一、 引言
系统特点
客服系统有一个工单查询功能,工单表特点及用户需求如下:
1)工单表中存放了几千万条数据。
2)查询工单表数据时需要关联十几个子表,每个子表的数据也是超亿条。
3)工单表中的有些数据是几年前的,客户需要这些数据继续保持更新。
问题描述
每次客户查询数据时几十秒甚至更长的时间才能返回结果。
解决方案选型
方式1:使用索引、SQL等数据库优化技巧来进行解决,但是由于数据量庞大,关联的子表较多,优化效果并不明显。
方式2:使用冷热分离,但是第3)条的客户需求限制,直接pass该方案。
那有没有什么方案可以解决上述特点系统的查询慢问题呢?
答案是肯定的,这就是我们本文要介绍的查询分离。
二、 什么是查询分离?
查询分离即:每次写数据时,除了把数据写到主数据库中外,另保存一份数据到另外的存储系统里,用户查询数据时直接从另外的存储系统里获取数据。
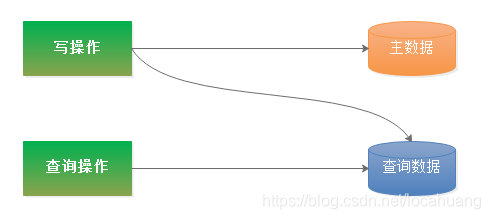
三、 哪些场景下使用查询分离?
相信在第一章节中,我们对查询分离的使用场景已经有了初步的了解。
下面我们对实际业务中应该使用查询分离的情况进行归纳:
- 数据量大;
- 所有写数据的请求效率尚可;
- 查询数据的请求效率很低;
- 所有的数据任何时候都可能被修改;
- 业务希望我们优化查询数据的功能。
四、 查询分离实现思路
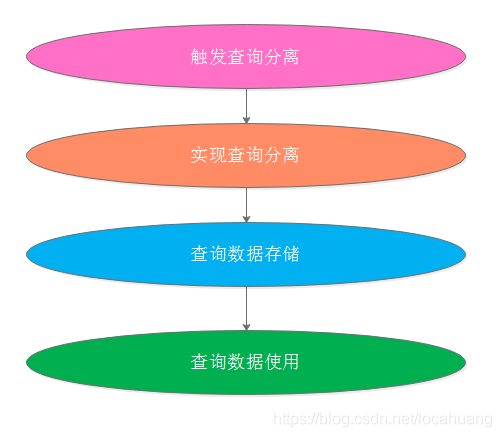
4.1 如何触发查询分离?
如何触发查询分离,可简单理解为:应该在什么时候保存一份数据到查询数据中。
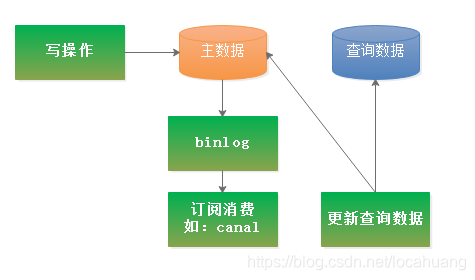
一般来说,查询分离触发实现有2种方式:业务层代码实现、binlog实现,其中业务层代码实现又可细分为2种(同步、异步)实现方式。
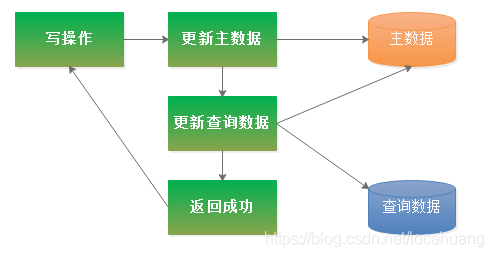
(一)业务层代码实现:写入常规数据后 ,同步建立查询数据。
适用场景:业务代码比较简单并且对写操作的响应速度要求不高。
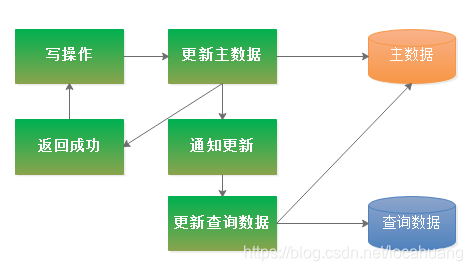
(二)业务层代码实现:写入常规数据后,异步建立查询数据。
使用场景:业务代码比较简单并且对写操作响应速度有要求。(真实业务场景中,这种方式使用的比较多)
(三)监控数据库日志binlog实现:有数据变更,则更新查询数据。
使用场景:业务代码比较复杂,或改动代价太大。
3种触发方式的优缺点比较
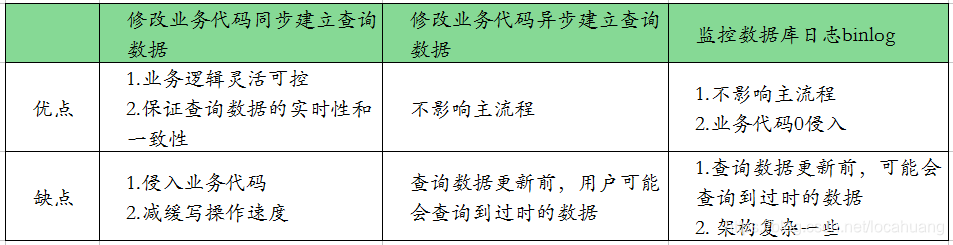
表中的几个概念说明:
什么叫业务逻辑灵活可控? 一般来说,写业务代码的人能从业务逻辑中快速判断出何种情况下更新查询数据,而监控数据库日志的人并不能将全部的数据库变更分支穷举,再把所有的可能性关联到对应的更新查询数据逻辑中,最终导致任何数据的变更都需要重新建立查询数据。
什么叫减缓写操作速度? 建立查询数据的一个动作能减缓多少写操作速度?答案:很多。
举个栗子:当你只是简单更新了订单的一个标识,本来查询数据时间只需要 2ms,而在查询数据时可能会涉及重建(比如使用 ES 查询数据时会涉及索引、分片、主从备份,其中每个动作又细分为很多子动作,这些内容后面我们会讲到),这时建立查询数据的过程可能就需要 1s 了,从 2ms 变成 1s,你说减缓幅度大不大?
查询数据更新前,用户可能查询到过时数据。 这里我们结合第 2 种触发逻辑来讲,比如某个操作正处于订单更新状态,状态更新时会通过异步更新查询数据,更新完后订单才从“待审核”状态变为“已审核”状态。假设查询数据的更新时间需要 1 秒,这 1 秒中如果用户正在查询订单状态,这时主数据虽然已变为“已审核”状态,但最终查询的结果还是显示“待审核”状态。
4.2 如何实现查询分离?
这里只针对 业务层代码实现:写入常规数据后,异步建立查询数据 查询分离方式进行讲解。简单总结有两种实现方式:
(一)方式1:单独起一个线程建立查询数据
这种实现方式相对简单,不过需要实际应用中可能会出现以下问题:
- 写操作较多且线程太多,最终撑爆 JVM;
- 建查询数据的线程出错了,如何自动重试;
- 多线程并发时,很多并发场景需要解决。
从上述问题列表可以知道,该方式虽然简单,但是问题也多。因此,不建议使用该方式。
(二)方式2:借用MQ进行管理
MQ的具体操作思路为每次主数据写操作请求处理时,都会发一个通知给 MQ,MQ 收到通知后唤醒一个线程更新查询数据,示意图如下:
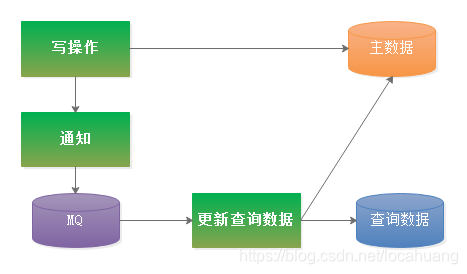
了解了 MQ 的具体操作思路后,我们还应该考虑以下 5 大问题:
(1)问题1:MQ 如何选型?
MQ 如何选型并没有绝对的参考条件,大家可以根据自身的实际情况进行选型。
比如,如果公司已经使用MQ,并且在项目上得到了很好的应用,那么就可以选择自己熟悉并且经过实战考验的MQ,毕竟经过打磨的技术,可以避免掉坑和走弯路。
如果公司还没使用MQ, 并且对各类MQ的优缺点、使用场景都还不是很熟悉,那么MQ的选型就很有必要了。
总的来说可以选择原则有以下几点,供参考:
1)根据业务需求、特点,选择几款比较合适的MQ。
2)召集技术中心所有可以做技术决策的人共同投票选型。
3)结合易用性和代码工作量角度考量。
(2)问题2:MQ 宕机了怎么办?
如果遇到MQ宕机,我们需要保证主流程正常进行,不能因为MQ的宕机导致工作流停滞;同时保证MQ恢复后数据能够正常处理。
具体方案:
- 每次写操作时,在主数据中加个标识:NeedUpdateQueryData=true,这样发到 MQ 的消息就很简单,只是一个简单的信号告知更新数据,并不包含更新的数据 id。
- MQ 的消费者获取信号后,先批量查询待更新的主数据,然后批量更新查询数据,更新完后查询数据的主数据标识 NeedUpdateQueryData 就更新成 false 了。
- 当然还存在多个消费者同时搬运动作的情况,这就涉及并发性的问题,问题与 冷热分离中的并发性处理逻辑类似。
(3)问题3:更新查询数据的线程失败了怎么办?
如果更新的线程失败了,NeedUpdateQueryData 的标识就不会更新,后面的消费者会再次将有 NeedUpdateQueryData 标识的数据拿出来处理。但如果一直失败,我们可以在主数据中多添加一个尝试搬运次数,比如每次尝试搬运时 +1,成功后就清零,以此监控那些尝试搬运次数过多的数据。
(4)问题4:消息的幂等消费
在编程中,一个幂等操作的特点是多次执行某个操作均与执行一次操作的影响相同。
举个例子,比如主数据的订单 A 更新后,我们在查询数据中插入了 A,可是此时系统出问题了,系统误以为查询数据没更新,又把订单 A 插入更新了一次。
所谓幂等,就是不管更新查询数据的逻辑执行几次,结果都是我们想要的结果。因此,考虑消费端并发性的问题时,我们需要保证更新查询数据幂等。
(5)问题5:消息的时序性问题
比如某个订单 A 更新了 1 次数据变成 A1,线程甲将 A1 的数据搬到查询数据中。不一会儿,后台订单 A 又更新了 1 次数据变成 A2,线程乙也启动工作,将 A2 的数据搬到查询数据中。
所谓的时序性就是如果线程甲启动比乙早,但搬运数据动作比线程乙还晚完成,就有可能出现查询数据最终变成过期的 A1。如下图(动作前面的序号代表实际动作的先后顺序):

解决方案:
每次更新都更新上次更新时间 last_update_time,然后每个线程更新查询数据后,检查当前订单 A 的 last_update_time 是否跟线程刚开始获得的时间一样,且 NeedUpdateQueryData 是否等于 false,如果都满足的话,我们就将 NeedUpdateQueryData 改为 true,然后再做一次搬运。
4.3 查询数据如何存储?
选择何种数据存储技术,需要结合实际业务需求以及自身的组织架构进行综合考虑。
目前大数据量的搜索查询用的比较广泛的是Elasticsearch 。
4.4 查询数据如何使用?
若在上一小节中,我们选择Elasticsearch 实现大数据量的搜索查询,那么在查询数据时,我们可以直接在代码中调用ES的API函数即可。
该方式可能会出现”数据查询更新完前,查询数据不一致“问题,这个时候我们可以参考下面2种解决思路来解决:
1)思路1:查询数据更新到最新之前,不允许用户查询。
2)思路2:给用户提示,目前查询到的数据可能是1秒前的数据,如果发现数据不准确,可以尝试刷新。
五、 查询分离的整体方案及不足
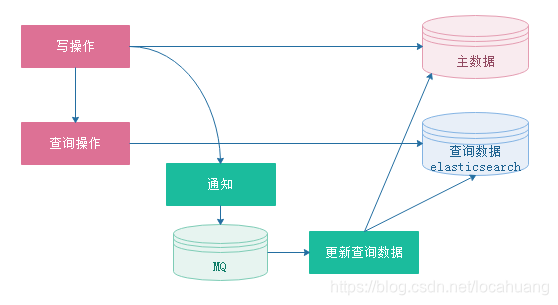
5.1 查询分离的整体方案
5.2 查询分离方案的不足
查询分离这个解决方案虽然能解决一些问题,但我们也要清醒地认识到它的不足。
1)使用 Elasticsearch 存储查询数据时,一些需要注意的事项要搞清楚。
2)主数据量越来越大后,写操作还是慢,到时还是会出问题。
3)主数据和查询数据不一致时,假设业务逻辑需要查询数据保持一致性,也是需要我们考虑的问题。