一、什么是慢日志
慢日志:用来记录执行比较慢的一些sql
二、优化大致思路
- 根据慢日志定位慢查询sql
- 使用explain等工具分析sql
- 修改sql或者尽量让sql走索引
三、例子详解
环境:Navicat for MySQL,MySQL8.0+,win10
博主这里为了方便测试,提前插入了50万条数据(花了挺久的,选错引擎了,用的InnoDb,貌似用myisam会很快)下边给出脚本内容
/*
Navicat MySQL Data Transfer
Source Server : test
Source Server Version : 80014
Source Host : localhost:3306
Source Database : mysql_study
Target Server Type : MYSQL
Target Server Version : 80014
File Encoding : 65001
Date: 2020-04-21 11:50:48
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for person_info_large
-- ----------------------------
DROP TABLE IF EXISTS `person_info_large`;
CREATE TABLE `person_info_large` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`,`age`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=501946 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Procedure structure for add_vote_memory
-- ----------------------------
DROP PROCEDURE IF EXISTS `add_vote_memory`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `add_vote_memory`(IN `n` int)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE (i <= n ) DO
INSERT into person_info_large (name,age) VALUEs (rand_string(20),FLOOR(RAND() * 100));
set i=i+1;
END WHILE;
END
;;
DELIMITER ;
-- ----------------------------
-- Function structure for rand_string
-- ----------------------------
DROP FUNCTION IF EXISTS `rand_string`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` FUNCTION `rand_string`(`n` int) RETURNS varchar(255) CHARSET utf8
NO SQL
BEGIN
DECLARE chars_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE return_str varchar(255) DEFAULT '' ;
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = concat(return_str,substring(chars_str , FLOOR(1 + RAND()*62 ),1));
SET i = i +1;
END WHILE;
RETURN return_str;
END
;;
DELIMITER ;
里面有一个函数和一个存储过程,用来插入大量数据的,觉得慢可以百度另一种引擎方法。
在插入数据之前,最好去my.ini里面加上一句max_heap_table_size = 1024M,避免无法存那么多。找不到my.ini的可以百度一下。
调用存储过程直接:CALL add_vote_memory(500000);,时间比较久,可以耐心等待一下
我们先查询一些变量:SHOW VARIABLES LIKE "%quer%";,我的是已经修改好的
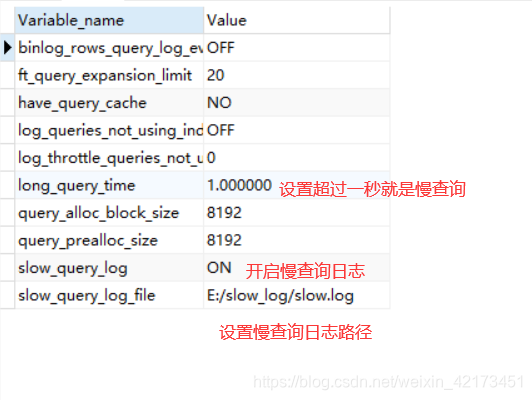
设置语句用SET GLOBAL name =
设置long_query_time后不会立马生效,需要关闭当前连接,重新进去,我们再次查询,看是否改变,不行的话,就直接改my.ini文件进行修改这三项,修改完后记得重新启动mysql服务。
我们写一个查询:SELECT name from person_info_large ORDER BY name DESC;
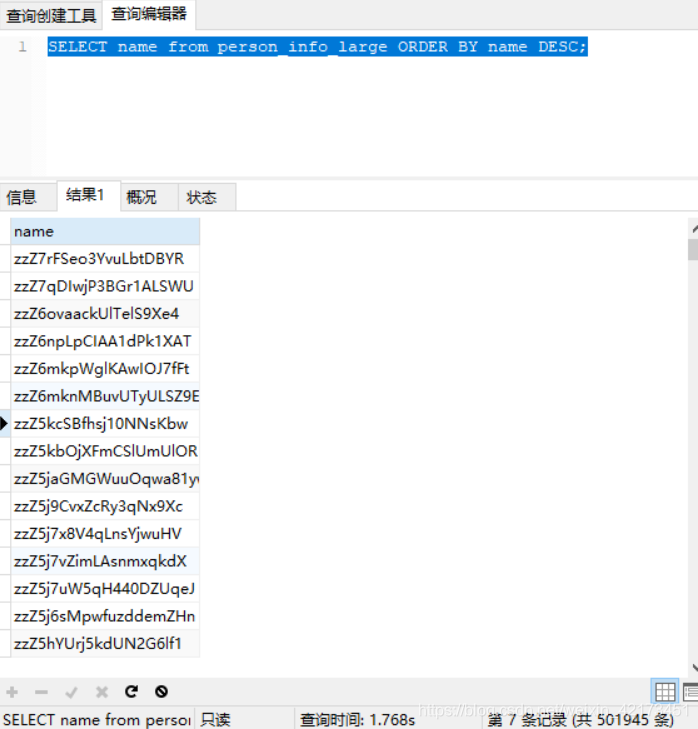
可以看到,查询时间超过了1秒,我们可以查询一下慢查询sql:show status like '%slow_queries%';

已经记录了一条,我们可以去慢查询日志看一下

里面有慢查询sql,以上就是定位的方法。
explain工具分析sql
只需要在sql前面加一个explain即可,具体的explain语法可以网上查询一下,这里不再细说
执行没走索引的查询加排序:explain SELECT name from person_info_large ORDER BY name DESC;,结果如下

可以看到出现了ALL和Using filesort字样,一般我们都是要改sql,让其走索引的,目前的需求只是查询name,于是我们可以加一个普通索引:alter table person_info_large add index idx_name(name);(注:添加索引是DDL语言,不会算成慢查询日志里)执行之后,走索引查询一次:SELECT name from person_info_large ORDER BY name DESC;

嗯,0.492秒,是的,你没有看错,提高了72%,虽然只是个小测试,我们继续用explain分析一下

测试count(id)会走主键还是普通索引
执行explain select count(id) from person_info_large;,结果如下:

它走的是普通索引,为什么呢?
- 这是因为mysql的优化器会选择索引并且选择更加严格的索引,即数据形式简单的索引,优化器认为主键里面存放的不仅仅是id,还有其他的数据,故,优化器选择idx_name
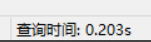
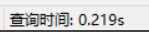
但是这样一定是最优吗?我们对走两个索引的耗时测试一下
- 走主键索引:
select count(id) from person_info_large force index(PRIMARY);
- 走普通索引:
select count(id) from person_info_large;
两个我试了几次,走主键的确快些,所以,优化器考虑的只是一部分,更多的还是要看自己实际业务中根据实际情况来优化。
