前言
这个主要是在centos7下搭建hadoop2.8.3,对hadoop的搭建进行了比较详细的记录,对网上和我遇到的一些错误进行了记录和解决,虽然搭建可能不是太难,但是第一次搭建,也遇到了很多错误,不过用了一个晚上加一个下午搭建成功了,记录一下希望可以帮助别的学习的小伙伴。
准备工作
Java环境 jdk1.8

hadoop2.8.3
修改主机名
关闭防火墙

创建用户hadoop
开始
- 修改虚拟机网络配置NAT,设置虚拟机子网段
修改方法:本机搜索->虚拟网络编辑

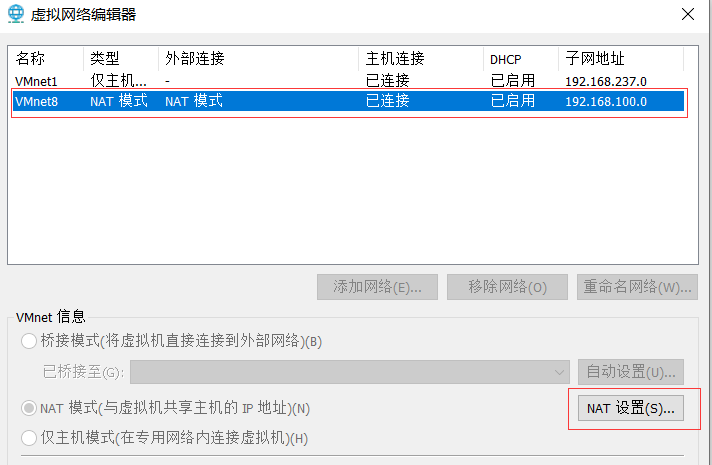
- 这里修改一下默认的子网网段,也就是下面的192.168.100.,我以前的网段是192.168.85.。记住这里的网段ip地址,在后文虚拟机中配置需要。
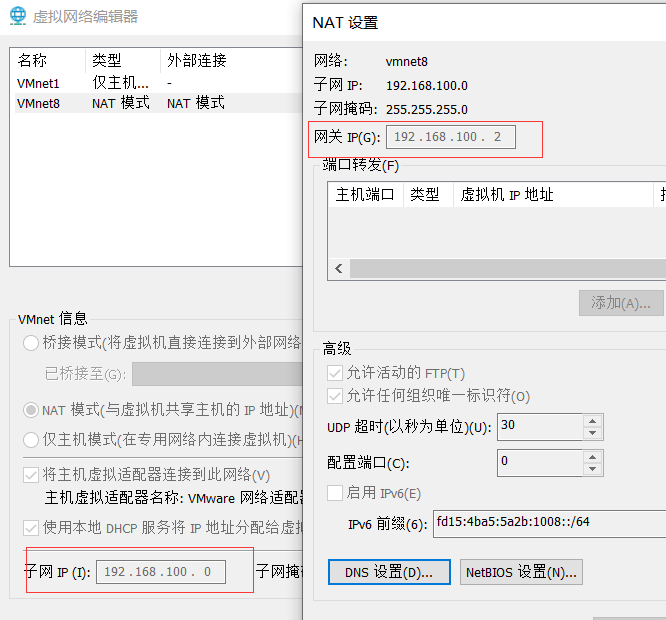
- 修改子网ip地址后在虚拟机中对应配置的ip就应该在这个网段。

- 修改主机名
修改主机名,有两种修改方式一种是临时修改,重启后失效,一种是永久性修改。
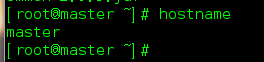
先查看本机主机名:
root@master ~]# hostname
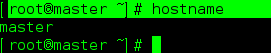
我这个修改后的主机名,你们在没有修改前应该是localhost.localhost
这里我建议大家使用临时修改即可。
[root@master ~]# hostname master
想永久修改可以参考:https://www.cnblogs.com/zhangwuji/p/7487856.html
- 关闭防火墙
关闭可以参考,这里是centos7的关闭方法:https://blog.csdn.net/ytangdigl/article/details/79796961
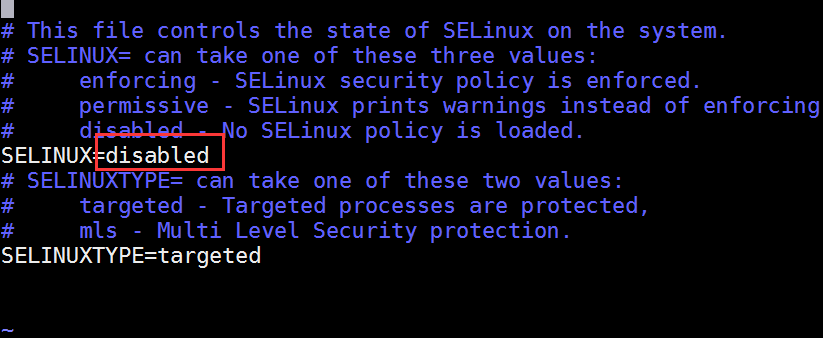
- 这里关闭防火墙的同时帮selinux也关闭一下。selinux是Linux一个子安全机制。
vim /etc/sysconfig/selinux
- 创建用户hadoop,授予root权限。
这个是基本linux命令,不会可以查看百度,比较简单。
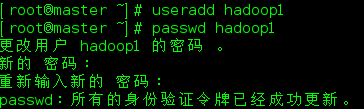
- 因为我已经创建过了hadoop,这里我拿hadoop1创建一下。
[root@master ~]# useradd hadoop1
[root@master ~]# passwd hadoop1
- 给hadoop1用户sudo权限,赋予sudo权限后,我们在执行命令时要在前面加上一个sudo
[root@master ~]# vim /etc/sudoers
添加语句
root ALL=(ALL) ALL
hadoop1 ALL=(root) NOPASSWD:ALL

- 查看当前用户
[root@master ~]# cat /etc/passwd

- 测试一下用户:su

- 安装jdk
- 安装jdk比较简单,我这里就不过多介绍了,这里要记住jdk的安装路径。
- 卸载现有jdk
- 查询是否安装Java软件:
rpm -qa | grep java
- 如果安装的版本低于1.7,卸载该JDK:
sudo rpm -e 软件包
- 将jdk安装包托到虚拟机中,解压。这里我们创建一个目录用于保存软件。
mkdir -p /opt/modulel
将解压后的Jdk放到这个目录下,防止忘记Java的安装位置。
- 配置JDK环境变量
打开/etc/profile文件
sudo vi /etc/profile
在profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
- 让修改后的文件生效
source /etc/profile
- 测试JDK是否安装成功
Java -version

- 安装hadoop
安装hadoop之前一定要确保自己的jdk安装没有问题。否则hadoop无法正常运行。
- 下载
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
- 解压,还是将hadoop解压到上文中的/opt/module中。
- 打开/etc/profile文件
sudo vi /etc/profile
在profile文件末尾添加JDK路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2(这个改成你的hadoop版本)
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 保存后退出
- 让修改后的文件生效
source /etc/profile
- 测试是否安装成功
hadoop version (注意没有-)

hadoop运行
- Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式
- 这里主要使用本地模式,和伪分布模式运行。
本地运行****模式
- 官方Grep案例
- 在hadoop2.8.3文件下创建一个文件夹wcinput
mkdir wcinput
- 在wcinput文件下创建一个wc.input文件
cd wcinput
touch wc.input
- 编辑wc.input文件
hadoop yarn
hadoop mapreduce
atguigu
atguigu
- 回到Hadoop目录/opt/module/hadoop-2.8.2
- 执行程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
解释一下这个语句的意识:这个是hadoop程序。这个jar包是hadoop自带的一个文件,wordcount案例 wcinput是输入的文件夹 后面是输出到那个文件夹。
- 查看结果
cat wcoutput/part-r-00000
atguigu 2
hadoop 2
mapreduce 1
yarn 1
本地运行成功
伪分布式运行模式
- 步骤
- 配置集群
- 启动、测试集群增、删、查
- 执行WordCount案例
- 配置集群
配置:hadoop-env.sh添加JAVA_HOME路劲
export JAVA_HOME=/opt/module/jdk1.8.0_144
- 配置:core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master(你的主机名):9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>(这个是用来存放hadoop执行生成的数据文件夹)
</property>
- 配置:hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property
- 启动集群
- 格式化NameNode(第一次启动时格式化,以后就不要总格式化),这个要注意一下,不要经常格式化,经常格式化容易导致出现后面的节点对应错误。
- 启动NameNode
sbin/hadoop-daemon.sh start namenode
- 启动DataNode
sbin/hadoop-daemon.sh start datanode
- 启动SecondaryNameNode
sbin/hadoop-daemon.sh start secondarynamenode
- JPS命令查看是否已经启动成功,有结果就是启动成功了
输入jps出现
3034 NameNode
3233 Jps
3193 SecondaryNameNode
3110 DataNode
表示成功
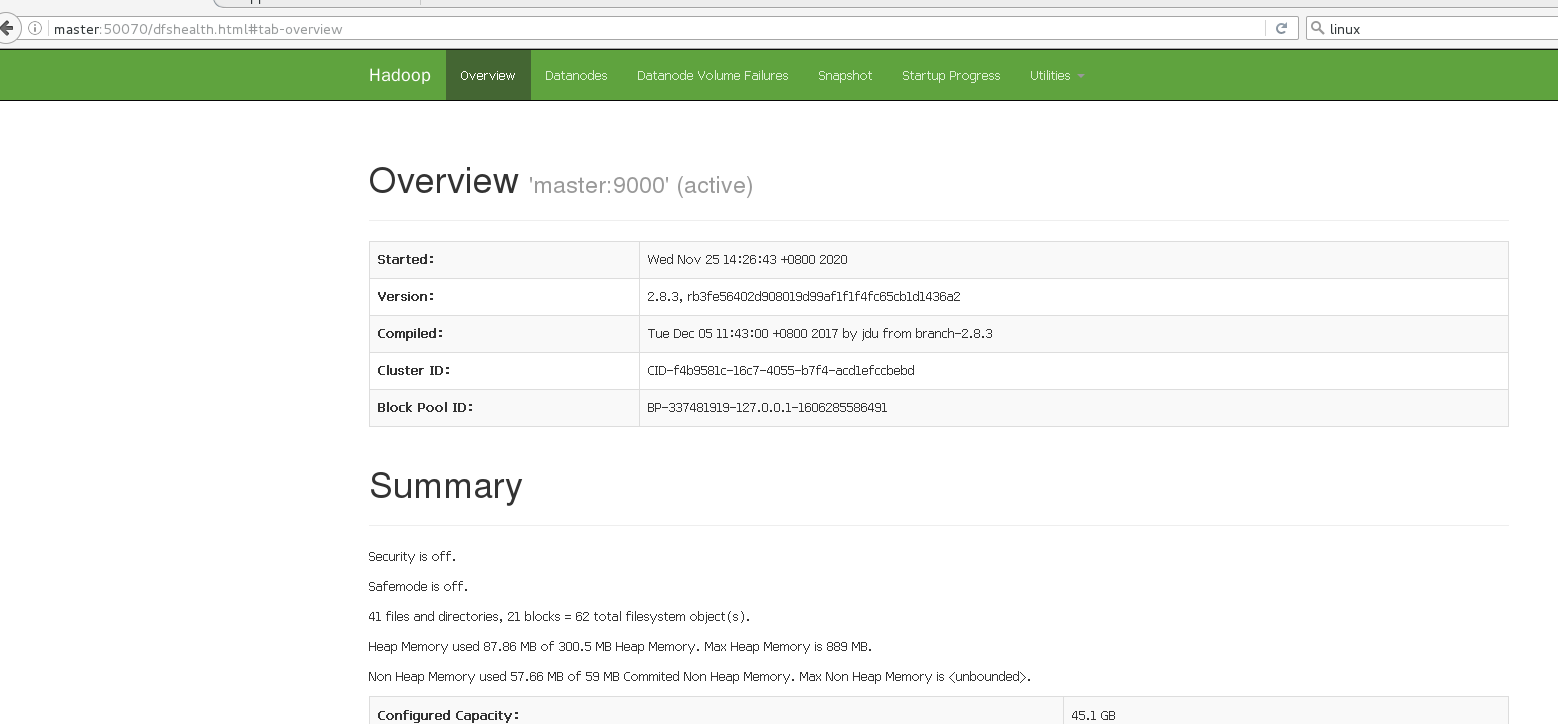
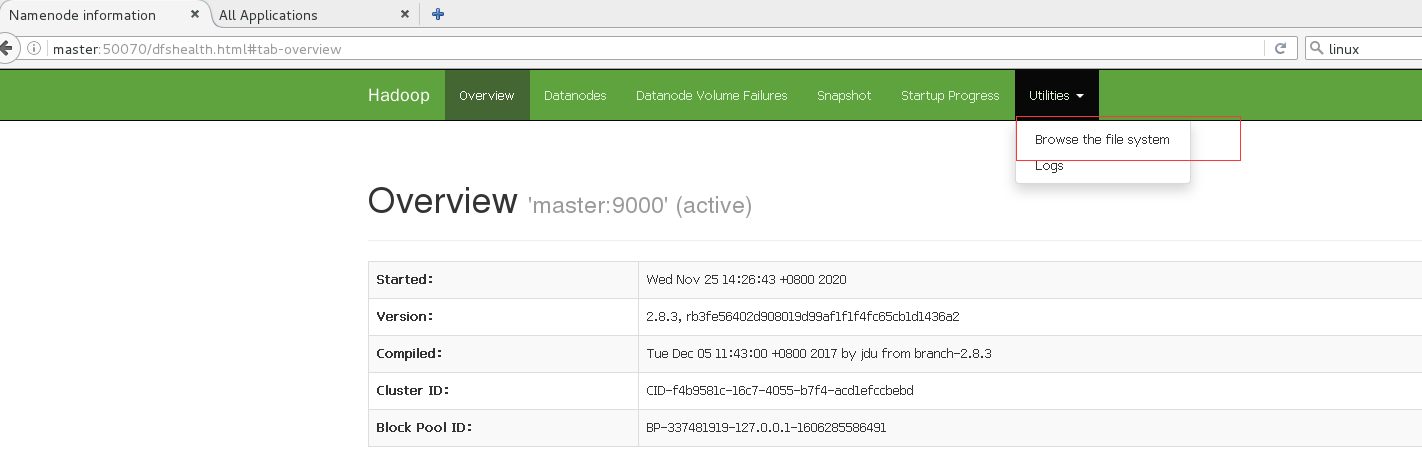
- 启动成功后可以在web上面查看是否成功
http://hadoop101:50070/dfshealth.html#tab-overview
注意:如果不能查看,看如下帖子处理:http://www.cnblogs.com/zlslch/p/6604189.html
操作集群(HDFS)
- 在HDFS文件系统上创建一个input文件夹
bin/hdfs dfs -mkdir -p /user/atguigu/input
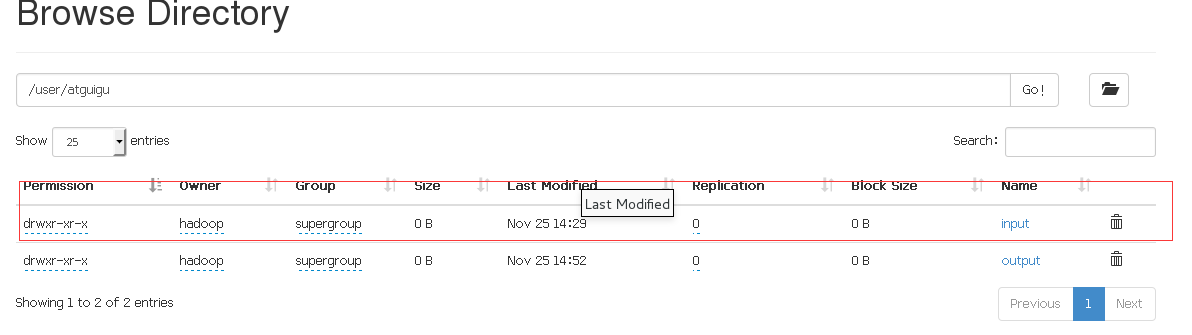
- 将测试文件内容上传到文件系统上,这里我们上传我们前面创建的文件夹wc.input
bin/hdfs dfs -mkdir -p /user/atguigu/input

- 运行MapReduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /user/atguigu/input/ /user/atguigu/output
运行成功后会出现两个文件在output目录下,表示执行成功。

- 删除输出结果,因为后面我们要输出文件到output中,如果存在这个文件夹可能会冲突,所以先删除掉。
hdfs dfs -rm -r /user/atguigu/output
启动YARN并运行MapReduce程序
- 步骤
- 配置集群在YARN上运行MR
- 启动、测试集群增、删、查
- 在YARN上执行WordCount案例
- 配置集群,配置yarn-env.sh,在文件末尾添加语句
export JAVA_HOME=/opt/module/jdk1.8.0_144(这里的jdk改为你的版本)
- 配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
- 配置:mapred-env.sh,同样添加java_home
export JAVA_HOME=/opt/module/jdk1.8.0_144
- 配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
添加
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 启动集群
- 启动前必须保证NameNode和DataNode已经启动,使用jps查看是否启动
- 启动ResourceManager这个前面已经启动了,不用管这个
- 启动NodeManager
sbin/yarn-daemon.sh start nodemanager
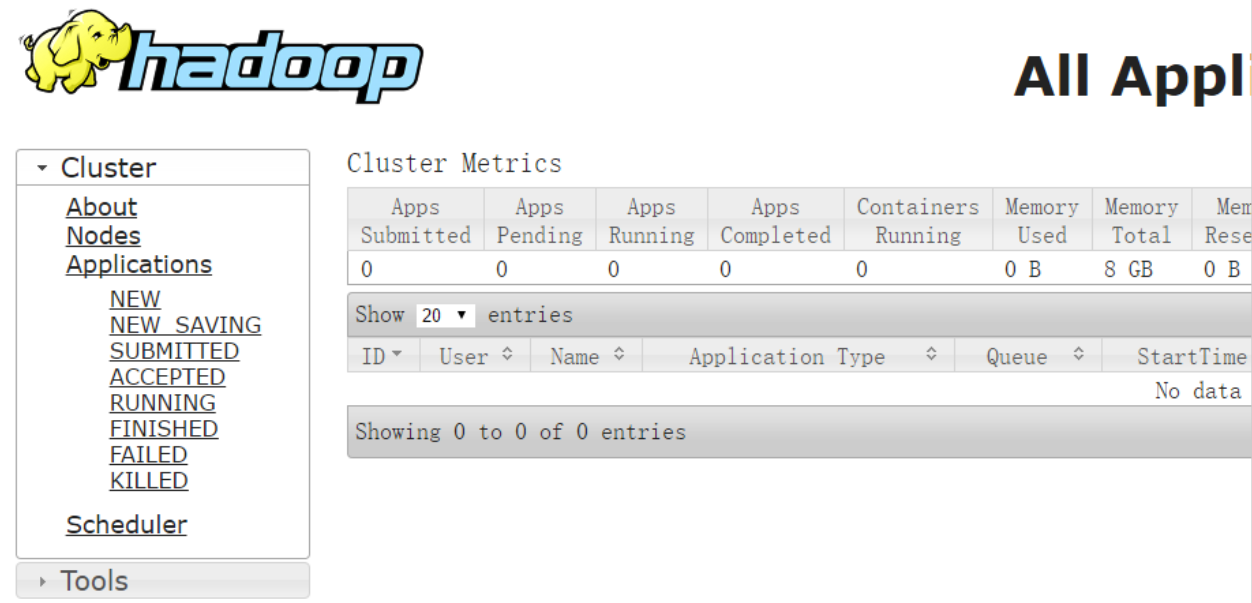
- YARN的浏览器页面查看http://master:8088/cluster
- 执行MapReduce程序,前面删除output目录就是为了防止与这个冲突,不过可以修改输出的文件夹名称比如为output1.
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /user/atguigu/input /user/atguigu/output
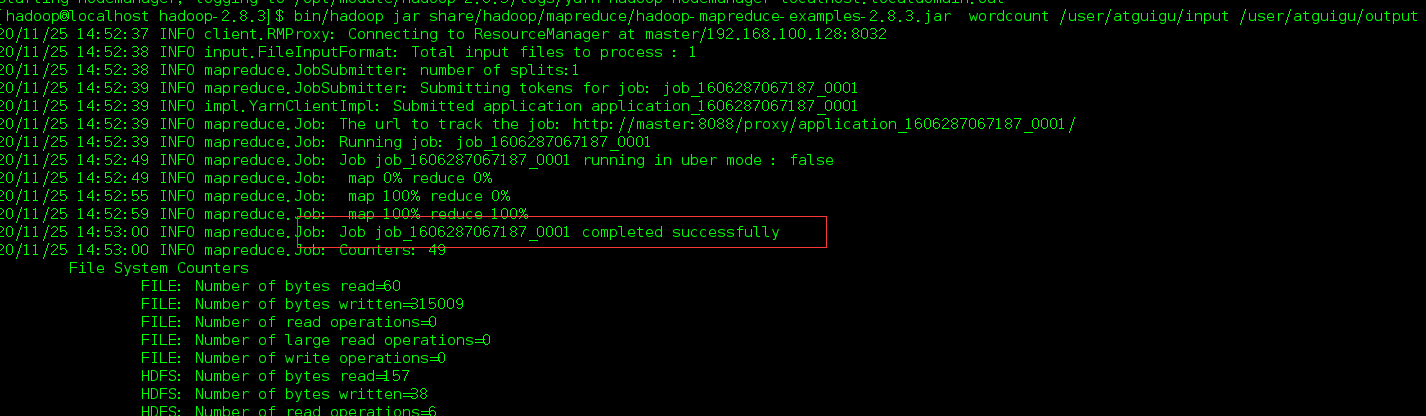
出现这个表示成功,在web端查看。
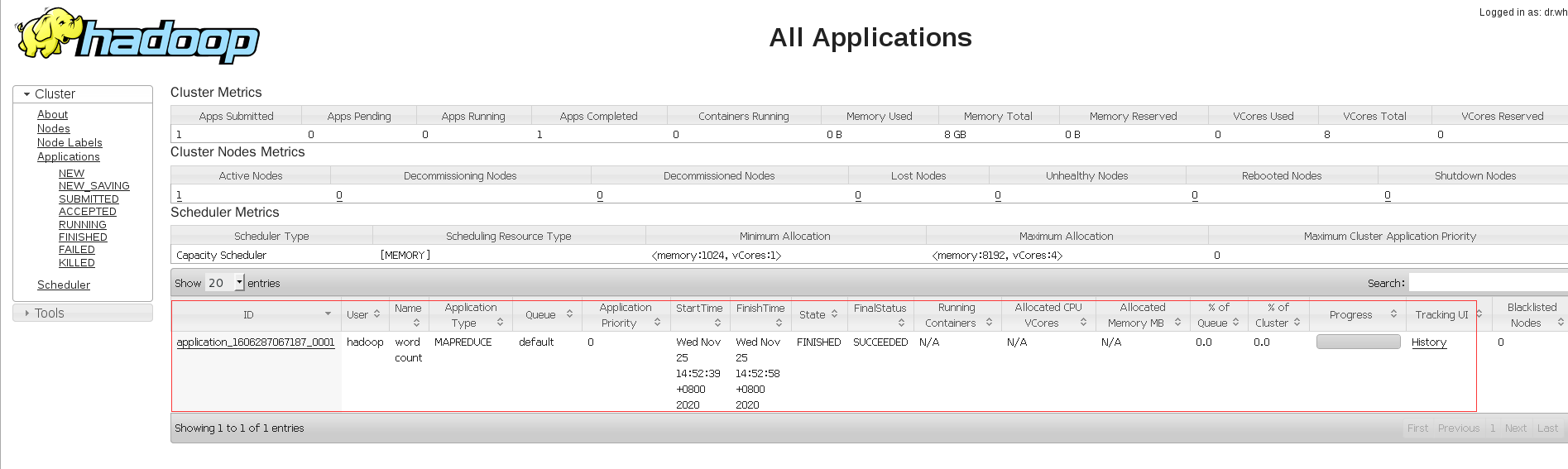
成功。
问题
- 这里主要讲解几个大件hadoop是遇到的错误,首先最大的问题也即是让我反反复复搭建几次的问题,就是执行最后一步卡住不动。
这个我是参考这个解决的:https://blog.csdn.net/wjw498279281/article/details/80317424
- 还有就是在最后执行HDFS上传文件时,上传失败,这个问题主要是因为防火墙没关,其实也不是没关,因为我在root下关的,最后切换到hadoop下没有关,结果上传不上去。
这个的解决办法:https://blog.csdn.net/qq_44702847/article/details/105403388
3。还有一些其他的错误倒还好,就是第一个问题让我一直卡顿在最后一步。
结语
这个是我第一次搭建hadoop,记录一下吧。搭建后也算是对hadoop的搭建有点了解了吧。