Day 27 分页异常处理接口文档
一、分页Pagination
REST frameword 提供了分页的支持
写在前面
视图继承的不一样,分页器写起来也不一样,比如APIView和GenericAPIView
GenericAPIView+ListModelMixin中包含了 与分页相关的方法这种最简单,只需要配置一下就可以了,但是APIView中没有。则需要自己写
1、全局配置
我们可以在配置文件中设置全局的分页方式
# views.py
class BookView(GenericViewSet, ListModelMixin):
queryset = models.Book.objects.all() # 源码中是默认添加一个all方法的,但是在使用分页器的时候不加就会报错
serializer_class = serializer.BookSerializer
# settings.py
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 2, # 每页数目 就这个有用
'PAGE_QUERY_PARAM': 'p' # 请求的参数没用,还是按照page来参考
}
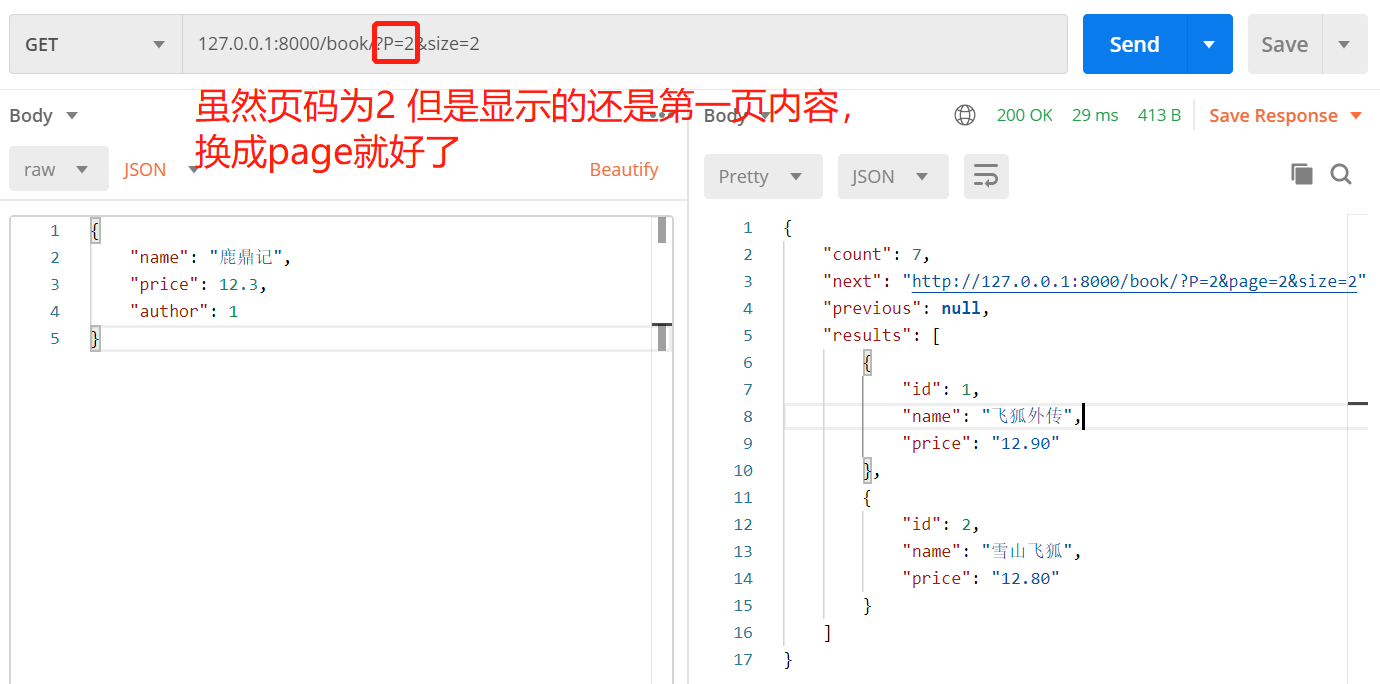
注意:如果在视图内关闭分页功能,只需在视图内设置
pagination_class = None
2、内置分页器+重写
# urls.py 配置
router = SimpleRouter()
router.register('book', views.BookView)
urlpatterns = [
path('admin/', admin.site.urls),
path('signup/', views.Sign_Up.as_view()),
]
urlpatterns += router.urls
2.1PageNumberPagination 普通分页 (用的最多)
class BookView(GenericViewSet, ListModelMixin):
queryset = models.Book.objects.all()
serializer_class = serializer.BookSerializer
pagination_class = PageNumberPagination # 这里分页器类是唯一的 也就是每个视图类只能有一种分页方式
但是使用这个会有个问题也就是 他的page_size,page_size_query_param,max_page_size默认都是none 也就是说 他会默认把所有内容打印出来
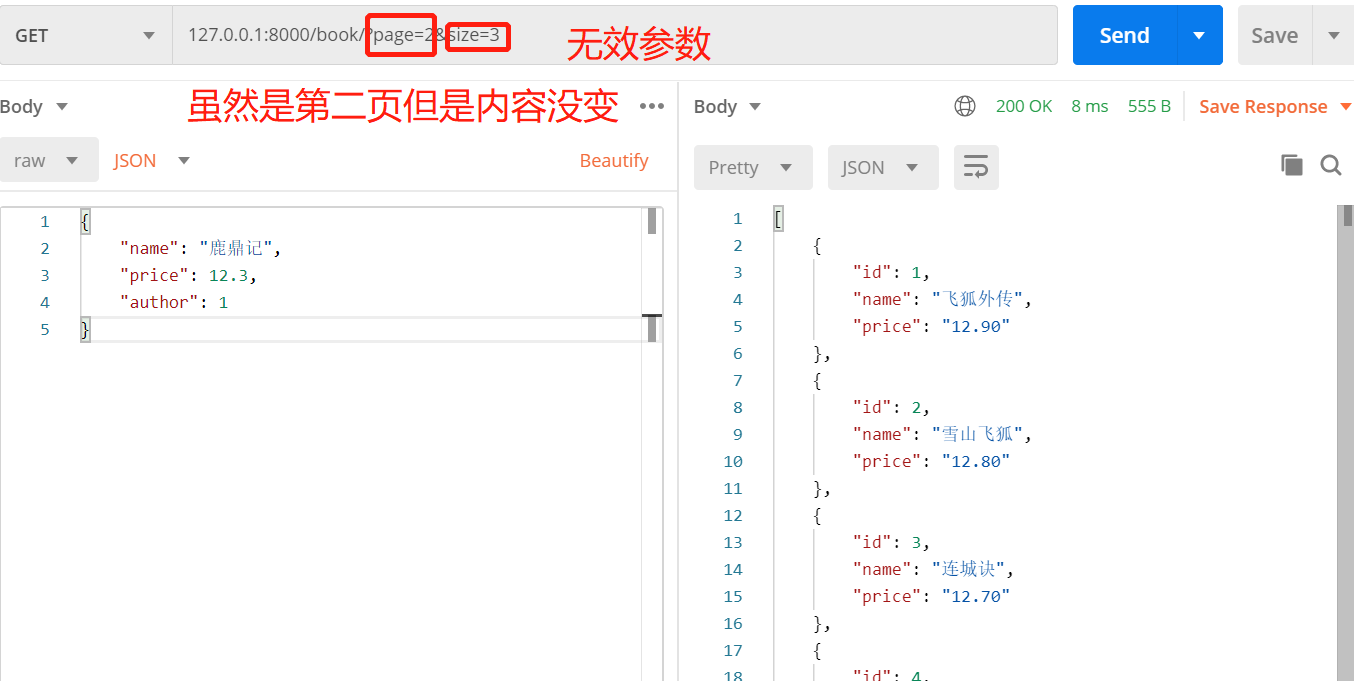
如果不想这样,我们就可以 重写一个类 继承PageNumberPagination
class MyPageNumberPagination(PageNumberPagination):
page_size = 3 # 每页显示多少条
page_query_param = 'P' # 页面查询参数
page_size_query_param = 'size' # 页面显示条数查询参数
max_page_size = 5 # 页面最大显示条数
class BookView(GenericViewSet, ListModelMixin):
queryset = models.Book.objects.all()
serializer_class = serializer.BookSerializer
pagination_class = MyPageNumberPagination
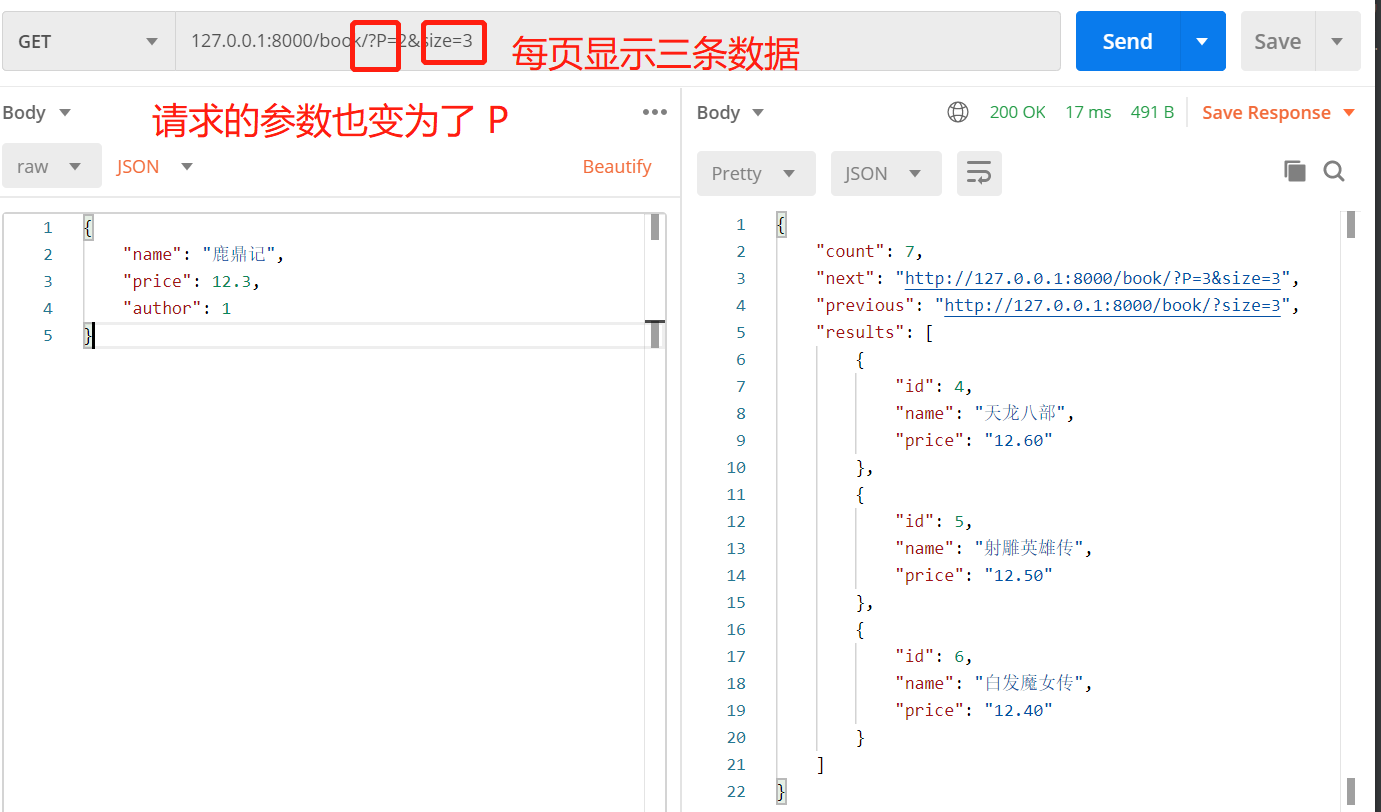
使用方法127.0.0.1:8000/book/?page=2&size=3
这样那些参数就有用了,max_page_size = 5 # 页面最大显示条数 如果按照下面的请求 那么他就会显示第六条,第七条数据,因为第一页显示了五条
2.2LimitOffsetPagination:偏移分页
# views.py
class MyLimitOffsetPagination(LimitOffsetPagination):
default_limit = api_settings.PAGE_SIZE # 默认返回查询的条数 这里我再setting中配置的是5
limit_query_param = 'limit' # 查询时,指定查询参数
offset_query_param = 'offset' # 查询时,指定的起始位置是哪
max_limit = 4 # 查询时,最多返回多少条数据
class BookView(GenericViewSet, ListModelMixin):
queryset = models.Book.objects.all()
serializer_class = serializer.BookSerializer
pagination_class = MyLimitOffsetPagination
# settings.py
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 5, # 每页数目
}
注意;同样也可以直接使用pagination_class = LimitOffsetPagination
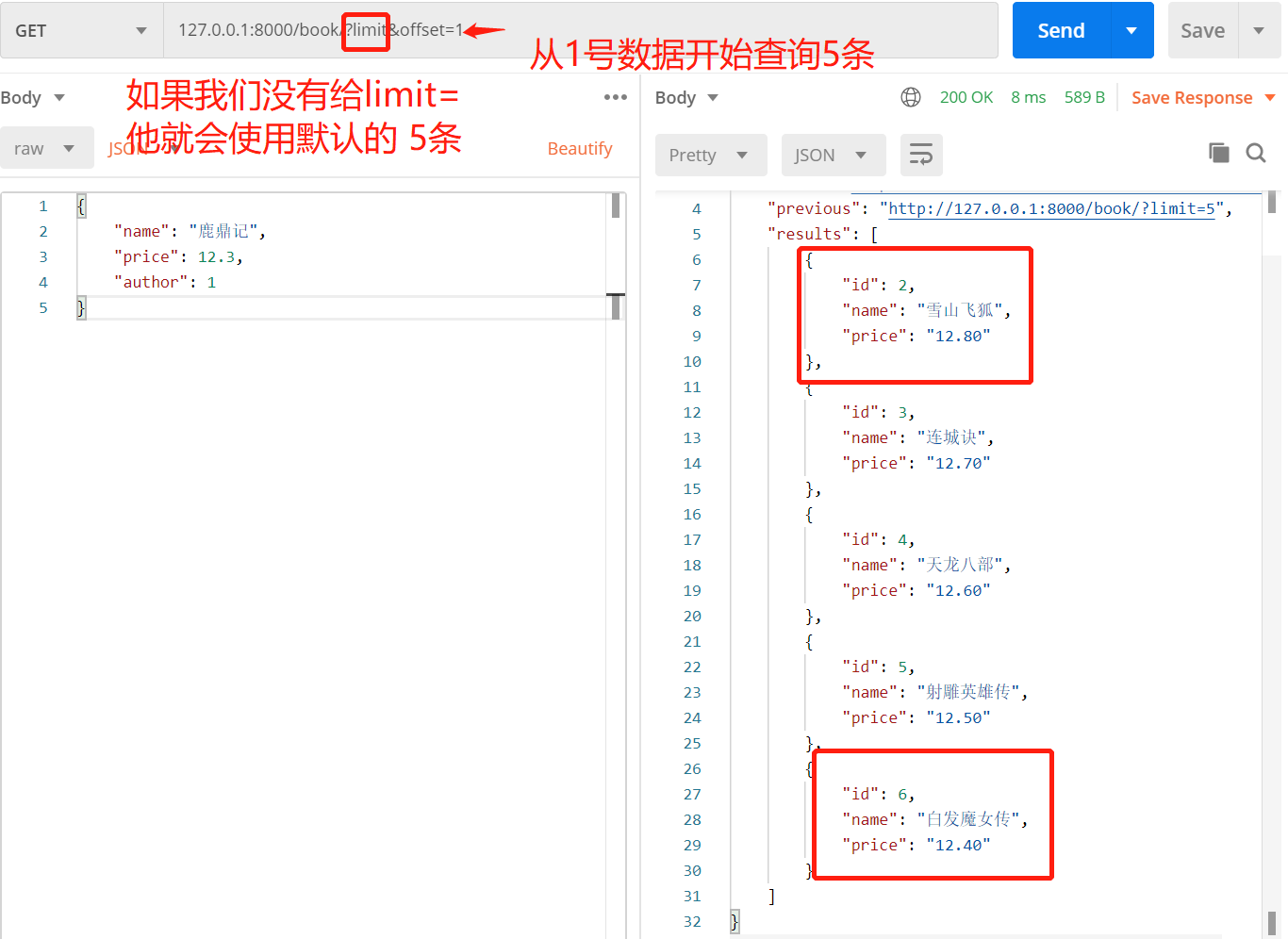
使用方法127.0.0.1:8000/book/?limit=3&offset=1
这里我们来查询下
2.3 CursorPagination:游标分页(速度块)
这个不能默认使用,需要继承!
前端访问网址形式:
GET http://127.0.0.1/four/students/?cursor=cD0xNQ%3D%3D
可以在子类中定义的属性:
- cursor_query_param:默认查询字段,不需要修改
- page_size:每页数目
- ordering:按什么排序,需要指定
# views.py
class MyCursorPagination(CursorPagination):
cursor_query_param = 'cursor' # 查询的时候,指定的查询方式
page_size = api_settings.PAGE_SIZE # 每页显示多少条 五条
ordering = 'id' # 排序方式 这个一定要写
page_size_query_param = 'size' # 查询的时候指定每页显示多少条
max_page_size = None # 每页最多显示多少条
class BookView(GenericViewSet, ListModelMixin):
queryset = models.Book.objects.all()
serializer_class = serializer.BookSerializer
pagination_class = MyCursorPagination
# settings.py
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 5, # 每页数目
}
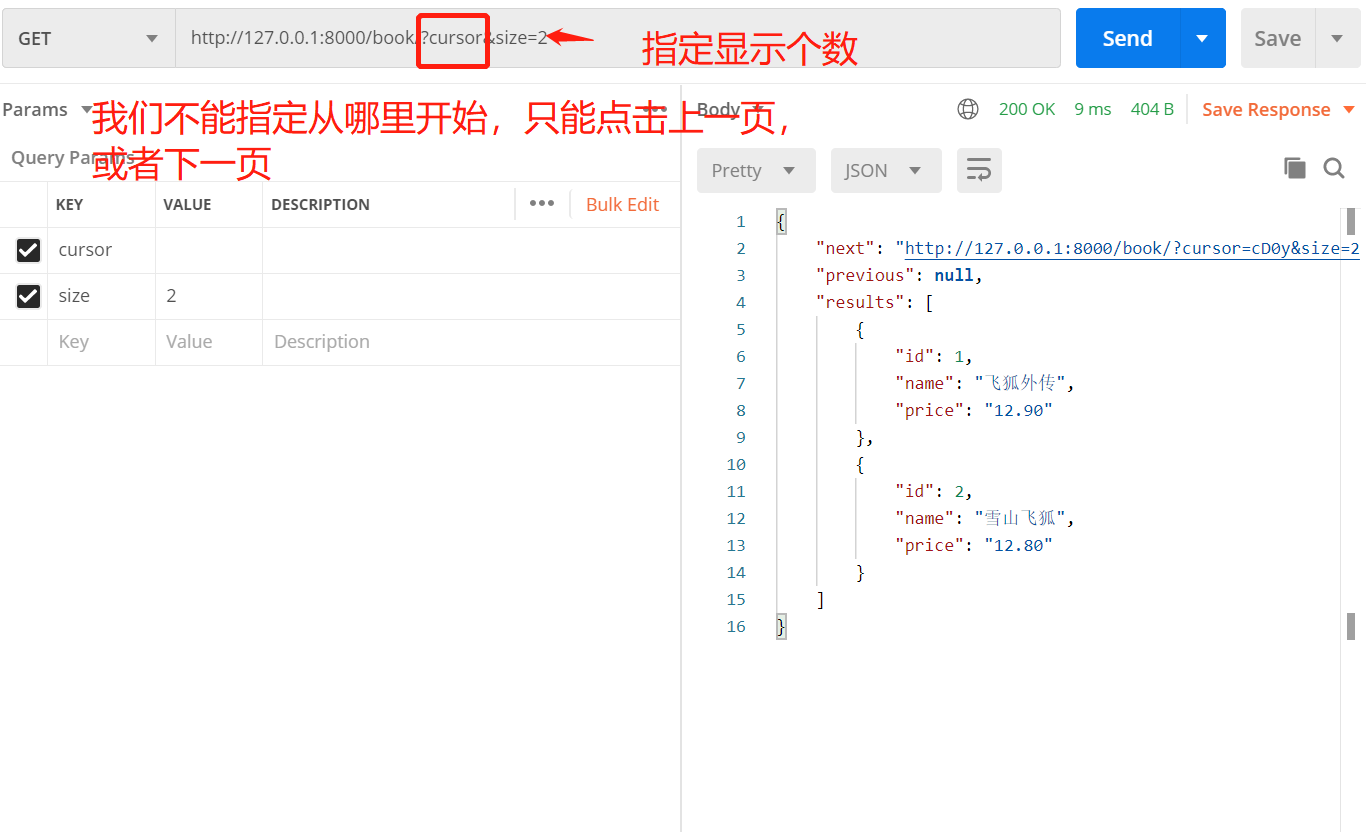
注:三种分页器都是有上一页,下一页返回的
三种分页器的,都有各自的适用场景,第三种虽然有限制,但是它能很快的返回数据,前面两种虽然可以制定位置,但是他是一次性查到多条数据,给内存压力,而第三种就不会。
3、APIView分页器写法
7 APIView的分页模式
-新建一个类,继承普通分页,重写四个属性
-视图类写法如下
class StudentApiView(APIView):
def get(self,request):
student_list=Student.objects.all()
page=MyPageNumberPagination()# 实例化得到对象
# 只需要换不同的分页类即可
res=page.paginate_queryset(student_list,request,self)# 开始分页
ser=StudentSerializer(res,many=True)
return page.get_paginated_response(ser.data) # 返回数据
二、全局异常
REST framework提供了异常处理,我们可以自定义异常处理函数。
源码中我的视图函数出现异常会被 try中 被捕获到,然后执行 一个整体的处理异常
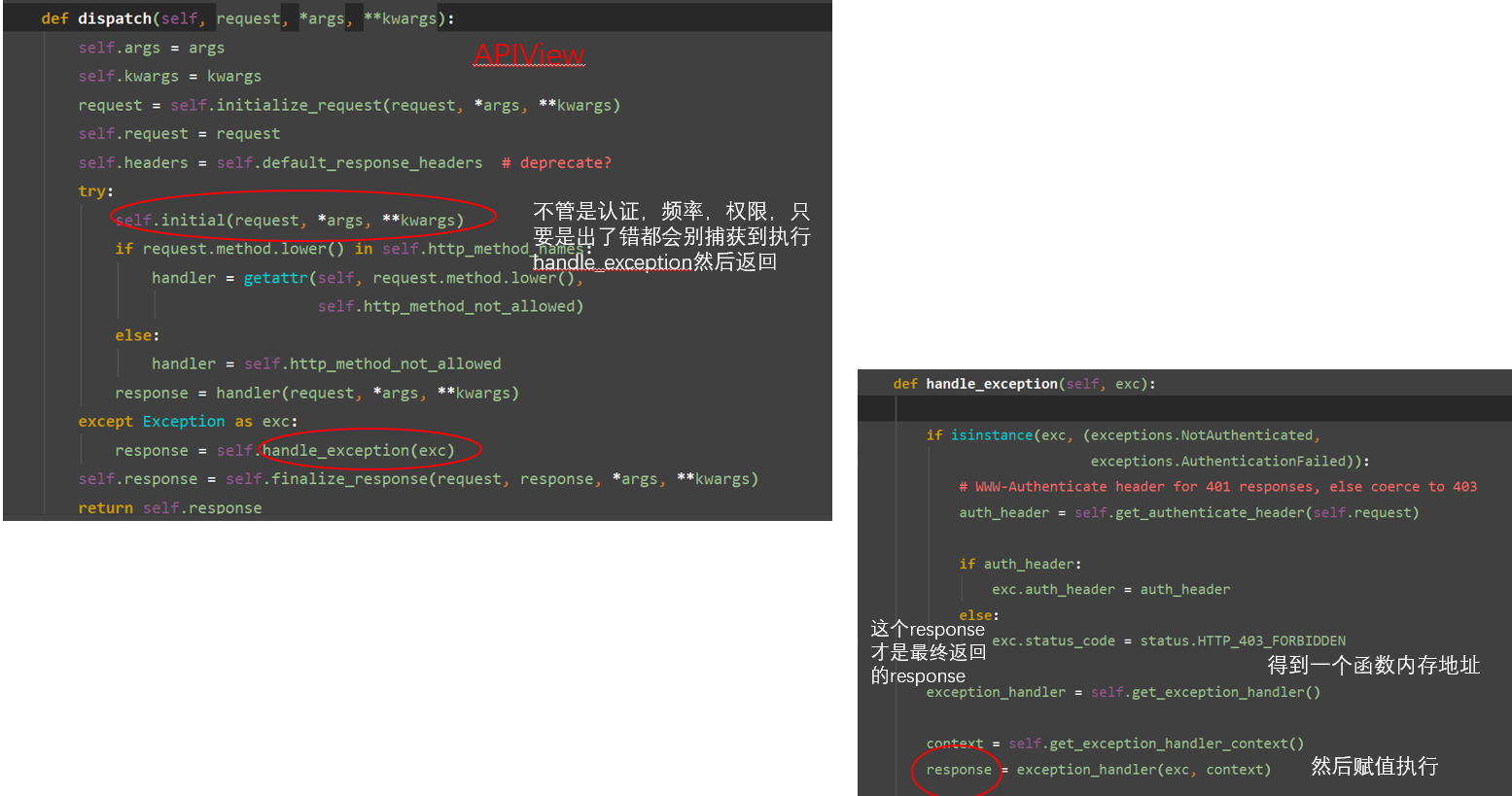
这里我们就创建一个函数,传入两个参数,然后导入exception_handler让他执行,得到一个结果就是response,如果response为空则代表代码出了问题(异常)。这样写不会执行,所以我们要去配置下,以后就固定使用
4.1 使用方式
from rest_framework.views import exception_handler
def common_exception_handler(exc, context):
response = exception_handler(exc, context)
if response is None:
# 无论是发生了什么错误,都返回 未知错误,当然也可以进一步判断
response = Response({
'code':999,'detail': '未知错误'}, status=status.HTTP_500_INTERNAL_SERVER_ERROR)
return response
在配置文件中声明自定义的异常处理
在setting中配置
REST_FRAMEWORK = {
'EXCEPTION_HANDLER':'app01.utils.common_exception_handler'
}
如果未声明,会采用默认的方式,如下
rest_frame/settings.py
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler'
}
4.2 案例
from rest_framework.views import exception_handler
from rest_framework.response import Response
from rest_framework.views import exception_handler as drf_exception_handler
from rest_framework import status
from django.db import DatabaseError
def common_exception_handler(exc, context):
response = drf_exception_handler(exc, context)
if response is None:
view = context['view']
print('[%s]: %s' % (view, exc))
if isinstance(exc, DatabaseError):
response = Response({
'detail': '服务器内部错误'}, status=status.HTTP_507_INSUFFICIENT_STORAGE)
else:
response = Response({
'detail': '未知错误'}, status=status.HTTP_500_INTERNAL_SERVER_ERROR)
return response
三、自定义response
之前封装过一个response对象,但是那个没有继承DRF的Response ,只是一个字典的使用.
这里我们重写一个Response类, 继承父类的__init__然后进行重写,然后我们给他传入,需要的参数
class APIResponse(Response):
def __init__(self, code=100, msg='成功', data=None, status=None, headers=None, content_type=None,
**kwargs): # 用我自己的response,可以不传默认用弗雷德,如果我们要使用就要做出改变
dic = {
'code': code, 'msg': msg} # 这是返回信息格式
if data: # 如果有信息
dic['data'] = data # 添加进去
dic.update(kwargs) # 这里使用往里面添加kwargs对应的字典
super().__init__(data=dic, status=status,
template_name=None, headers=headers,
exception=False, content_type=content_type)
使用
# serializer.py
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = '__all__'
# views.py
class TextAPI(GenericAPIView):
queryset = models.Book.objects
serializer_class = serializer.BookSerializer
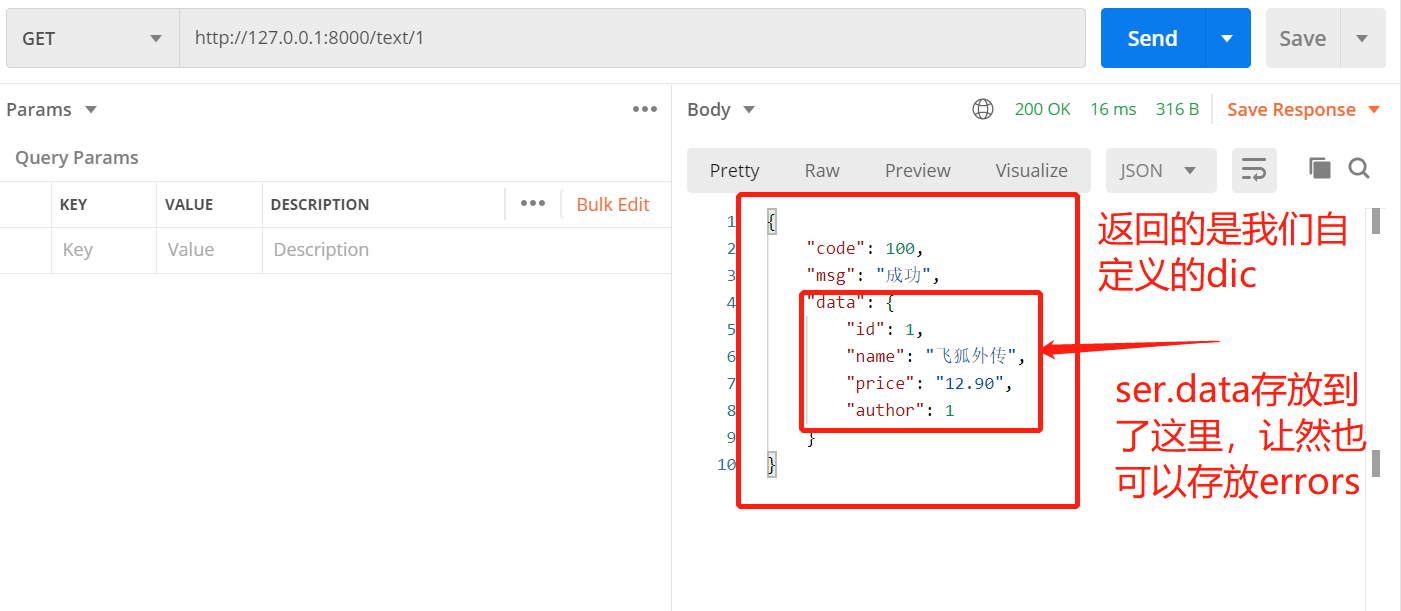
def get(self, request, *args, **kwargs):
book = self.get_object()
ser = self.get_serializer(book)
return utils.APIResponse(data=ser.data)
# urls.py
url(r'^text/(?P<pk>\d+)', views.TextAPI.as_view())
然后我们运行下
四、自动生成接口文档
1 借助于第三方:coreapi,swagger
2 在路由中
from rest_framework.documentation import include_docs_urls
path('docs/', include_docs_urls(title='图书管理系统api'))
3 在配置文件中
REST_FRAMEWORK = {
'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema',
}
4 写视图类(需要加注释)
class BookListCreateView(ListCreateAPIView):
"""
get:
返回所有图书信息.
asdfasfda
post:
新建图书.
"""
queryset = Student.objects.all()
serializer_class = StudentSerializer
5 只需要在浏览器输入,就可以看到自动生成的接口文档()
http://127.0.0.1:8000/docs/
拓展
sentry日志管理