求。
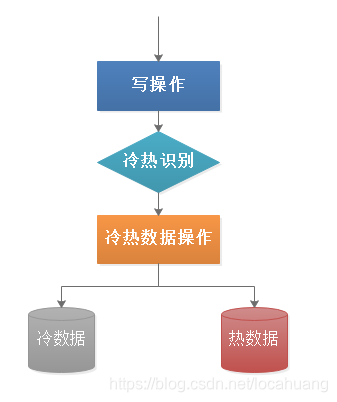
4.2 如何触发冷热数据分离?
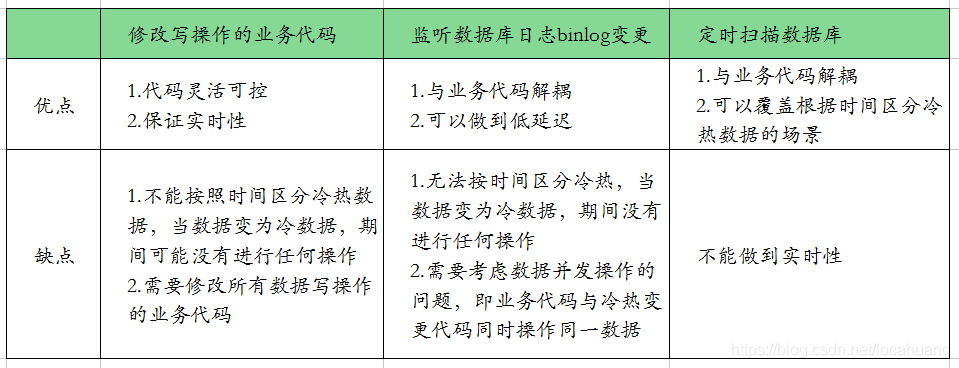
一般来说,冷热数据分离的触发实现有3种方式:业务层代码实现、binlog实现、定时扫描数据库实现。
(一)业务层代码实现
在代码中实现,当有对数据进行写操作时,触发冷热分离。
建议使用场景:业务代码比较简单,并且不按照时间区分冷热数据时使用。
(二)binlog实现
监听数据库变更日志binlog的方式来触发。
建议使用场景:业务代码比较复杂,不敢随意变更,并且不按照时间区分冷热数据时使用。
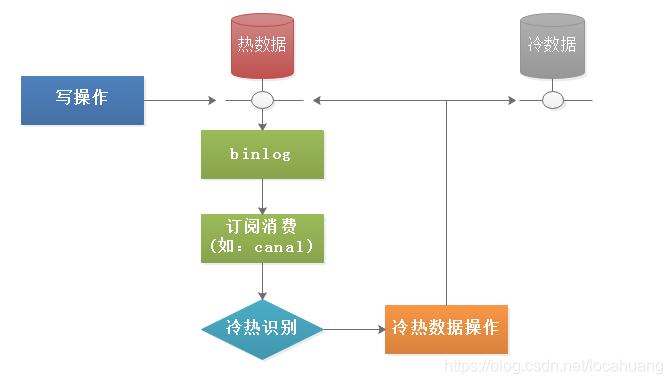
实际使用binlog方式实现过程中,我们可能会遇到以下问题:
问题描述:
定时任务删除数据时,也会产生binlog,如何区别数据的删除是定时任务产生的,还是正常的业务?
解决方案:
我们可以通过设置binlog的session级别,也就是在此session中操作的语句,并不会产生binlog。
set session sql_log_bin=0;//optset session sql_log_bin=1;
我们在定时任务执行时,先关闭binlog,然后,执行删除语句,然后,重新恢复binlog。这些删除的数据,就不会通过canal同步到冷库中了。
(三)定时扫描数据库实现
通过定时扫描数据库的方式来触发。
建议使用场景:在按照时间区分冷热数据时使用。
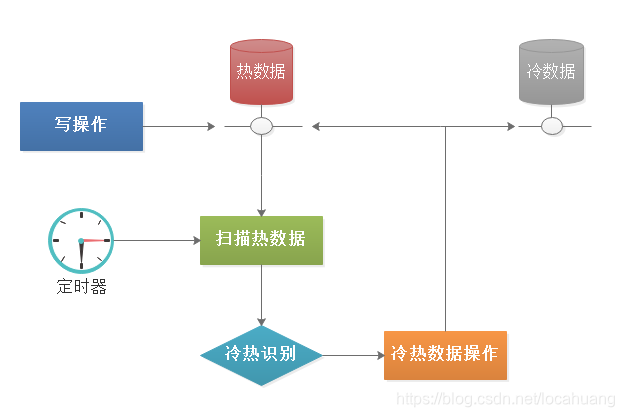
3种触发方式的优缺点比较
4.3 如何实现冷热数据分离?
冷热数据分离示意图如下:

上述分离逻辑看起来比较简单,不过在实际方案实施的时候,我们需要考虑以下情况:
(1)一致性:同时修改多个数据库,如何保证数据的一致性?
情形描述:一致性要求指的是,当分离过程中如何保证任何一步出错后数据还是一致的。
解决方法:保证每一步都可以重试,并且操作都有幂等性。
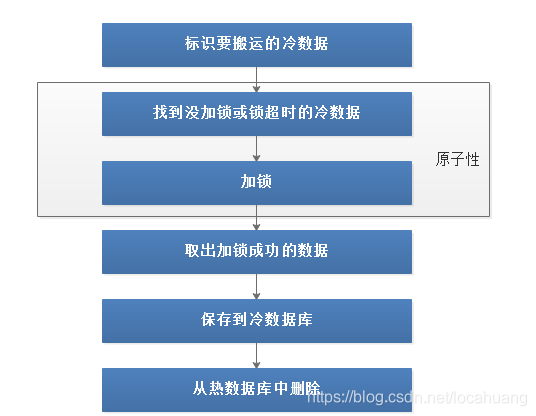
具体逻辑分4步:
- 在热数据库中,给要搬的数据加个标识: ColdFlag=WaittingForMove。(实际处理中标识字段的值用数字即可)
- 找出所有待搬的数据(ColdFlag=WaittingForMove):这步是为了确保前面有些线程因为部分原因失败,出现有些待搬的数据没有搬的情况。
- 在冷数据库中保存一份数据,但在保存逻辑中需加个判断以此保证幂等性(这里需要用事务包围起来),通俗点说就是假如我们保存的数据在冷数据库已经存在了,也要确保这个逻辑可以继续进行。
- 从热数据库中删除对应的数据。
(2)数据量:假设数据量大,一次性处理不完,该怎么办?是否需要使用批量处理?
情形描述:定时扫描的逻辑需要考虑数据量问题。
解决方法:在搬数据的地方增加批量逻辑。
如:假设我们每次可以搬50条数据
a. 在热数据库中给要搬的数据加个标识:ColdFlag=WaittingForMove;
b. 找出前 50 条待搬的数据(ColdFlag=WaittingForMove);
c. 在冷数据库中保存一份数据;
d. 从热数据库中删除对应的数据;
e. 循环执行 b。
(3)并发性:假设数据量大到要分到多个地方并行处理,该怎么办?
情形描述:数据量过大,以致单线程无法处理时,我们使用多线程需要考虑哪些问题。
step1:如何启动多线程?
-
方式1:采用的是定时器触发逻辑,设置多个定时器,并让每个定时器之间的间隔短一些,然后每次定时启动一个线程就开始搬运数据。
-
方式2:自建一个线程池,然后定时触发后面的操作:先计算待搬动的热数据的数量,再计算要同时启动的线程数,如果大于线程池的数量就取线程池的线程数,假设这个数量为 N,最后循环 N 次启动线程池的线程搬运冷热数据。
step2:某线程宣布某个数据正在操作,其他线程不要动(锁)
- 获取锁的原子性: 当一个线程发现某个待处理的数据没有加锁,然后给它加锁,这 2 步操作必须是原子性的,即要么一起成功,要么一起失败。实际操作为先在表中加上 LockThread 和 LockTime 两个字段,然后通过一条 SQL 语句找出待迁移的未加锁或锁超时的数据,再更新 LockThread=当前线程,LockTime=当前时间,最后利用 MySQL 的更新锁机制实现原子性。
- 获取锁必须与开始处理保证一致性: 当前线程开始处理这条数据时,需要再次检查下操作的数据是否由当前线程锁定成功,实际操作为再次查询一下 LockThread= 当前线程的数据,再处理查询出来的数据。
- 释放锁必须与处理完成保证一致性: 当前线程处理完数据后,必须保证锁释放出去。
step3:如果出现某线程正常处理完后,数据不在热库,直接跑到了冷库,这是正常的,无需处理。
step4:某线程失败退出了,结果锁没释放怎么办(锁超时)?
分两种情况处理:
- 如果锁定这个数据的线程异常退出了且来不及释放锁,导致其他线程无法处理这个数据:解决方案为给锁设置一个超时时间,如果锁超时了还未释放,其他线程可正常处理该数据。
- 如果正在处理的线程并未退出,因还在处理数据导致了超时:解决方案为尽量给超时的时间设置成超过处理数据的合理时间,且处理冷热数据的代码里必须保证是幂等性的。
考虑到前面逻辑比较复杂,这里我们特地画了一个分离的流程图,如下图所示:
4.4 如何使用冷热数据?
如何使用冷热数据,需要根据实际业务需求来定。
比如我们要查询未完结订单,这个时候使用的就是热库中的数据。
需要注意的是:
在判断数据是冷数据还是热数据时,必须确保用户不允许同时有读冷热数据的需求。
五、 冷热分离整体方案及不足
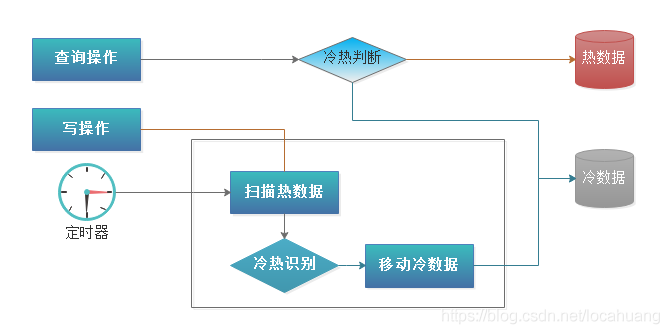
5.1 冷热分离整体方案
5.2 冷热分离解决方案的不足
冷热分离确实可以在某种程度上解决写读写数据慢的问题,但是仍然存在诸多不足。具体表现有:
1)用户查询冷数据速度依旧很慢。
2)由于冷数据多到一定程度,业务就无法再修改冷数据,因为数据量太大系统承受不住。