Data Source
StreamExecutionEnvironment.addSource(sourceFunction)
共有以下几类:
-
基于集合
- fromCollection(Collection) - 从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型 必须相同。
- fromCollection(Iterator, Class) - 从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的 类型。
- fromElements(T …) - 从给定的对象序列中创建数据流。所有对象类型必须相同。
- fromParallelCollection(SplittableIterator, Class) - 从一个迭代器中创建并行数据流。Class 指定 了该迭代器返回元素的类型。
- generateSequence(from, to) - 创建一个生成指定区间范围内的数字序列的并行数据流。
-
基于文件
- readTextFile(path) - 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返 回。
- readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(一次)。
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是上面两个方法内 部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据 (FileProcessingMode.PROCESSCONTINUOUSLY FileProcessingMode.PROCESSONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
-
基于 Socket
- socketTextStream(String hostname, int port) - 从 socket 读取。元素可以用分隔符切分。
-
自定义
addSource - 添加一个新的 source function。例如,你可以用 addSource(new FlinkKafkaConsumer011<>(…)) 从 Apache Kafka 读取数据。
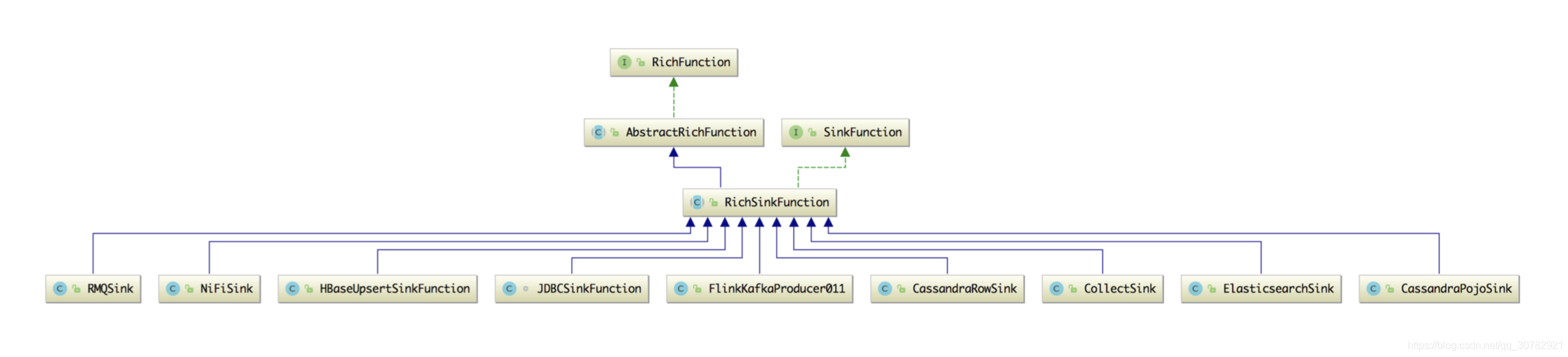
Data Sink