研究了几天终于将hdfs的java api调用搞通了,其中的艰辛一度让我想要放弃,但最终让我坚持了下来。这几天的经验,无疑是宝贵的,故记录下来,以防以后遗忘。我用的是版本2.10.0,你要问我为啥选择这个版本,我的回答是我也不知道,只知道官网上的下载列表第一个就是它。
1、下载
wget https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
2、安装
我是采用Linux系统来安装的(windows系统试了,没有跑起来),所谓安装也就是解压出来
tar -zxvf hadoop-2.10.0.tar.gz
3、部署
按照官网文档来就好了:https://hadoop.apache.org/docs/r2.10.0/hadoop-project-dist/hadoop-common/SingleCluster.html
(1)、设置java home,一般都安装了java的,所以这步可以省略
# set to the root of your Java installation
export JAVA_HOME=/usr/java/latest
(2)、试试解压出来的文件有没有问题
dave@ubuntu:~/d/opt/hadoop-2.10.0$ ./bin/hadoop
(3)、试试单机运行有没有问题
dave@ubuntu:~/d/opt/hadoop-2.10.0$ mkdir input
dave@ubuntu:~/d/opt/hadoop-2.10.0$ cp etc/hadoop/*.xml input
dave@ubuntu:~/d/opt/hadoop-2.10.0$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar grep input output 'dfs[a-z.]+'
dave@ubuntu:~/d/opt/hadoop-2.10.0$ cat output/*
(4)、伪分布式操作
配置:
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
访问localhost密钥设置(这个不设置的话,每次启动停止都要你输密码):
dave@ubuntu:~/d/opt/hadoop-2.10.0$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
dave@ubuntu:~/d/opt/hadoop-2.10.0$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
dave@ubuntu:~/d/opt/hadoop-2.10.0$ chmod 0600 ~/.ssh/authorized_keys
格式化文件系统:
dave@ubuntu:~/d/opt/hadoop-2.10.0$ bin/hdfs namenode -format
启动namenode、datanode相关守护进程:
dave@ubuntu:~/d/opt/hadoop-2.10.0$ sbin/start-dfs.sh
浏览器访问一下试试:
http://192.168.137.162:50070(官网上是localhost,我在另一台windows主机上访问也没问题,这台windows也是我后面写java代码的主机,所以在这台机器上试试能不能访问)
可以看到没有任何问题:
做一些操作试试(在部署hdfs的主机上操作):
dave@ubuntu:~/d/opt/hadoop-2.10.0$ ./bin/hdfs dfs -mkdir /user
dave@ubuntu:~/d/opt/hadoop-2.10.0$ ./bin/hdfs dfs -mkdir /user/dave
dave@ubuntu:~/d/opt/hadoop-2.10.0$ ./bin/hdfs dfs -put etc/hadoop input
通过浏览器来看看put上去的文件:
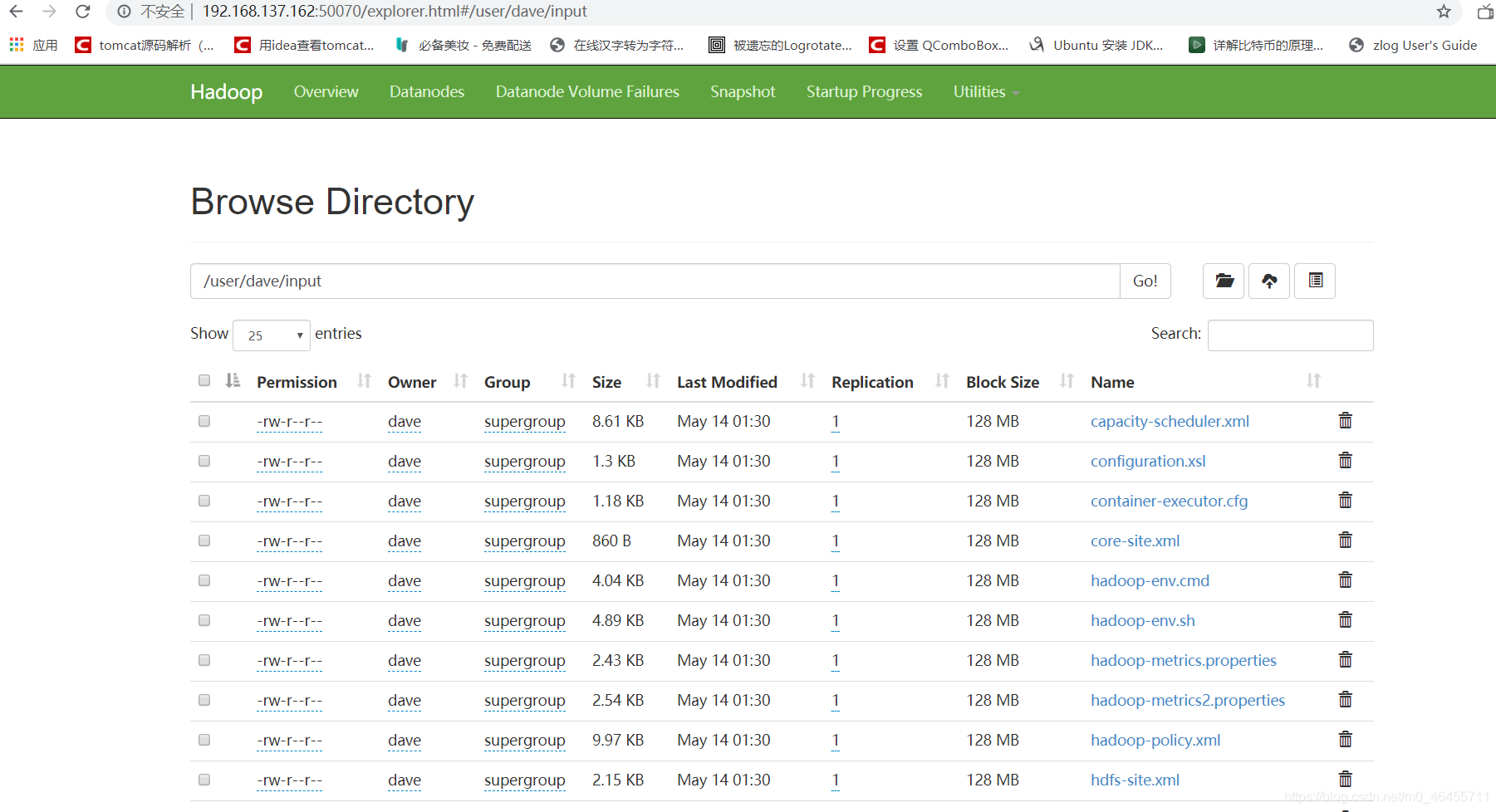
一切都出奇的顺利,那我们就来用java api来操作一下。
4、Java api调用
新建一个maven项目,引入两个依赖:
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.10.0</version>
</dependency>
新建一个测试的类:
package com.luoye.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class Application {
public static void main(String[] args) {
Configuration configuration=new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.137.162:9000");
try {
FileSystem fileSystem=FileSystem.newInstance(configuration);
//上传文件
fileSystem.mkdirs(new Path("/dave"));
fileSystem.copyFromLocalFile(new Path("C:\\Users\\dave\\Desktop\\suwei\\terminal.ini"), new Path("/dave/terminal.ini"));
} catch (IOException e) {
e.printStackTrace();
}
}
}
注意,配置里面fs.defaultFS因为不是本地所以要用部署namenode的主机的IP地址。
一切就绪,那就跑一个看看,应该没任何问题:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
java.net.ConnectException: Call From DESKTOP-JE4MI3O/169.254.47.191 to 192.168.137.162:9000 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:422)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:824)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:754)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1544)
at org.apache.hadoop.ipc.Client.call(Client.java:1486)
at org.apache.hadoop.ipc.Client.call(Client.java:1385)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:118)
at com.sun.proxy.$Proxy10.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.mkdirs(ClientNamenodeProtocolTranslatorPB.java:587)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy11.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:2475)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:2450)
at org.apache.hadoop.hdfs.DistributedFileSystem$27.doCall(DistributedFileSystem.java:1242)
at org.apache.hadoop.hdfs.DistributedFileSystem$27.doCall(DistributedFileSystem.java:1239)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:1239)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:1231)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:2216)
at com.luoye.hadoop.Application.main(Application.java:17)
Caused by: java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:701)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:805)
at org.apache.hadoop.ipc.Client$Connection.access$3700(Client.java:423)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1601)
at org.apache.hadoop.ipc.Client.call(Client.java:1432)
... 24 more
可是现实总是在你以为一切都ok的时候狠狠给你一棒。
程序报错了,通过网页查看,文件也没有上传上去。
可是为啥会出错呢,我们仔细看看报错信息:
java.net.ConnectException: Call From DESKTOP-JE4MI3O/169.254.47.191 to 192.168.137.162:9000 failed on connection
连不上!!!
为啥呢?在部署的主机上操作都没问题的啊。
难道9000这个端口绑定的地址有问题?
还是到部署主机上去看一下:
dave@ubuntu:~/d/opt/hadoop-2.10.0$ netstat -anp|grep LISTEN
果然:
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 10958/java
好吧,那看看能不能配置一下,让它不绑定到127.0.0.1呢,翻翻官网的配置吧:
http://hadoop.apache.org/docs/r2.10.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
功夫不负有心人,终于让我找到一条:
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value></value>
<description>
The actual address the RPC server will bind to. If this optional address is
set, it overrides only the hostname portion of dfs.namenode.rpc-address.
It can also be specified per name node or name service for HA/Federation.
This is useful for making the name node listen on all interfaces by
setting it to 0.0.0.0.
</description>
</property>
那就在部署主机上的配置文件hdfs-site.xml里面配置上吧。
然后重启:
dave@ubuntu:~/d/opt/hadoop-2.10.0$ ./sbin/stop-dfs.sh
dave@ubuntu:~/d/opt/hadoop-2.10.0$ ./sbin/start-dfs.sh
好了,我们再来试试Java api调用:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /dave/terminal.ini could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and 1 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1832)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:265)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2591)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:880)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:517)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:507)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1034)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:994)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:922)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1893)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2833)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1540)
at org.apache.hadoop.ipc.Client.call(Client.java:1486)
at org.apache.hadoop.ipc.Client.call(Client.java:1385)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:118)
at com.sun.proxy.$Proxy10.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:448)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DataStreamer.locateFollowingBlock(DataStreamer.java:1846)
at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1645)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:710)
还是报错!!!!
这是什么错啊,完全懵逼啊。
没办法网上找找资料吧。
通过网上的一些零碎的资料拼凑起来,大概明白原因是这样的:客户端在收到namenode返回的datanode列表时会去确定datanode是不是可用,如果不可用就会把这个datanode从列表中剔除,所以这里报错说只有0个datanode可以存副本,意思就是datanode访问不了。
这就奇怪了,为啥访问不了啊。
真是让人崩溃啊,老天啊,来个人告诉我为啥吧。
我心里一遍遍在呐喊着,可是老天爷根本就没空理我,在网上找了一圈资料,一无所获。
要是能多输出点信息就好了,我心想。
这时我注意到开头几行,似乎是说log4j配置有问题。好吧,配置一些试试了,于是在resource目录下配置好一个log4j.xml,再次运行,于是我看到了这样的输出:
2020-05-14 02:19:06,573 DEBUG ipc.ProtobufRpcEngine 253 invoke - Call: addBlock took 4ms
2020-05-14 02:19:06,580 DEBUG hdfs.DataStreamer 1686 createBlockOutputStream - pipeline = [DatanodeInfoWithStorage[127.0.0.1:50010,DS-a1ac1217-f93d-486f-bb01-3183e58bad87,DISK]]
2020-05-14 02:19:06,580 DEBUG hdfs.DataStreamer 255 createSocketForPipeline - Connecting to datanode 127.0.0.1:50010
2020-05-14 02:19:07,600 INFO hdfs.DataStreamer 1763 createBlockOutputStream - Exception in createBlockOutputStream
java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.hdfs.DataStreamer.createSocketForPipeline(DataStreamer.java:259)
at org.apache.hadoop.hdfs.DataStreamer.createBlockOutputStream(DataStreamer.java:1699)
at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1655)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:710)
2020-05-14 02:19:07,601 WARN hdfs.DataStreamer 1658 nextBlockOutputStream - Abandoning BP-111504192-127.0.1.1-1589381622124:blk_1073741864_1040
咦,为啥要去连接127.0.0.1?
一定是缺少什么配置,好吧,再去翻翻官网上的配置文件吧。
翻来翻去也没有看到哪个配置是说去设置datanode的访问地址是部署主机的ip地址的,不过有一个似乎可行的配置:
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>false</value>
<description>Whether clients should use datanode hostnames when
connecting to datanodes.
</description>
</property>
客户端用主机名连接,那就试试这个:
首先在代码里面加上:
configuration.set("dfs.client.use.datanode.hostname","true");
然后在写程序的这台主机的hosts文件中加上域名和ip地址的映射(部署主机上Hadoop自动加了映射的):
192.168.137.162 ubuntu
ubuntu是我部署主机的hostname,192.168.137.162是其IP地址。
好了,再试试:
2020-05-14 02:29:04,888 DEBUG hdfs.DataStreamer 873 waitForAckedSeqno - Waiting for ack for: 1
2020-05-14 02:29:04,900 DEBUG ipc.Client 1138 run - IPC Client (428566321) connection to /192.168.137.162:9000 from dave sending #3 org.apache.hadoop.hdfs.protocol.ClientProtocol.addBlock
2020-05-14 02:29:04,903 DEBUG ipc.Client 1192 receiveRpcResponse - IPC Client (428566321) connection to /192.168.137.162:9000 from dave got value #3
2020-05-14 02:29:04,903 DEBUG ipc.ProtobufRpcEngine 253 invoke - Call: addBlock took 3ms
2020-05-14 02:29:04,913 DEBUG hdfs.DataStreamer 1686 createBlockOutputStream - pipeline = [DatanodeInfoWithStorage[127.0.0.1:50010,DS-a1ac1217-f93d-486f-bb01-3183e58bad87,DISK]]
2020-05-14 02:29:04,913 DEBUG hdfs.DataStreamer 255 createSocketForPipeline - Connecting to datanode ubuntu:50010
2020-05-14 02:29:04,915 DEBUG hdfs.DataStreamer 267 createSocketForPipeline - Send buf size 65536
2020-05-14 02:29:04,915 DEBUG sasl.SaslDataTransferClient 239 checkTrustAndSend - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-05-14 02:29:04,916 DEBUG ipc.Client 1138 run - IPC Client (428566321) connection to /192.168.137.162:9000 from dave sending #4 org.apache.hadoop.hdfs.protocol.ClientProtocol.getServerDefaults
2020-05-14 02:29:04,935 DEBUG ipc.Client 1192 receiveRpcResponse - IPC Client (428566321) connection to /192.168.137.162:9000 from dave got value #4
2020-05-14 02:29:04,936 DEBUG ipc.ProtobufRpcEngine 253 invoke - Call: getServerDefaults took 21ms
2020-05-14 02:29:04,943 DEBUG sasl.SaslDataTransferClient 279 send - SASL client skipping handshake in unsecured configuration for addr = ubuntu/192.168.137.162, datanodeId = DatanodeInfoWithStorage[127.0.0.1:50010,DS-a1ac1217-f93d-486f-bb01-3183e58bad87,DISK]
2020-05-14 02:29:05,057 DEBUG hdfs.DataStreamer 617 initDataStreaming - nodes [DatanodeInfoWithStorage[127.0.0.1:50010,DS-a1ac1217-f93d-486f-bb01-3183e58bad87,DISK]] storageTypes [DISK] storageIDs [DS-a1ac1217-f93d-486f-bb01-3183e58bad87]
2020-05-14 02:29:05,058 DEBUG hdfs.DataStreamer 766 run - DataStreamer block BP-111504192-127.0.1.1-1589381622124:blk_1073741865_1041 sending packet packet seqno: 0 offsetInBlock: 0 lastPacketInBlock: false lastByteOffsetInBlock: 456
2020-05-14 02:29:05,118 DEBUG hdfs.DataStreamer 1095 run - DFSClient seqno: 0 reply: SUCCESS downstreamAckTimeNanos: 0 flag: 0
2020-05-14 02:29:05,119 DEBUG hdfs.DataStreamer 766 run - DataStreamer block BP-111504192-127.0.1.1-1589381622124:blk_1073741865_1041 sending packet packet seqno: 1 offsetInBlock: 456 lastPacketInBlock: true lastByteOffsetInBlock: 456
2020-05-14 02:29:05,124 DEBUG hdfs.DataStreamer 1095 run - DFSClient seqno: 1 reply: SUCCESS downstreamAckTimeNanos: 0 flag: 0
哈哈,终于不报错了,通过浏览器查看,文件也有了:
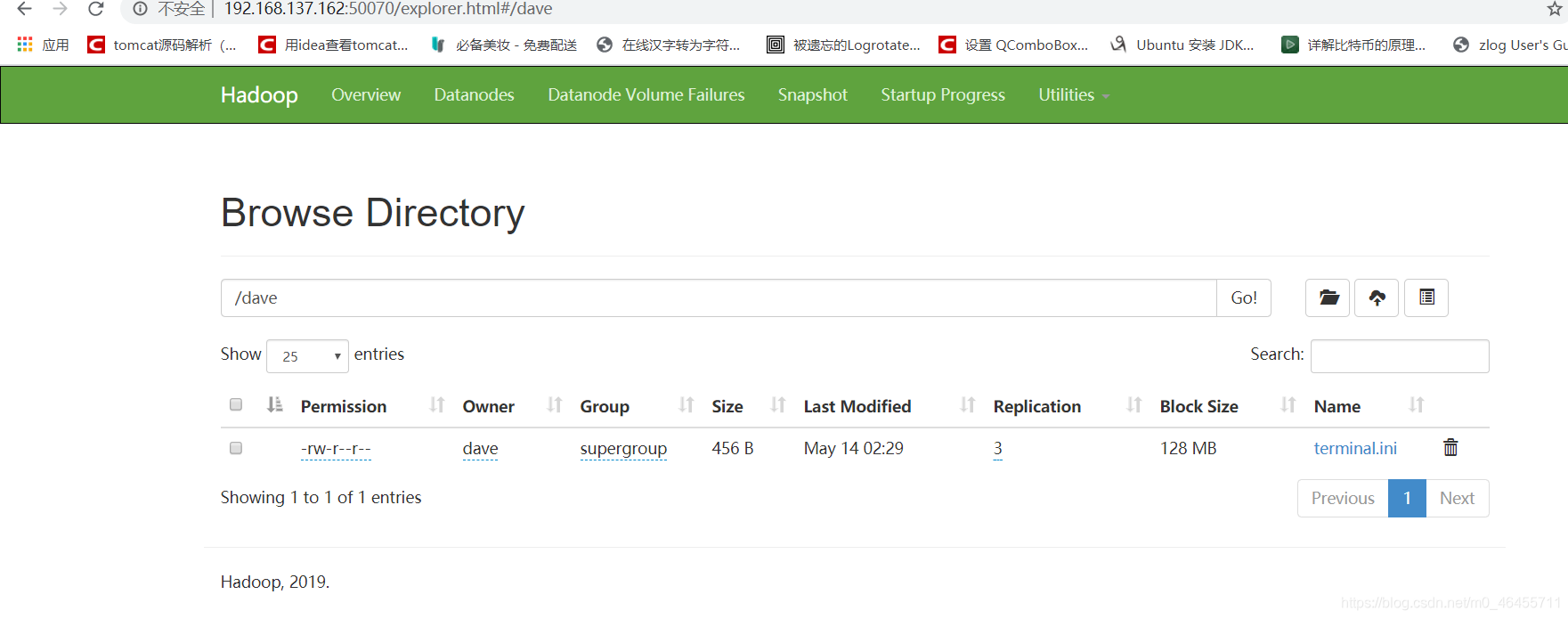
最后,还记录一点,在部署主机的配置文件etc/hadoop/hdfs-site.xml最好配置一个属性:
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
</description>
</property>
将权限检查关掉,不然有可能因为权限问题,不能操作文件。
最后的最后想说,遇到这些问题,主要还是对hdfs了解不深,所以还是要加深学习才行。