数字IC一些知识点总结
- 一、基础篇
-
- 1.基本逻辑运算
- 2.setup、hold time分析
- 3.Recorvery、Removal time
- 4.状态机相关的问题
- 5.跨时钟域
- 6.异步FIFO
- 7.脉冲同步器
- 8.无毛刺时钟切换
- 9.竞争冒险现象
- 10.串并转换、并串转换
- 11.分频电路(奇数、偶数分频)
- 12.任意切换的时钟分频电路
- 13.综合成锁存器的情况
- 14.时钟门控
- 15.同步复位、异步复位
- 16.异步复位同步释放
- 17.乒乓buffer
- 18.超前进位加法器
- 19.booth乘法器
- 20.Wallace树型乘法器
- 21.除法器
- 22.线性反馈移位寄存器LFSR
- 23.Verilog有符号数运算
- 24.RTL代码对应的电路
- 25.数字IC设计步骤及软件
- 26.常见的低功耗设计方法
- 27.N倍频的verilog模型
- 28.电容与电感导致的相位差问题
- 29.根据VOH,VOL,VIH,VIL求电压容限
- 30.动态,静态,功能,时序:验证
- 31.JK触发器、T触发器
- 32.产生序列信号需要触发器的个数
- 33.CRC循环冗余校验
- 34.如何评价一个芯片
- 35.如何提升总线吞吐速率
- 二、提升篇
一、基础篇
1.基本逻辑运算
仅用与非或仅用与或非、最小项之和、最大项之积、卡诺图化简、逻辑门的mos管组成,笔试常出现
最小项之和、最大项之积 例题:

卡诺图与最小项的关系:

卡诺图化简:
卡诺图中两个相邻1格的最小项可以合并成一个与项,并消去一个变量。
卡诺图中四个相邻1格的最小项可以合并成一个与项,并消去两个变量。
卡诺图中八个相邻1格的最小项可以合并成一个与项,并消去三个变量。
只要每个1都至少遍历到一遍就可以。
例题:
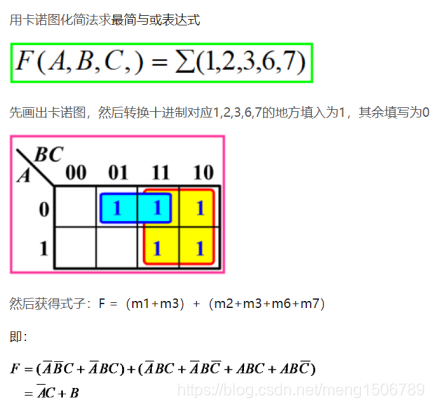
逻辑门的mos管组成 例题:画出 Y=A+BC 的 CMOS 电路?
重点是取“非” → 使用“非门”、“与非门NAND”、“或非门NOR”设计电路
二进制-格雷码:assign graycode[N-1:0] = {bincode[N-1] , bincode[N-1:1]^bincode[N-2:0]};
格雷码-二进制:
bincode[N-1] = graycode[N-1];
for(i = N-2; i >= 0; i=i-1)
bincode[i] = graycode[i]^bincode[i+1];
·
2.setup、hold time分析
(需深入理解,而不是简单会计算,笔试甚至可能出几道问答题)
建立时间(setup time)是指在触发器的时钟信号上升沿到来以前,数据稳定不变的时间,如果建立时间不够,数据将不能在这个时钟上升沿被输入触发器;
保持时间(hold time) 是指在触发器的时钟信号上升沿到来以后,数据稳定不变的时间,如果保持时间不够,数据不能从触发器稳定输出。
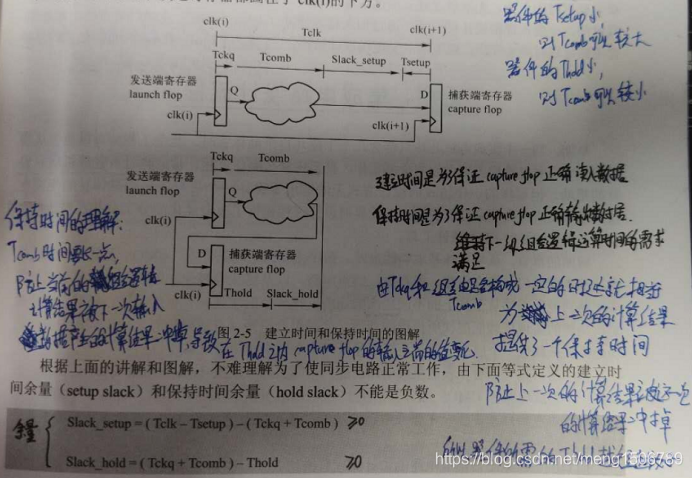
Setup/Hold violation:
Tsetup < Tclk + Tskew - Tckp -Tcomb
Thold < Tckq + Tcomb -Tskew
(其中Tskew :同一时钟线的分支长度不同导致有效沿在不同时间点触发DFF,引起偏差)
解决不满足器件的setup/hold time的方法:改变不等式右边的数值。
RTL设计阶段,解决setup violation常用方法:
(1)优化组合逻辑;(2)使用流水线;(3)使用慢时钟;
例题1:
D触发器:Tsetup = 3ns,Thold = 1ns,Tckq = 1ns,该D触发器最大可运行的时钟频率是多少?
答案:250MHz
Tsetup + Tckq是整个路径的delay,最大频率和Thold无关。
例题2:
下图中的电路,器件延时如图中标注,将框内电路作为一个寄存器,其有效setup time和hold time分别是多少?
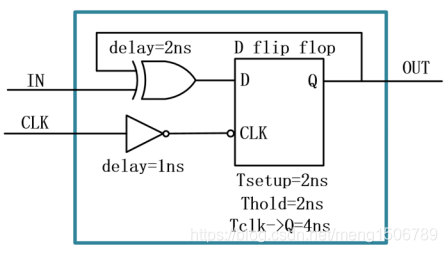
解析:有效建立时间:假设电路的有效Setup为Tsetup_valid,对于D触发器而言,其本身的建立时间是2ns,也就是说数据必须在时钟有效沿到达之前2ns保持稳定,这样到达D端后就一定是稳定的数据了。这个电路的数据来自于IN,时钟来自于CLK。
考虑时钟路径延迟影响:电路有效建立时间Tsetup_valid = Tsetup - 1ns = 1ns(因为数据需要提前1ns稳定下来)
考虑数据路径延迟影响:Tsetup_valid= Tsetup - 1ns + 2ns = 3ns;(经过组合逻辑后的数据需要在时钟有效沿之前Tsetup时间稳定下来)
有效保持时间分析:和建立时间分析套路一致,对于D触发器而言,数据需要在时钟有效沿到来之后保持Thold时间。
考虑时钟延迟的影响:考虑到电路时钟对于触发器时钟早到1ns,所以电路有效保持时间Thold_valid = Thold + 1ns = 3ns;
考虑路径延迟影响:数据需要经过一段组合逻辑之后才能保持稳定(组合逻辑的延迟为DFF提供了保持时间),因此电路的有效保持时间为:Thold_valid = Thold + 1ns - 2ns = 1ns。
3.Recorvery、Removal time
对于一个异步复位寄存器来说,异步复位信号需要和时钟满足Recovery time和Removal time 才能有效进行复位和复位释放操作,防止输出亚稳态。

Recovery time(恢复时间):撤销复位时,恢复到非复位状态的电平必须在时钟有效沿来临之前的一段时间到来,才能保证有效地恢复到非复位状态,此段时间为recovery time。类似于同步时钟的setup time。
(→ 恢复 :是指从复位恢复到正常)
Removal time(去除时间):复位时,rst_n保持为0经过clk上升沿后仍需要保持一段时间,才能保证寄存器有效复位,防止亚稳态。在时钟有效沿来临之后复位信号还需要保持的时间为去除时间removal time。类似同步时钟hold time。
保证复位不出现问题:(1)使用同步复位;(2)使用异步复位、同步释放。
4.状态机相关的问题
状态机的种类;状态转移图、序列检测;一段、二段、三段式状态机的verilog描述
状态机种类及状态转移图、序列检测 例题:设计011序列检测器
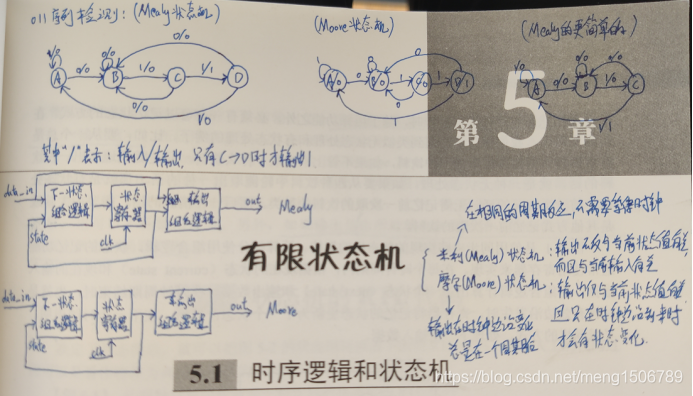
一段、二段、三段式状态机:
(1)一段式:整个状态机写到一个always模块里面,在该模块中既描述状态转移,又描述状态的输入和输出;
(2)二段式:用两个always模块来描述状态机,其中一个always模块采用同步时序描述状态转移;另一个模块采用组合逻辑判断状态转移条件,描述状态转移规律以及输出;便于阅读、理解、维护,利于综合器优化代码,利于用户添加合适的时序约束条件,利于布局布线器实现设计。
(3)三段式:在两个always模块描述方法基础上,使用三个always模块,一个always模块采用同步时序描述状态转移,一个always采用组合逻辑判断状态转移条件,描述状态转移规律,第三个always模块描述状态输出(使用时序电路输出,避免第二段组合逻辑产生的毛刺)。
三段式状态机 例子:
//第一个进程,同步时序always模块,格式化描述次态寄存器迁移到现态寄存器
always @ (posedge clk or negedge rst_n) //异步复位
if(!rst_n)
current_state <= IDLE;
else
current_state <= next_state; //更新状态,非阻塞赋值
//第二个进程,组合逻辑always模块,描述状态转移条件判断
always @ (*) //电平触发
begin
next_state = IDLE;//给一个初始值,避免综合工具综合出锁存器
case(current_state)
IDLE: if(...)
next_state = S1; //阻塞赋值
S1: if(...)
next_state = S2; //阻塞赋值
...
default:... //default的作用是避免综合工具综合出锁存器
endcase
end
//第三个进程,同步时序always模块,描述下一个状态对应的输出(即当前应该输出的值)
always @ (posedge clk or negedge rst_n)
if(!rst_n)
begin
out1 <= 0;
out2 <= 0;
end
else
case(next_state)
IDLE:
out1 <= 0;
S1:
out1 <= 1'b1; //注意是非阻塞逻辑
S2:
out2 <= 1'b1;
default:...
endcase
end
5.跨时钟域
(Clock Domain Crossing ,CDC)
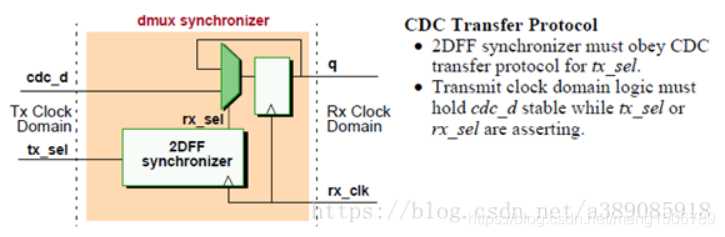
两级触发器,脉冲同步器(单脉冲快到慢),握手协议,异步FIFO,DMUX(慢到快)
两级触发器:
(适用于单比特信号)

握手协议:
(适用于多比特信号,但需要花费多个时钟周期)
在信号没有被正确接收前,输入数据不能变化。
(1)sender准备好要发送的数据,然后发送请求req;
(2)receiver接收到数据和req后,发送ack;
(3)sender收到ack,一次发送结束。
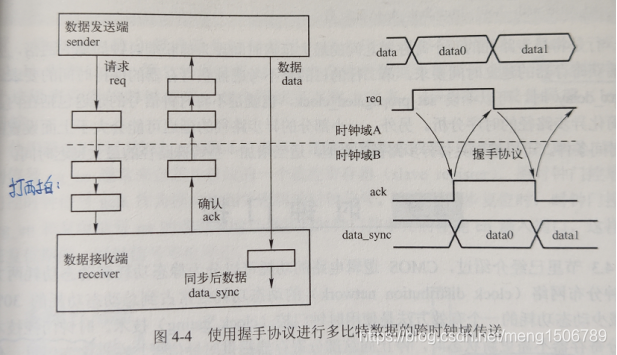
DMUX:
6.异步FIFO
/* 代码在文件AsyncFIFO.v */
仿真:
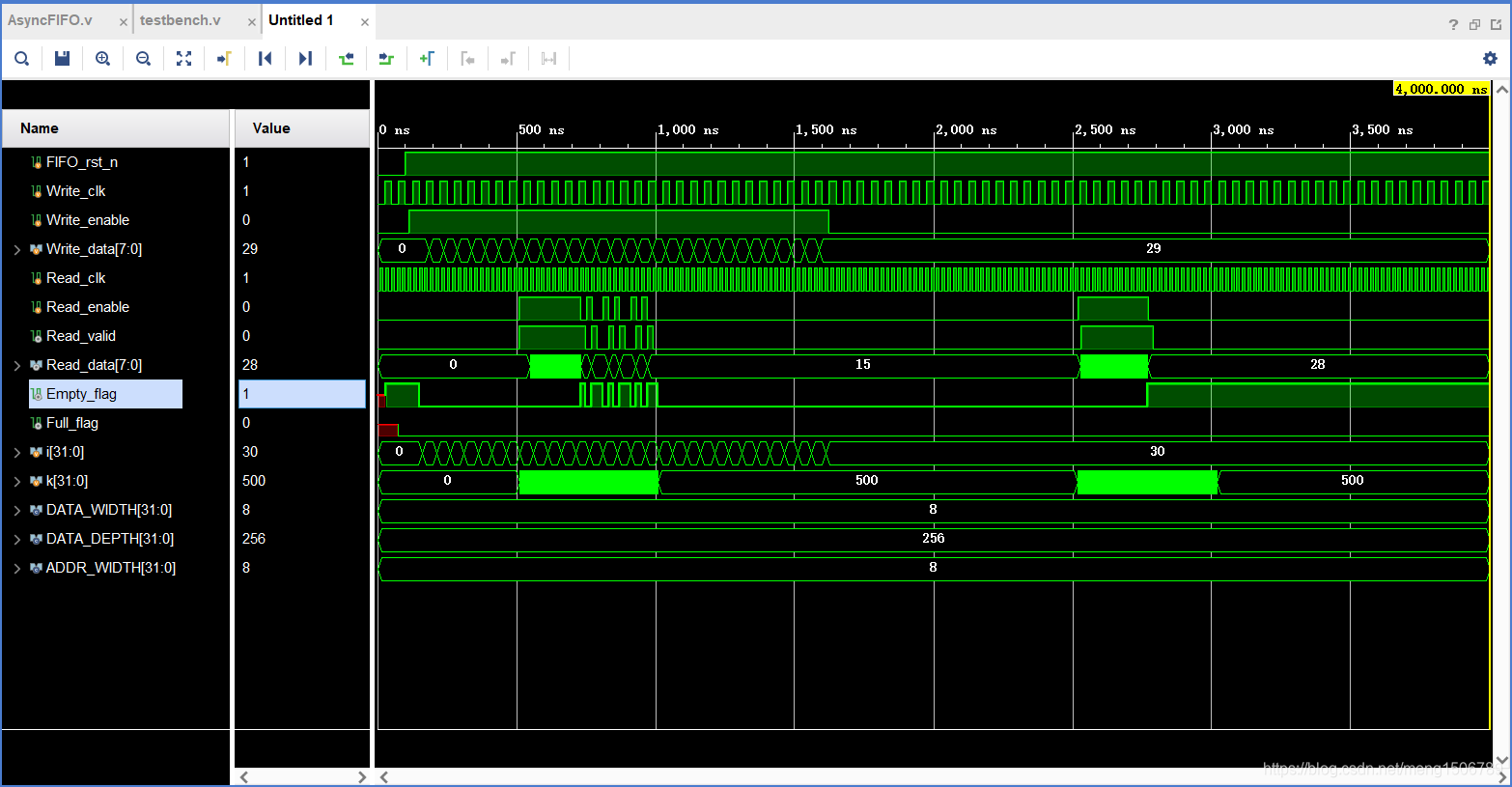
其中空满状态是使用格雷码跨时钟域来判断:
(由于格雷码每次只有1位变化,所以可以使用double clock的方式来跨时钟域)
满标志位在写时钟域判断,因为要反馈给写数据端
空标志位在读时钟域判断,因为要反馈给读数据端


其中格雷码的位宽是ADDR_WIDTH+1的:
(这样的目的是为了判断满状态)

以下面的格雷码为例,假如ADDR_WIDTH为3,读指针为0000当写指针为1100时所有地址对应的数据都被写入了(写入了一圈),则FIFO满,当读指针为其他值时同理。

`

异步FIFO最小深度计算 例题1:
写时钟80MHz,每个时钟写1byte,写一次停一次,读时钟50MHz,读一次停3次,求传输120bytes需要的FIFO最小深度是多少。
答案83bytes
异步FIFO最小深度计算 例题2:
有一个FIFO设计,输入时钟100MHz,输出时钟80MHz,输入数据模式是固定的,其中1000个时钟中有800个时钟传输连续数据,另外200个空闲。请问为了避免FIFO下溢/上溢,最小深度是多少。
答案320
解题的关键是要考虑背靠背问题

7.脉冲同步器
由于脉冲在快时钟域传递到慢时钟域时,慢时钟有时无法采样的信号,因此需要对信号进行处理,可以让慢时钟采样到脉冲信号。
/程序在pulse_sync.v文件中/
module pulse_synchronizer(
input clk1,
input clk2,
input rstn,
input pulse_in,
output reg clk1_reg,
output reg [2:0] clk2_reg,
output pulse_out
);
always @(posedge clk1 or negedge rstn) begin
if(!rstn)
begin
clk1_reg <= 1'b0;
end
else
begin
if(pulse_in)
clk1_reg <= ~clk1_reg;
end
end
always @(posedge clk2 or negedge rstn) begin
if(!rstn)
begin
clk2_reg[2:0] <=3'b000;
end
else
begin
clk2_reg[2:0] <={
clk2_reg[1:0],clk1_reg};
end
end
assign pulse_out = clk2_reg[2]^clk2_reg[1];
endmodule

注意:
快时钟域的脉冲都是单周期脉冲。
快时钟域中相邻两个脉冲的间隔时间要至少是慢时钟域的2个周期才能保证输出的同步脉冲是正确的。
8.无毛刺时钟切换
时钟切换的简单实现:使用MUX(这种可能会产生毛刺,不推荐)
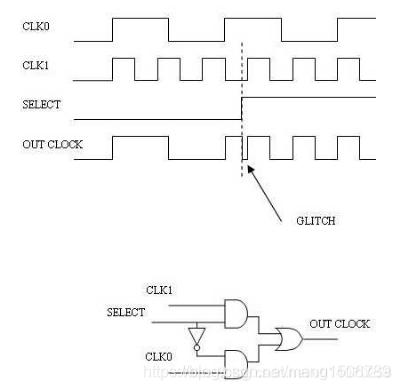
无毛刺时钟切换
插入下降沿触发触发器确保切换只发生在时钟为低电平时,引入输出反馈确保另一端的控制信号为低电平(另一端的输出关断)时发生切换。
由于sel是异步信号,前面引入两级DFF是为了同步sel信号,如果sel是同步信号,则只保留下降沿触发的DFF即可。
其中:sel1 = ~sel0; 它们只有一个为高电平。

/程序在clock_switch.v中/
module clock_switch(
input clk0,
input clk1,
input rst_n,
input select,
output DFF0_in,
output DFF1_in,
output reg [2:0] DFF0_out,
output reg [2:0] DFF1_out,
output clk_out0,
output clk_out1,
output clk_out
);
assign DFF0_in = ~DFF1_out[2] & ~select;
assign DFF1_in = ~DFF0_out[2] & select;
assign clk_out0 = clk0 & DFF0_out[2];
assign clk_out1 = clk1 & DFF1_out[2];
assign clk_out = clk_out0 | clk_out1;
always @(posedge clk0 or negedge rst_n)
begin
if(!rst_n)
begin
DFF0_out[1:0] <= 2'b00;
end
else
begin
DFF0_out[1:0] <= {
DFF0_out[0],DFF0_in};
end
end
always @(negedge clk0 or negedge rst_n)
begin
if(!rst_n)
begin
DFF0_out[2] <= 1'b0;
end
else
begin
DFF0_out[2] <= DFF0_out[1];
end
end
always @(posedge clk1 or negedge rst_n)
begin
if(!rst_n)
begin
DFF1_out[1:0] <= 2'b00;
end
else
begin
DFF1_out[1:0] <= {
DFF1_out[0],DFF1_in};
end
end
always @(negedge clk1 or negedge rst_n)
begin
if(!rst_n)
begin
DFF1_out[2] <= 1'b0;
end
else
begin
DFF1_out[2] <= DFF1_out[1];
end
end
endmodule
下面这个位置如果直接采用第一种时钟切换电路就会产生毛刺。
9.竞争冒险现象
组合逻辑电路中,同一信号经不同的路径传输后,到达电路中某一会合点的时间有先有后,这种现象称为逻辑竞争,而因此产生输出干扰脉冲的现象称为冒险。
消除竞争冒险的方法:
(1)在输出端接入滤波电容,或RC滤波
(2)单独引入一个选通脉冲(在每次电平变化时刻之后产生,并且在下次电平变化时刻之前结束,在选通脉冲持续区间输出信号,这样就避开了可能出现的冒险“毛刺”)
(3)修改逻辑设计
竞争冒险 例题:
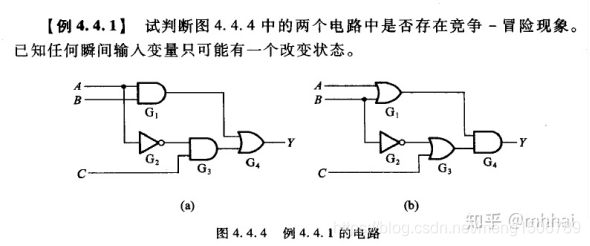
图a,改变A,则输出端Y的两路输入信号都被影响,因此存在竞争-冒险现象。图b同理,改变B,Y的两路输入信号都受影响,因此也存在竞争-冒险现象。
此类问题,每次只改变一个信号,观察该信号会不会对输出端两路以上的信号造成影响即可判断。
10.串并转换、并串转换
串并转换使用移位寄存器的方式实现。
并串转换使用寄存器存储+按位输出的方式实现。
11.分频电路(奇数、偶数分频)
偶数分频:在clk_in的上升沿计数输出即可。
奇数分频:产生50%占空比的奇数分频时钟,需要使用clk_in的下降沿采样clk_A产生clk_B。
三分频电路:
assign clk_div_3 = clk_A | clk_B;
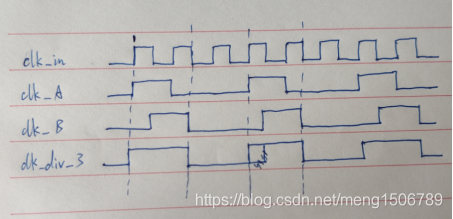
其中clk_A是非50%占空比的三分频时钟。其他奇数分频同理。
12.任意切换的时钟分频电路
例题:任意切换1-8分频,且无论奇分频还是偶分频,占空比均为50%
解析:
(1)确定输入输出
input clk,
input [3:0] div,
input rst_n,
output clk_out
(2)判断div的数值进行模式选择
div=1/2时,即不分频和二分频
div=4/6/8时,即偶数分频,计数即可
div=3/5/7时,即奇数分频,先计数,之后由下降沿采样,进行或运算产生分频时钟
(3)模式切换
判断两次输入的div数值有变化,且需要等待本次周期的波形计数输出完毕,且输出的分频时钟处于低电平状态,才可以完成模式切换。
13.综合成锁存器的情况
组合逻辑中if…else或case中的判断条件不全,或敏感列表不全时,会产生Latch,因为组合逻辑没有记忆功能。
时序逻辑中不会产生Latch,因为触发器具有存储记忆功能,且加了if或case后会生成使能端口(在D端口使用MUX即可实现使能功能)。
注意:若组合逻辑中在开头对寄存器赋了初始值,则不会产生Latch。
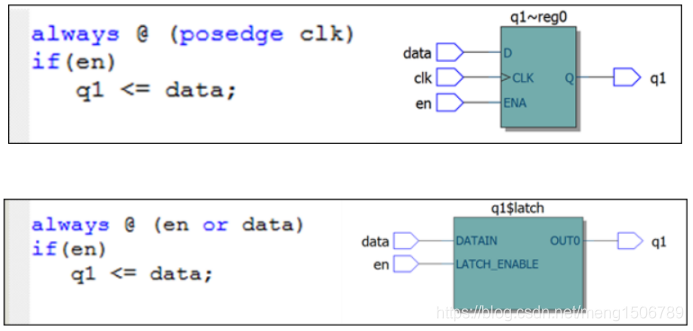
由于锁存器对毛刺敏感,很容易在信号上产生毛刺;而且也没有时钟信号,不容易进行静态时序分析,所以一般在RTL设计中不希望产生锁存器。
14.时钟门控
有两种方式:负边沿寄存器、负电平锁存器

在时钟门控中使用锁存器更好:(1)锁存器的面积小;(2)锁存器是电平触发,en信号的到来时刻可以更随意。
15.同步复位、异步复位
同步复位:复位信号只有在时钟上升沿到来时才能有效。优点:(1)因为只有在时钟有效电平到来时才有效,所以可以滤除高于时钟频率的毛刺;(2)可以使所设计的系统成为100%的同步时序电路,有利于时序分析。缺点:(1)复位信号的有效时长必须大于时钟周期,才能真正被系统识别并完成复位任务。同时还要考虑,诸如:clk skew,组合逻辑路径延时,复位延时等因素;(2)由于大多数的逻辑器件的目标库内的DFF都只有异步复位端口,所以,倘若采用同步复位的话,综合器就会在寄存器的数据输入端口插入组合逻辑,这样就会耗费较多的逻辑资源。
异步复位:无论时钟沿是否到来,只要复位信号有效,就进行复位。优点:(1)设计相对简单;(2) 因为大多数目标器件库的dff都有异步复位端口,因此采用异步复位可以节省资源。缺点:(1)复位信号容易受到毛刺的影响。 (2)在复位信号释放(release)的时候容易出现问题。具体就是说:若复位释放刚好在时钟有效沿附近时,很容易使寄存器输出出现亚稳态,从而导致亚稳态。
16.异步复位同步释放
可以解决异步复位释放时间不确定的问题。
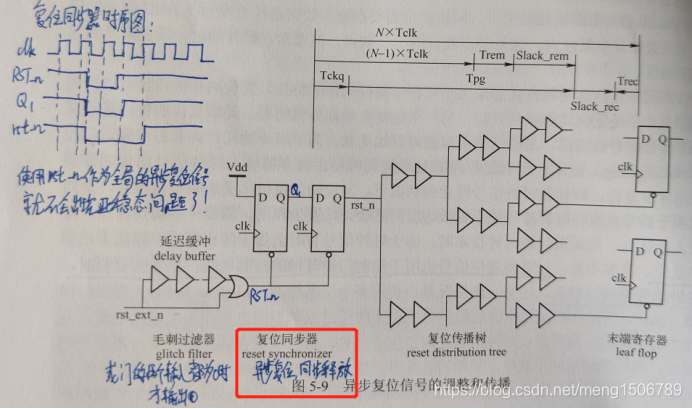
触发器的输入端接1’b1,异步复位端接外部的rst_n,第二级触发器的输出端就是异步复位同步释放。
module reset_synchronizer(
input clk,
input extern_rst_n,
output rst_n
);
reg [1:0] extern_rst_n_buff;
always@(posedge clk or negedge extern_rst_n)
begin
if(!extern_rst_n)
begin
extern_rst_n_buff <= 2'b00;
end
else
begin
extern_rst_n_buff[1:0] <= {
extern_rst_n_buff[0],extern_rst_n};
end
end
assign rst_n = extern_rst_n_buff[1];
endmodule

17.乒乓buffer
面积换速度的一种设计思想
其中同种颜色的箭头在同一时刻执行,两个MUX在灰→白→灰→白…之间切换。

乒乓操作完成数据的无缝缓冲与处理,乒乓操作可以通过“输入数据选择控制”和“输出数据选择控制”按节拍,相互配合地进行来回切换,将经过缓冲的数据流没有停顿的送到“后续处理模块”。
相当于流水线操作:输入到输出的延迟 = 写入时间+读取时间,但是写入和读取可以同时进行,中间没有停顿。
18.超前进位加法器


面积换速度:(比行波加法器速度快)
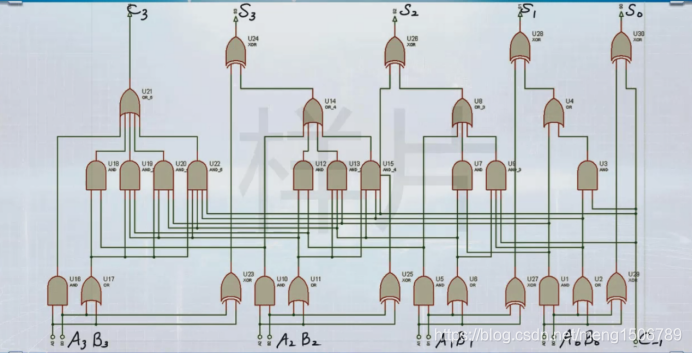
由于反向门通常快于非反向门,也可以采用NAND、NOR、NXOR、NOT来设计电路:

19.booth乘法器
布斯乘法算法(Booth’s multiplication algorithm)是计算机中一种利用二进制的补码形式来计算乘法的算法。相对于传统的累加型乘法器速度更快,面积更小。
补码一位乘法的原理:

布斯算法的实现可以通过重复地在P上加两个预设值A和 S 其中的一个,然后对P实施算术右移。设m和n分别为被乘数和乘数,再令x和y分别为m和n中的数字位数。
第一步:确定A和S的值,以及P的初始值。这三个数字的长度都应等于(x + y + 1):
对于A:以m的值填充前x位(最靠左的位),用零填满剩下的(y + 1)位;
对于S:以( - m)的值填充前x位,用零填满剩下的(y + 1)位;
对于P:用0填满最左的x位,将n的值附加在尾部;最右一位用零占位(辅助位,当i=0时i-1=-1,指的就是这个辅助位);
第二步:观察P的最右两位:
如果等于01,求出P + A的值(执行加法),忽略上溢;
如果等于10,求出P + S的值(执行减法),忽略上溢;
如果等于00,不做任何运算,在下一步中直接采用P的值;
如果等于11,不做任何运算,在下一步中直接采用P的值。
第三步:对第2步中得到的值进行算术右移一位,并将结果赋给P;
第四步:重复第2步和第3步,一共做y次;
第五步:舍掉P的最右一位,得到的即为m和n的积。

程序:
`timescale 1ns / 1ps
module BoothMultiplier
#(
parameter N=4
)
(
input clk,
input rst_n,
input start,
input [N-1:0] m,
input [N-1:0] n,
output reg [2*N:0] P,
output reg [2*N:0] A,
output reg [2*N:0] S,
output reg [7:0] state,
output reg [2*N-1:0] result,
output reg done
);
reg [7:0] cnt;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
P <= 0;
A <= 0;
S <= 0;
state <= 0;
cnt <= 0;
result <= 0;
done <= 0;
end
else
begin
case(state)
0:
begin
if(start)
begin
P[2*N:0] <= {
{
N{
1'd0}},n[N-1:0],1'b0};
A[2*N:0] <= {
m[N-1:0],{
(N+1){
1'd0}}};
S[2*N] <= ~m[N-1];
S[(2*N-1)-:(N-1)] <= (~m[N-2:0])+1;
S[N:0] <= {
(N+1){
1'd0}};
cnt <= 0;
state <= state + 1;
end
done <= 0;
end
1:
begin
case(P[1:0])
2'b01:
begin
P <= P + A;
end
2'b10:
begin
P <= P + S;
end
endcase
cnt <= cnt + 1;
state <= state + 1;
end
2:
begin
P[2*N:0] <= {
P[2*N],P[2*N:1]};
if(cnt == N)
state <= state + 1;
else
state <= 1;
end
3:
begin
result[2*N-1:0] <= P[2*N:1];
state <= state + 1;
end
4:
begin
done <= 1;
state <= 0;
end
default: state <= 0;
endcase
end
end
endmodule

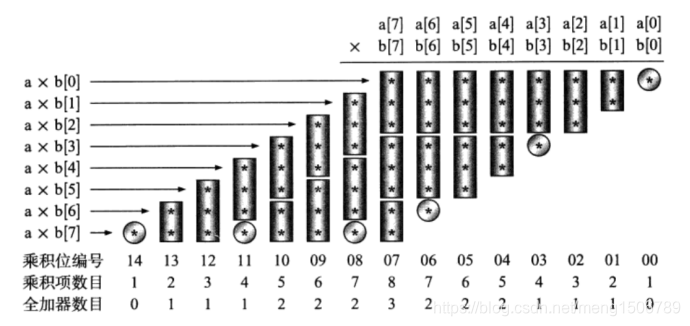
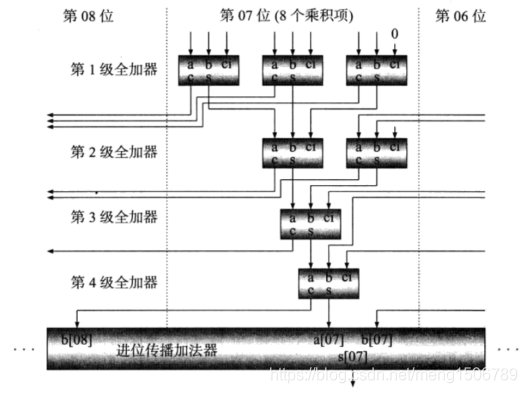
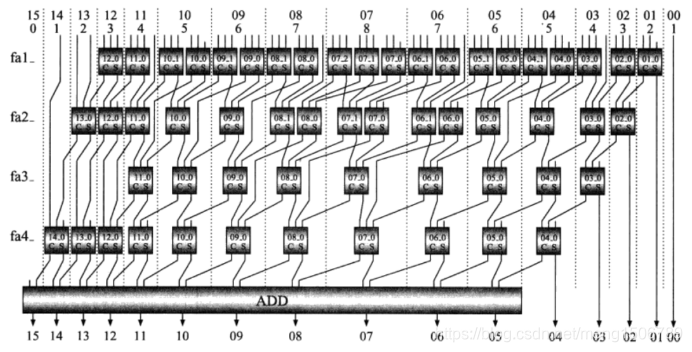
20.Wallace树型乘法器
Wallace在1964年提出采用树形结构bai减少多个数累du加次数的方法,成为wallace树结构加法器。Wallance树充分利用全加器3-2压缩(3输入2输出)的特性,随时将可利用的所有输入和中间结果及时并行计算,大大节省了计算延时。
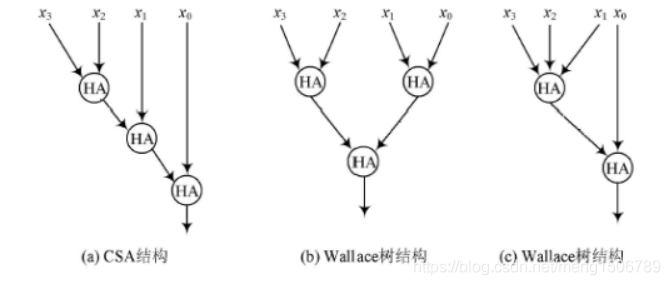
Wallance乘法器:(8位x8位乘法器)
21.除法器
原理与我们在草稿纸上计算的步骤是一样的,通过移位、相减的步骤。
对于32位的无符号数除法,被除数a除以除数b,他们的商和余数一定不会超过32位,首先将a转换成高32位为0,低32位为a的temp_a,再将b转换成高32位为b,低32位为0的temp_b。在每个周期开始前,先将temp_a左移一位,末尾补0,然后与b相比较看是否大于b,若大于b,则temp_a=temp_a-temp_b+1,否则继续往下执行。上面的移位操作、比较和减法要执行32次,执行完成后得到的temp_a的高32位为两数a和b相除的余数,低32位表示商。具体的算法流程可从下图的例子中得到体现。
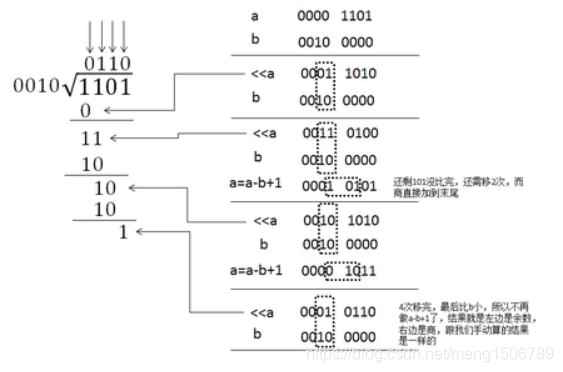
程序:
`timescale 1ns / 1ps
module Divider(
input clk,
input rst_n,
input start,
input [31:0] a,
input [31:0] b,
output [31:0] shang,
output [31:0] yushu,
output reg done
);
reg [63:0] temp_a;
wire [63:0] temp_b;
reg [7:0] state;
reg [7:0] cnt;
assign temp_b[63:0] = {
b[31:0],32'd0};
assign shang[31:0] = temp_a[31:0];
assign yushu[31:0] = temp_a[63:32];
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
temp_a <= 0;
state <= 0;
cnt <= 0;
done <= 0;
end
else
begin
case(state)
0:
begin
if(start)
begin
state <= state + 1;
temp_a[63:0] <= {
32'd0,a[31:0]};
end
cnt <= 0;
done <= 0;
end
1:
begin
if(cnt >= 32)
begin
state <= 3;
cnt <= 0;
end
else
begin
state <= state + 1;
cnt <= cnt + 1;
temp_a[63:0] <= {
temp_a[62:0],1'b0};
end
end
2:
begin
state <= 1;
if(temp_a[63:0] > temp_b[63:0])
temp_a <= temp_a-temp_b+1;
end
3:
begin
state <= 0;
done <= 1;
end
default: state <= 0;
endcase
end
end
endmodule
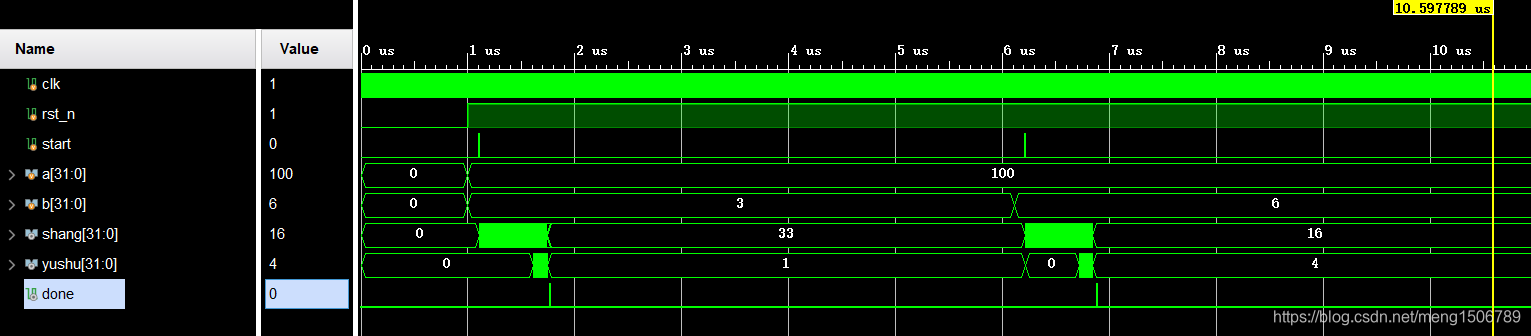
22.线性反馈移位寄存器LFSR
例题:一个线性反馈移位寄存器(LFSR)的特征多项式为F(x)=x4+x+1,初始态为全1,则以下哪些描述是正确的?
A. 输出的m-序列为11100101
B. 该LFSR包含四个寄存器
C. 寄存器的状态不会出现全零
D. 该LFSR能够产生的不重复序列最长为15位
答案:BCD
下图是多项式对应的电路图:

输入初始为:1111

4个寄存器序列依次为:
1111 -> 0111 -> 1011 -> 0101 -> 1010 -> 1101 -> 0110 -> 0011 -> 1001 -> 0100-> 0010 -> 0001 ->1000 -> 1100 -> 1110 ->1111 按(x1 x2 x3 x4)的顺序写的数值
OUT 序列依次为:111101011001000
23.Verilog有符号数运算
(1)有符号数与无符号数的运算
在一个verilog叙述中只要有一个无号数的操作数,整个算式将被当成无号数进行计算。
因此需要使用$signed()进行类型转换:
input [7:0] a;
input signed [7:0] b;
output signed [16:0] o;
// The $signed({1’b0, a}) can convert the unsigned number to signed number
assign o = $signed({1’b0, a}) * b;
(2)不同位宽有符号数的运算
input signed [15:0] a;
input signed [7:0] b;
output signed [16:0] o;
//扩展符号位
assign o[16:0] = a[15:0] +{
{8{b[7]}},b[7:0]};
24.RTL代码对应的电路
各种门电路(与或非、NAND、NOR、异或XOR)
三态门
MUX
触发器
锁存器
25.数字IC设计步骤及软件
功能规格定义
架构设计(C\C++ model)
微架构设计(RTL code)(软件:VCS、DVE、Modelsim)
逻辑功能验证(动态功能验证)(软件:VCS、DVE、Modelsim)
综合(形成网表:逻辑门、触发器之间的连线关系。要使面积尽量小,并努力满足同步电路时序要求)(软件:Design Compiler)
形式验证(验证网表功能与RTL是否对等,静态功能验证)(软件:Formality)
可测试性设计DFT(软件:Tessent)
版图布局布线(软件:IC Compiler)
时序分析(静态:分析setup\hold time;动态:反馈到网表,进行网表优化)(软件:Prime Time)
26.常见的低功耗设计方法
静态功耗:电路状态稳定时的漏电流导致的功耗,其数量级很小。
动态功耗:指电容充放电功耗和短路功耗,是由电路中信号的翻转造成的。
低功耗设计方法:
针对静态功耗:
(1)Power Gating(降低电路在空闲状态下的静态功耗);
(2)Mutli-Vdd(不同模块使用不同供电电压);
(3)Mutli-Vth(阈值电压高:MOS的漏电电流小。阈值电压低:MOS的开关速度快);
针对动态功耗:
(1)Clock Gating(时钟门控,减少信号翻转次数);
(2)操作数分离(增加一些选择器件,如果某个操作数不需要使用的话就不选择它以及不进行之前计算这个操作数所需要的操作);
(3)DVFS(Dynamic Voltage Frequency Scale,动态控制电压和频率,需要比较强大的designer来support)
27.N倍频的verilog模型
利用下面的单稳态触发器模型可以实现一个倍频的仿真模型,但是不可综合。
always@(clk) //注意是电平敏感的
begin
clk_x2 = 1;
#2;
clk_x2 = 0;
end
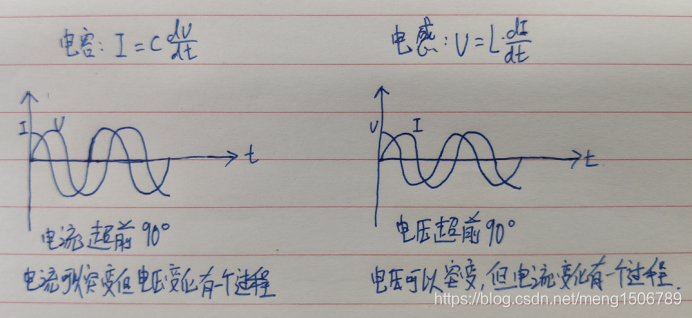
28.电容与电感导致的相位差问题
29.根据VOH,VOL,VIH,VIL求电压容限
电压容限是指驱动器的输出与接收端的输入在最坏的情况下的灵敏度之间的差值。
以高电平输出和输入关系来看,最小的输出值和最小允许输入值之间存在一个差值,这个值就是高电平的电压容限;低电平电压容限同理。
高电平电压容限 = VOHmin - VIHmin
低电平电压容限 = VILmin - V0Lmin

30.动态,静态,功能,时序:验证
动态功能验证:功能仿真,包括RTL仿真和后仿。动态是指通过testcase的激励来触发电路的动态行为,观察行为是否满足预期。缺点是需要大量的testcase来覆盖各种情况。
静态功能验证:形式验证。在RTL编译为网表文件后,用数学的方法对所有情况进行分析,来验证网表与RTL的功能是否等价。这种验证不需要激励,速度快,并能保证所有逻辑都被验证。
动态时序验证:后仿真。利用PR反馈的时序信息(SDF)再一次做门级的功能仿真,在考虑时序延时之后,还能满足时序和功能的正确性。将提取出的时序参数反向标注到门级网表,使用逻辑验证的方式进行动态时序分析。因为速度很慢,一般只做主要功能的后仿,作为功能和时序验证的辅助检查。
静态时序验证:静态时序分析。在RTL编译为网表文件后,根据建立和保持时间的原理,分析设计中的所有时序路径,速度快,完整的时序约束可以保证不会漏掉任何时序路径。
31.JK触发器、T触发器
JK触发器:

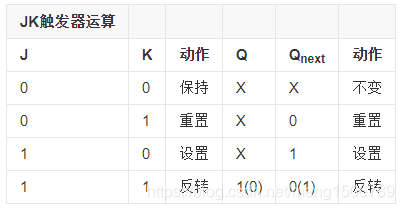
例题:TTL门电路组成的JK触发器,时钟端接5khz脉冲,J与K悬空,则输出Q的频率为
A、2.5khz
B、无法预测
C、5Khz
D、10khz
答案:A
TTL门电路的悬空端相当于接高电平,Jk触发器的状态转移方程Q’=JQ’+K’Q=Q’,即JK触发器的状态会随着时钟信号的上升沿的到来而翻转,所以频率应为CP的一半。
T触发器:
当T=0时输出状态不变,T=1时翻转


32.产生序列信号需要触发器的个数
例题:欲产生序列信号11010111,则至少需要()级触发器。
A 3
B 4
C 5
D 2
个人选择A
因为检测8个信号,用2^3,就可以实现8个状态
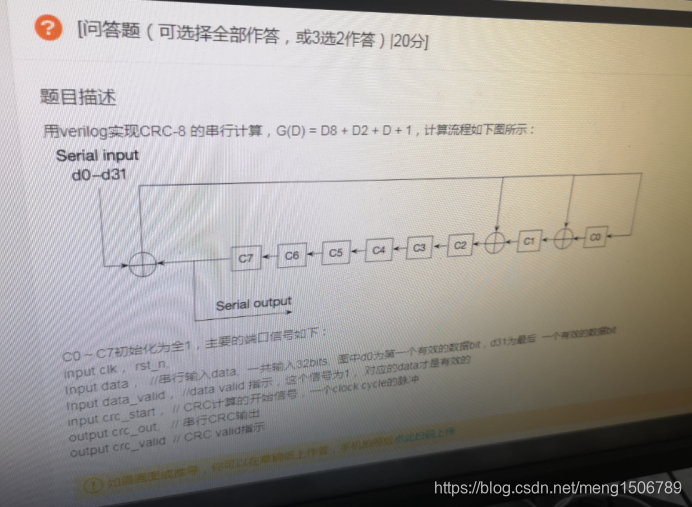
33.CRC循环冗余校验
将寄存器和组合逻辑用verilog描述出来即可。
34.如何评价一个芯片
PPA:Performance、Power、Area
(1)性能:主频,指令/s,计算能力
(2)功耗
(3)面积:逻辑门、触发器的个数,制造工艺
35.如何提升总线吞吐速率
(1)增加数据位宽
(2)提高时钟频率
(3)地址和数据使用独立通道
(4)支持outstanding模式
(5)支持burst模式
(6)可以乱序传输、内插传输
·
二、提升篇
1.数字IC验证的流程
Verification spec :
test plan : test case定义
Common
Corner:极端的
Special/abnormal
UVM平台架构设计
搭建UVM平台
写测试用例:初期需要1个1个case去调试:看波形debug(bug包括RTL和UVM的)
回归测试:regression,100个以上的case不停的跑
(通常用脚本来实现,挂在服务器上跑,出错就email to you)
覆盖率(Coverage):
①code coverage:所有RTL代码都运行了一次,一般要达到95%以上
②function coverage:功能覆盖率,根据features定义的功能来测试
③Assertion coverage:断言覆盖率
2.UVM架构和数据流
(1)UVM架构
UVM的树结构如下图所示,其中每一个节点代表一个类的实例(对象)。
uvm_root类是UVM结构中自带的,不需要创建。
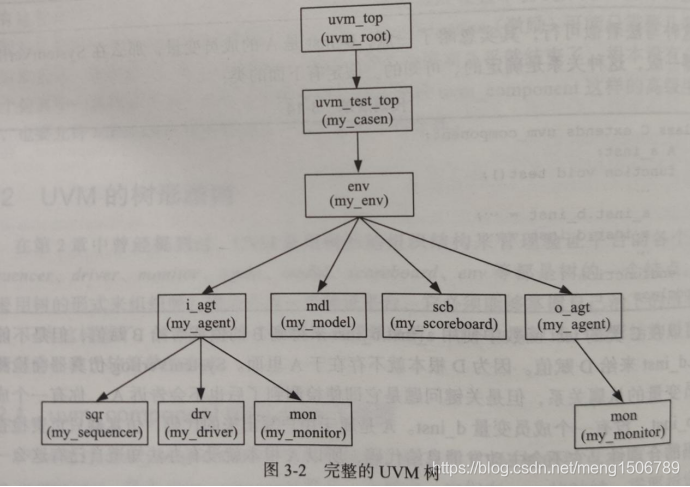
UVM中每一个类中包含几个内部的主要的函数:
new函数:用于对象的初始化,相当于C++中的构造函数。
build_phase函数:用于执行一些初始操作,构建对象之间的联系关系。在对象初始化后自动运行,不需要调用。
main_phase函数:主要的任务都在main_phase中执行。当整个程序开始启动时自动运行,不需要调用。
connect_phase函数:用于连接,不同实例之间的fifo的analysis_export(发送端)和blocking_get_export(接收端)。当整个程序开始启动时自动运行,不需要调用。
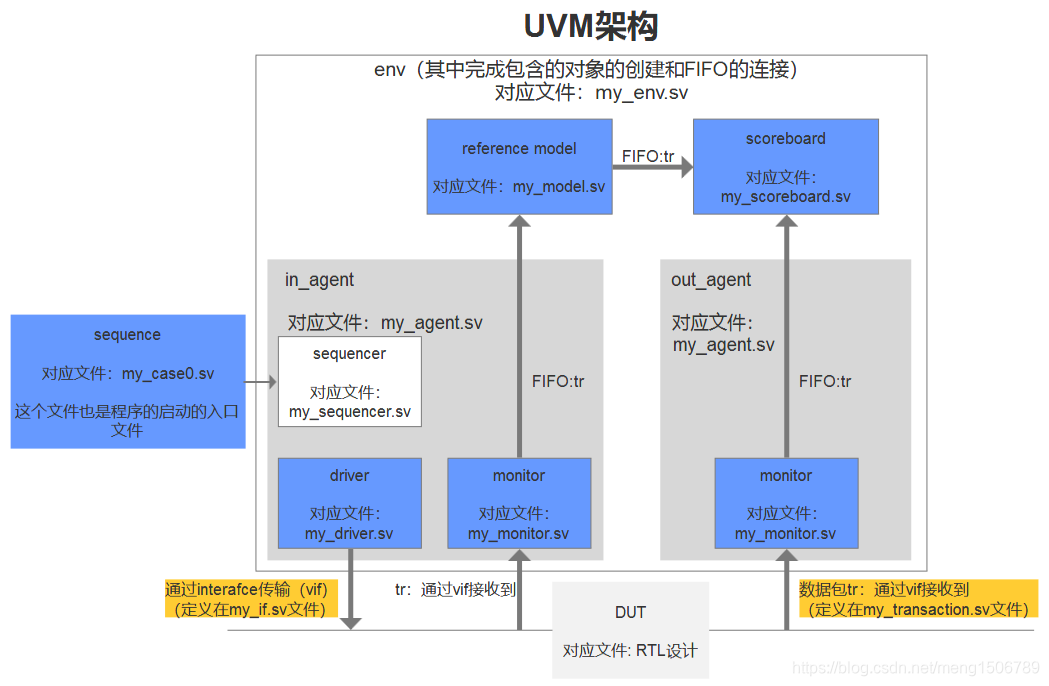
UVM的架构、对象之间的调用关系、数据传输方向(箭头)和数据传输的方式(箭头上的标注)如下图所示。
在测试其他模块时我们需要修改的部分是其中蓝色和黄色标注的部分,具体修改的内容在下面介绍。
其他部分按照程序模版即可,不需要修改。
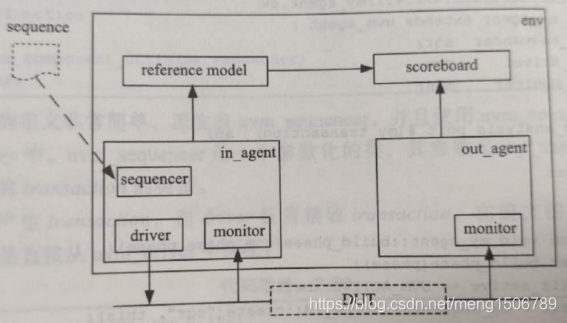
(2)UVM数据流
如下所示,箭头代表数据传送的方向。最终的数据流入scoreboard中。
3.SoC基本架构
微处理器、DMA、高带宽片上RAM存储器、高带宽存储器接口、AHB总线、AHB-APB桥、APB总线、SPI、I2C、UART、GPIO等
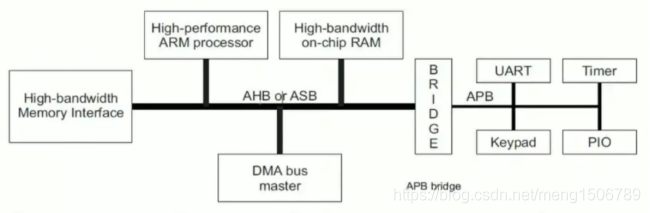
其中AHB可以换成AXI4,APB可以换为AXI4-Lite。
4.AXI4、AXI4-Lite、AXI4-Stream
AXI4、AXI4-Lite的5个通道:
写地址通道、写数据通道、写响应通道、读地址通道、读数据通道
总线的构成:数据总线、地址总线、控制总线、电源线和地线
各个通道中每个信号的具体功能可以查看axi_spec:
https://static.docs.arm.com/ihi0022/g/IHI0022G_amba_axi_protocol_spec.pdf?_ga=2.83582867.447931395.1591251023-1939436544.1591251023

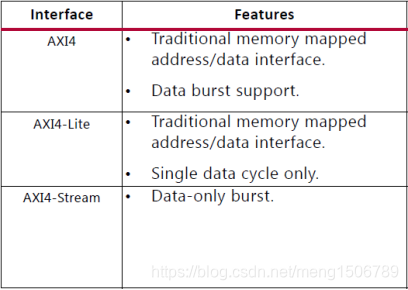
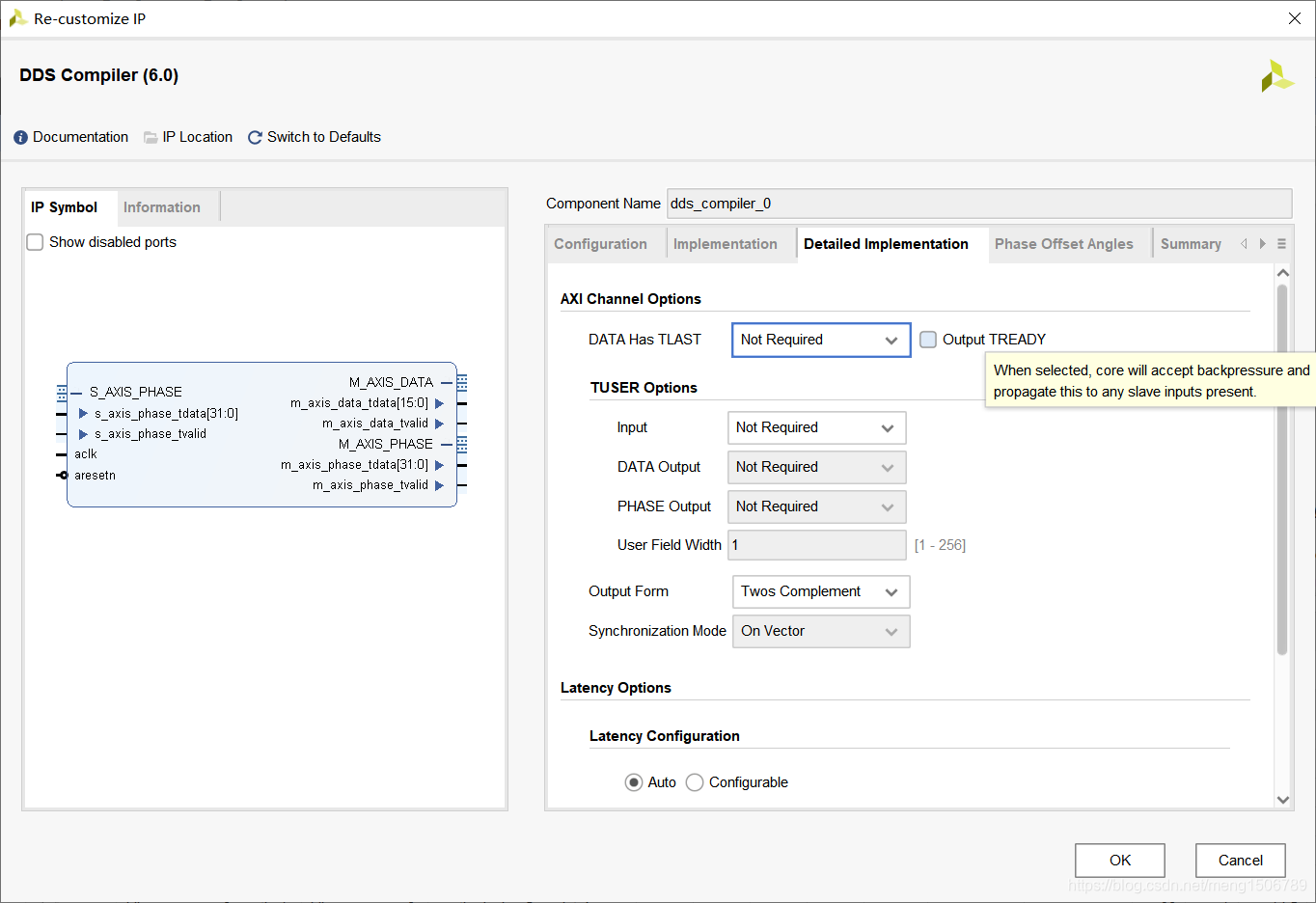
AXI4支持最大256个数据的突发传输(burst);AXI4-Lite只支持1个数据的突发传输(不支持突发传输,每个地址只能对应一个数据),适用于低速外设;AXI4-Stream没有读写地址通道,支持数据的连续传输,适用于FIFO、DDS等结构。
AXI4——For high-performance memory-mapped requirements.
AXI4-Lite——For simple, low-throughput memory-mapped communication (for example, to and from control and status registers).
AXI4-Stream——For high-speed streaming data.
AXI4写数据:(使用状态机先写入地址,再进行burst写入数据,最后读取写响应)
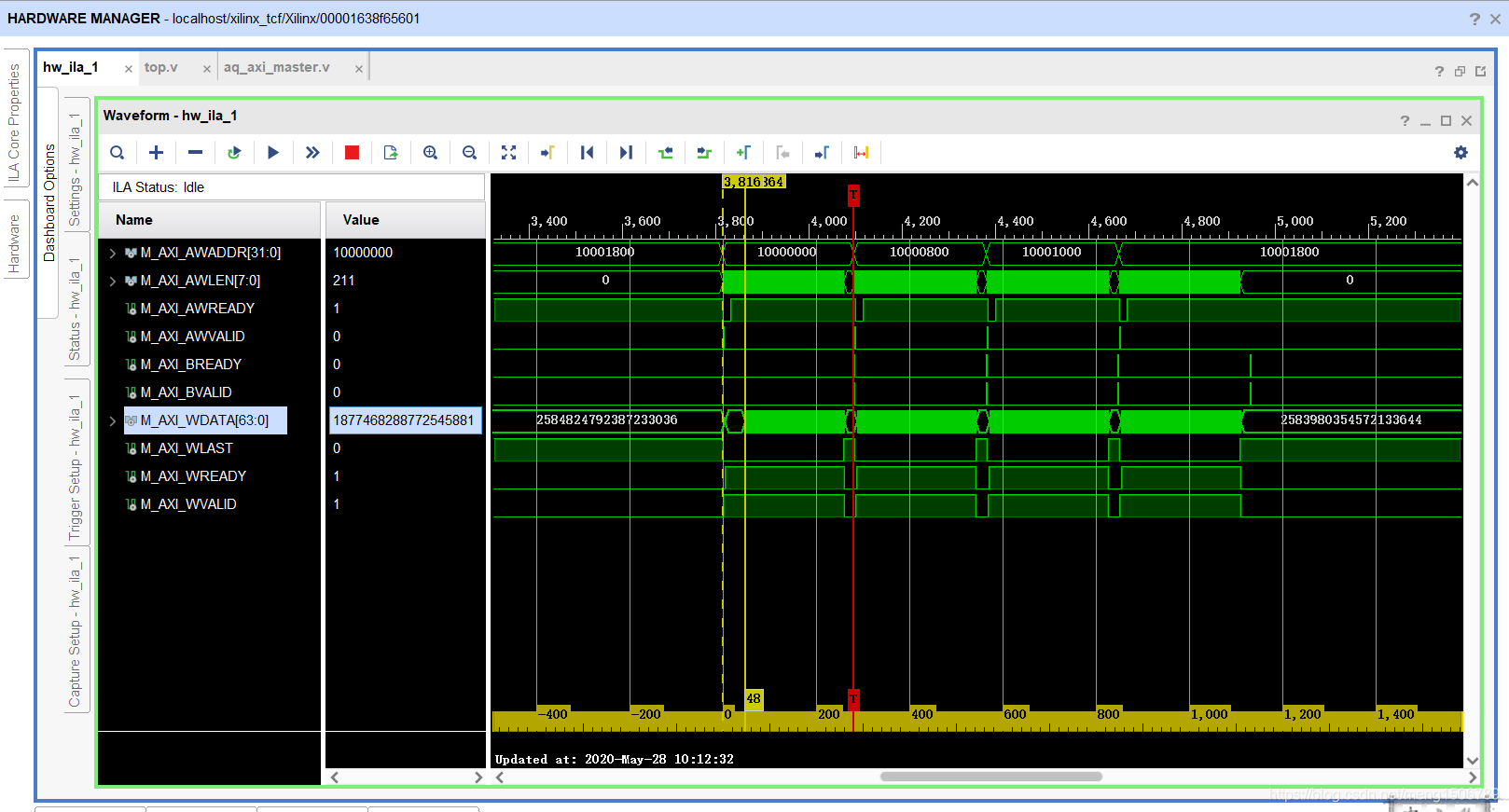
AXI4-Lite接口的UART IP核–写数据:(可以看出AWREADY和WREADY是同时反馈的,表示地址和数据是同时写入;BVALID在下一个时钟返回)
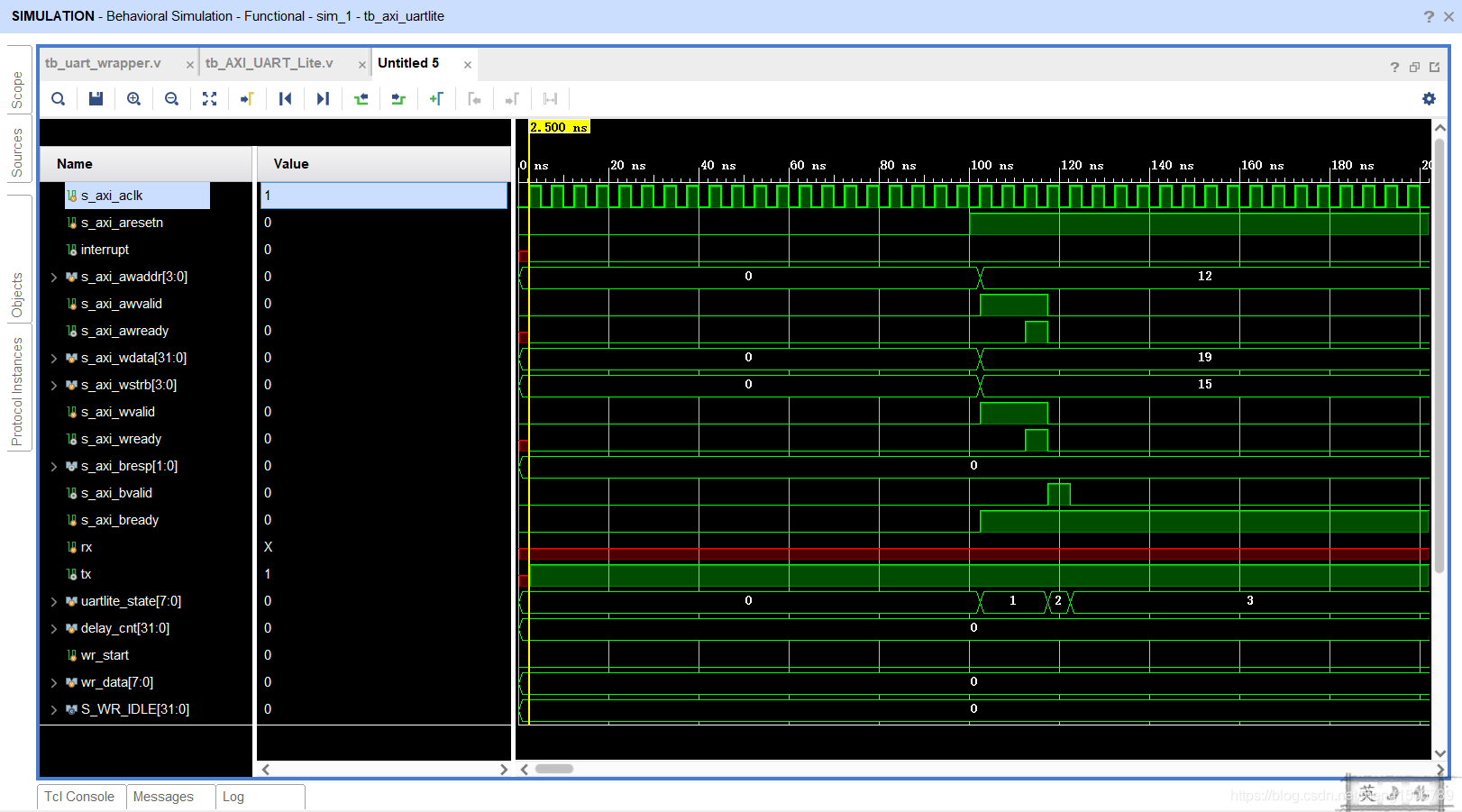
AXI-Stream接口的DDS IP核:(只要valid和ready同时为1,就一直通过时钟写入数据)
Outstanding:
Master 不必等待命令执行结束就可以发送下一命令

Out-of-Order:(AXI3 only)
对于相同ID的指令,必须要顺序完成;对于不同ID的指令,可以乱序完成。

Interleaving:(AXI3 only)
乱序传输时不同ID之间的数据可以内插,但是要保证每个ID的数据顺序。

5.UART、SPI、I2C
UART:

SPI:(片选->写寄存器地址->写寄存器;片选->写寄存器地址->读寄存器)

I2C:(两个信号开漏输出,需加上拉电阻才可以输出高电平,线与逻辑)


6.PCI、PCIe、DDR
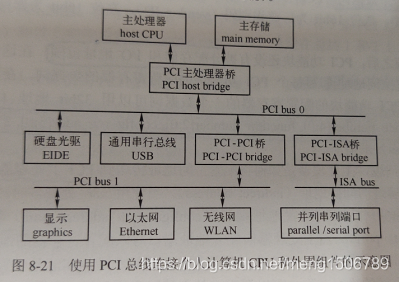
PCI:
外围组件互联(Peripheral Component Interconnect)
PCI总线采用双向、多接点、并行连线方式,以及单独的时钟信号的方式,不适于高速传输。

PCIe:
PCI Express。
PCIe采用点对点、双单向、串行、自同步、LVDS的通信方式。


DDR:
SDRAM(Synchronous Dynamic Random Access Memory)同步动态随机访问存储器。
(所谓“随机存取”,指的是当存储器中的消息被读取或写入时,所需要的时间与这段信息所在的位置无关。相对的,读取或写入顺序访问(Sequential Access)存储设备中的信息时,其所需要的时间与位置就会有关系(如磁带)。 )
DDR SDRAM(Double Data Rate SDRAM)双倍速率同步动态随机存储器。SDRAM在一个时钟周期内只传输一次数据,它是在时钟上升期进行数据传输;而DDR则是一个时钟周期内可传输两次数据,也就是在时钟的上升期和下降期各传输一次数据。

7.计算机体系结构:五级流水
取指令、指令译码、执行指令、访存取数、结果写回
取指IF -> 译码ID -> 执行EX -> MEM(从内存获取数据) -> WB(把ALU计算后的数据导出到通用寄存器堆)
F->fetch、D->decode、E->execute、M->memory、W->writeback
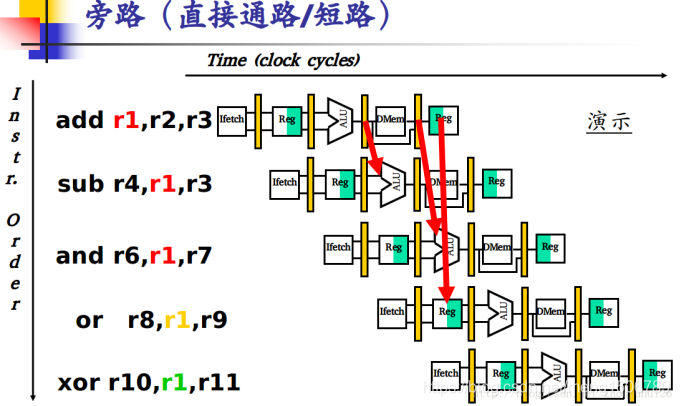
8.计算机体系结构:定向技术(旁路)
旁路技术用于解决流水线中的数据冲突:

针对数据冲突,ALU(逻辑运算单元)的结果总是从EX/MEM或MEM/WB寄存器反馈至下一ALU:
9.计算机体系结构:分支预测
分支预测器是一种数字电路,在分支指令执行前,根据之前的历史运行记录,猜测哪一个分支会被执行:
如果猜错了,处理器要flush掉pipelines, 回滚到之前的分支,然后重新热启动,选择另一条路径;
如果猜对了,处理器不需要暂停,继续往下执行。
可以节省分支状态切换的时间,能显著提高pipelines的性能。
10.计算机体系结构:Cache
Cache存储器,电脑中为高速缓冲存储器,是位于CPU和主存储器DRAM(Dynamic Random Access Memory)之间,容量较小但速度很高的存储器,通常由SRAM(Static Random Access Memory 静态存储器)组成。
CPU的速度远高于内存,当CPU直接从内存中存取数据时要等待一定时间周期,而Cache则可以保存CPU刚用过或循环使用的一部分数据,如果CPU需要再次使用该部分数据时可从Cache中直接调用,这样就避免了重复存取数据,减少了CPU的等待时间,因而提高了系统的效率。Cache又分为L1Cache(一级缓存)和L2Cache(二级缓存),L1Cache主要是集成在CPU内部,而L2Cache集成在主板上或是CPU上。
ZYNQ的Cache结构:
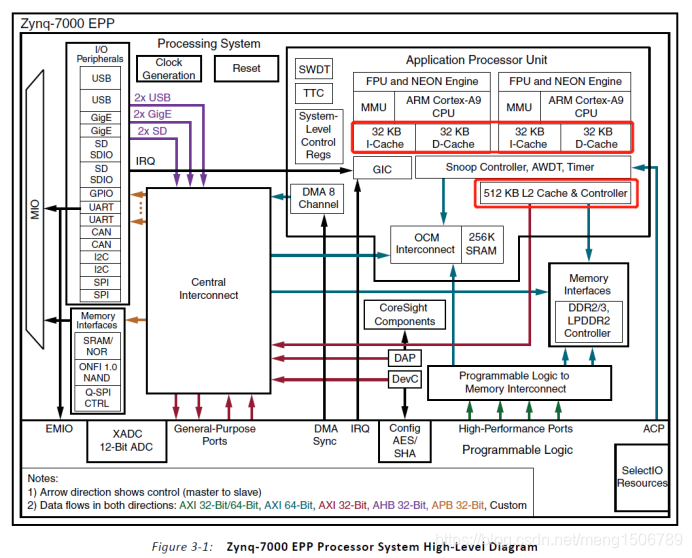
I-Cache和微处理器的接口以及I-Cache和L2 I-Cache的接口都是单向的。D-Cache和微处理器的接口以及D-Cache和L2 Cache的接口是双向的。这样处理的原因在于I-Cache存储的是指令,不需要更改所存储的数据的值。而D-Cache中存储的是数据,其值会根据指令操作的不同而改变。
11.计算机体系结构:单周期CPU和多周期CPU
1)单周期的CPU会在一个时钟周期内完成所有的工作,既从指令取出,到得到结果,全部在一个时钟之内完成,因此时钟周期是耗时最长的指令所需的时间。
2)多周期CPU的设计是将整个CPU的执行过程分成几个阶段,每个阶段用一个时钟(这个时钟频率可以很快)去完成。不仅能提高CPU的工作频率,还为组成指令流水线提供了基础。
3)在多周期CPU设计的基础上,利用各阶段电路间可并行执行的特点,让各个阶段的执行在时间上重叠起来,这种技术就是流水线技术。