8-1 邻接表的应用场合 (20分)
问答题:使用邻接表存储无向图,为什么要足够稀疏才合算?
答:假设无向图有 n 个点,m 条边,每个点相连 因为邻接表储存无向图的时候,有 n 个顶点就要创建 n 个链表. 每个链表都会存和本顶点相关联的顶点,故每一条边会被存两次。故至少需 m* 2 个节点 而邻接矩阵无论图的稀疏程度,都需要 n*(n+1)/2 的空间存储。
课本P158;
8-2 邻接矩阵的边 (20分)
问答题:使用邻接矩阵存储无向图,如何查看i号顶点和j号顶点之间是否存在边?
无向图的邻接矩阵 A 是一个对称矩阵,每条边会表示两次,因此矩阵中对应位置 A[i][j] 或 A[j][i]是否为 1,若为 1 则判断有边,为 0 则判断无边。
课本P155;
8-3 二叉树先序遍历 (40分)
若采用以下的图示方式存储二叉树,请写出相应的类型定义,并写出基于你的类型定义的二叉树先序遍历算法。
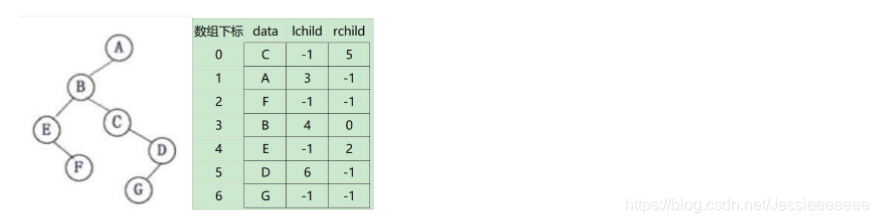
struct BiTNode{
char data;
int lchild,rchild;
}Tree[100];
void preTraverse(int i){
if(i==-1) return ;
printf("%d",Tree[i].data);
preTraverse(Tree[i].lchild);
preTraverse(Tree[i].rchild);
}
int main(){
preTraverse(1);
}
8-4 邻接表的度 (5分)
问答题:使用邻接表存储有向图,如何求指定顶点的度?
假设有向图的邻接表如下: (课本P156-158)
#define MVNum 100 //最大顶点个数
typedef struct ArcNode {
int adjvex; // 该弧所指向的顶点的位置
struct ArcNode *nextarc; // 指向下一条弧的指针
OtherInfo info; // 该弧相关的信息,如权值等,若无信息可缺省
} ArcNode;
typedef struct VNode {
VerTexType data; // 顶点信息
ArcNode *firstarc; // 指向第一条依附该顶点的弧
} VNode, AdjList[MVNum];
typedef struct {
AdjList vertices;
int vexnum, arcnum;
} ALGraph;
求指定顶点的度
方法一:
假如有向图为 ALGraph G,定位查找到指定的顶点 Vi 在一维数组 G.vertices 中位置为 i。
先求指定顶点 G.vertices[i]的出度:
以邻接表中 G.vertices[i]为头结点,遍历其指向的单链表,边依次遍历该链表的各个结点边统计单链表中结点个数则为该顶点的出度。
然后再求指定顶点 G.vertices[i]的入度:
依次遍历 G.vertices[1]~G.vertices[G.vexnum]中 的各条单链表,每条单链表依次遍历其结点同时,判断结点的 adjvex 的值是否等于 i,如果等于,入度的计数器加一,以此统计所有单链表中等于 i 的所有结点个数则为该顶点的入度。
最后该顶点的度为出度+入度
8-5 邻接矩阵的边2 (5分)
问答题:使用邻接矩阵a存储无向网络,若i号顶点与j号顶点之间不存在边,则a[i][j]值为多少,你是怎么分析的?
若 i 号顶点与 j 号顶点之间不存在边,则 a[i][j]和 a[j][i]为∞,∞表示计算机允许的、大于所有边上权值的数 Maxn
8-6 二叉树的中序遍历 (40分)
若采用以下的图示方式存储二叉树,请:
(1)写出相应的类型定义。
(2)写出基于你的类型定义的二叉树中序遍历算法。
(3)写出调用函数的语句。
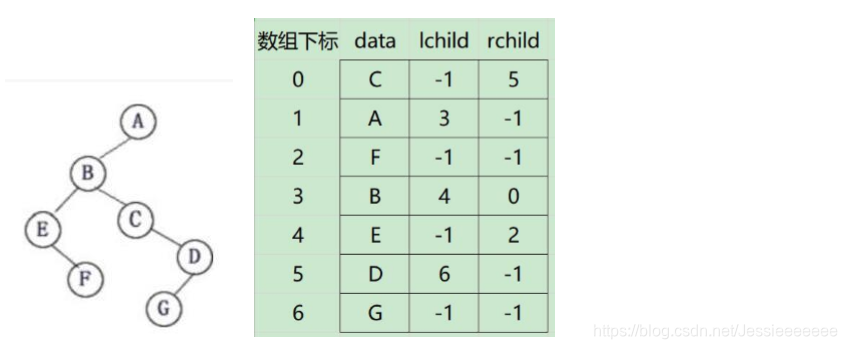
struct BiTNode{
char data;
int lchild,rchild;
}Tree[100];
void inTraverse(int i){
if(i==-1) return ;
inTraverse(Tree[i].lchild);
printf("%d",Tree[i].data);
inTraverse(Tree[i].rchild);
}
int main(){
inTraverse(1);
}
8-7 连通与非连通1 (20分)
1、对于连通图,其连通分量是什么?
1) 在无向图中,如果从顶点 vi 到顶点 vj 有路径,则称 vi 和 vj 连通.如果图中任意两个顶点之间都连通,则称该图为连通图,否则,将其中的极大连通子图称为连通分量。任何连通图的连通分量只有一个,即是其自身。
2、如果从无向图的任一顶点出发进行一次深度优先搜索可访问所有顶点,则该图一定是?
2) 连通图
8-8 连通与非连通2 (20分)
1、对于连通图,其连通分量是什么?
1) 在无向图中,如果从顶点 vi 到顶点 vj 有路径,则称 vi 和 vj 连通.如果图中任意两个顶点之间都连通,则称该图为连通图,否则,将其中的极大连通子图称为连通分量。任何连通图的连通分量只有一个,即是其自身。
2、如果从无向图的任一顶点出发进行一次广度优先搜索可访问所有顶点,则该图一定是?
2) 连通图
8-9 DFS之阅读算法写运行结果1 (30分)
设有以下算法定义:
void DFS_AM(AMGraph G, int v)
{
//图G为邻接矩阵类型
cout << v << " "; //访问第v个顶点
visited[v] = true;
for(w=0; w<G.vexnum; w++) //依次检查邻接矩阵v所在的行
if((G.arcs[v][w]!=0)&& (!visited[w]))
DFS_AM(G, w); //w是v的邻接点,如果w未访问,则递归调用DFS_AM
}
void DFSTraverse(Graph G)
{
// 对图 G 作深度优先遍历
for(v=0; v<G.vexnum; ++v)
visited[v] = FALSE; //访问标志数组初始化
for (v=G.vexnum-1; v>=0; --v)
if (!visited[v]) DFS(G, v); //对尚未访问的顶点调用DFS
}
假设图G中arcs数组内容如下:

写出 DFSTraverse(G) 的运行过程和输出结果。
注意:只写输出结果不写分析过程,0分哈。
v=7
DFS(G,7) ,输出 7,visited[7]=TRUE
DFS(G,1) ,输出 1,visited[1]=TRUE
DFS(G, 2) ,输出 2,visited[2]=TRUE
DFS(G, 4) ,输出 4,visited[4]=TRUE
DFS(G, 5) ,输出 5,visited[5]=TRUE
DFS(G, 3) out ,输出 3,visited[3]=TRUE
回退到 DFS(G, 5)
DFS(G, 6) out ,输出 6,visited[6]=TRUE
回退到 DFS(G, 5) out
回退到 DFS(G, 4) out
回退到 DFS(G, 2) out
回退到 DFS(G, 1) out
回退到 DFS (G, 7) out
v=6 v=5 v=4 v=3 v=2 v=1 v=0
DFS (G, 0) out,输出 0,visited[0]=TRUE
输出序列:7 1 2 4 5 3 6 0
8-10 DFS之阅读算法写运行结果2 (30分)
设有以下算法定义:
void DFS_AM(AMGraph G, int v)
{
// 图 G 为邻接矩阵类型
cout << v << " "; // 访问第 v 个顶点
visited[v] = true;
for(w=G.vexnum-1; w>0; w--) // 依次检查邻接矩阵 v 所在的行
if((G.arcs[v][w]!=0)&& (!visited[w]))
DFS_AM(G, w); //w 是 v 的邻接点,如果 w 未访问,则递归调用 DFS_AM
}
void DFSTraverse(Graph G)
{
// 对图 G 作深度优先遍历
for(v=0; v<G.vexnum; ++v)
visited[v] = FALSE; // 访问标志数组初始化
for (v=0; v<G.vexnum; ++v)
if (!visited[v]) DFS_AM(G, v); // 对尚未访问的顶点调用 DFS
}
假设图 G 中 arcs 数组内容如下:

写出 DFSTraverse(G) 的运行过程和输出结果。(30 分)
注意:只写输出结果不写分析过程,0 分哈。
答:参考上题答案的方法。
8-11 求单源最短路径 (20分)
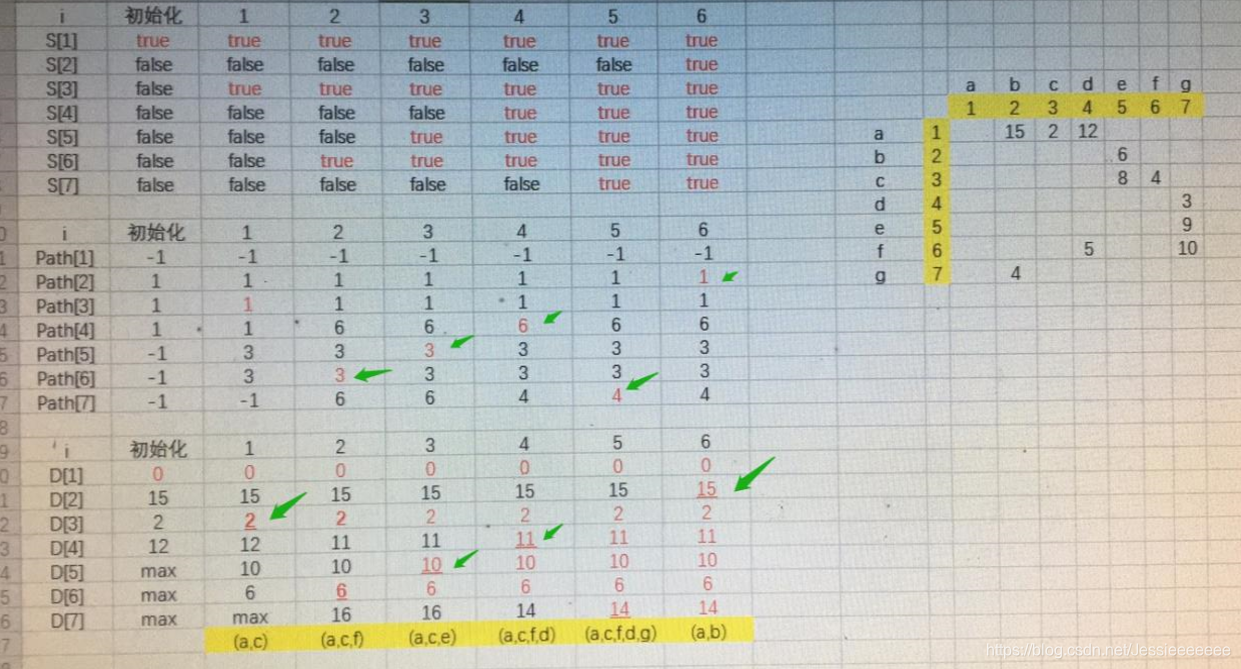
课本P189图6.35,试用Dijkstra算法求出从顶点a到其他各顶点间的最短路径。
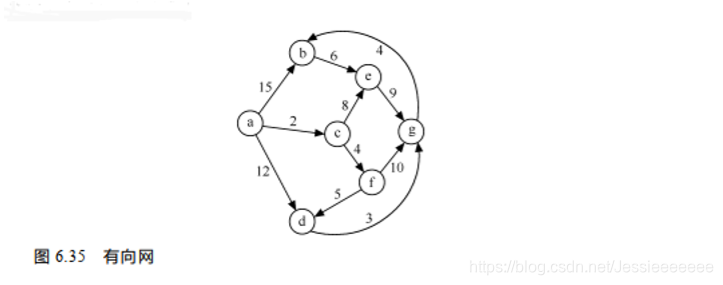
(1)写出S[], D[], Path[]数组在初始化后,以及每次迭代后的内容。
(2)写出顶点a到其他各顶点间的最短路径长度及相应路径
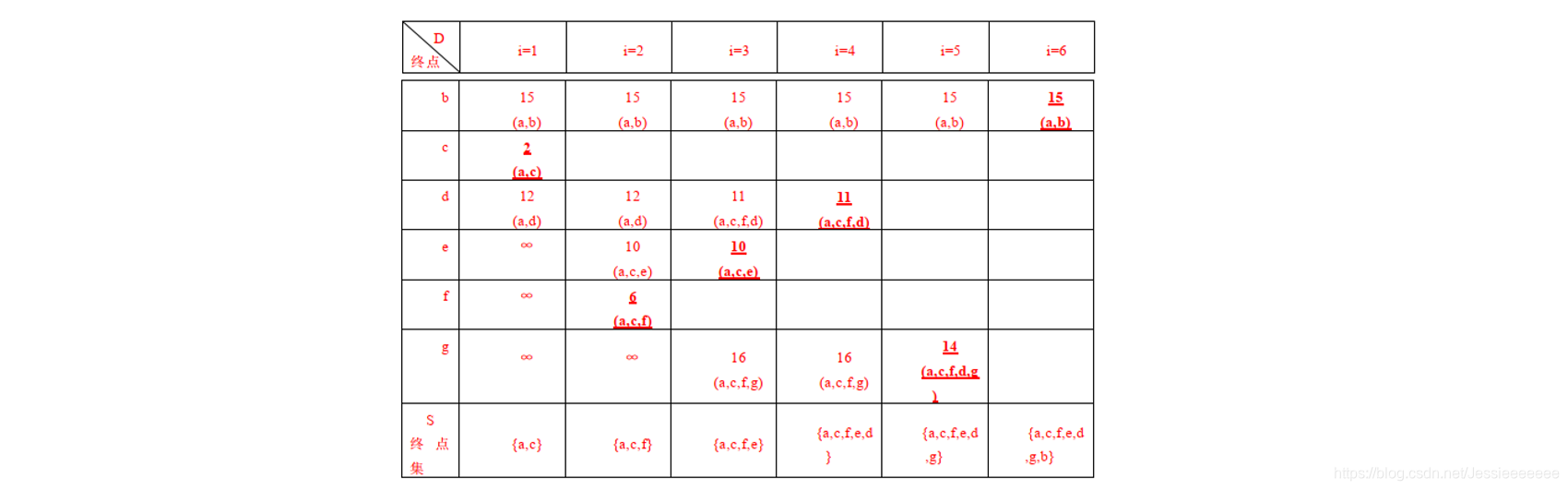
(1) 
或者
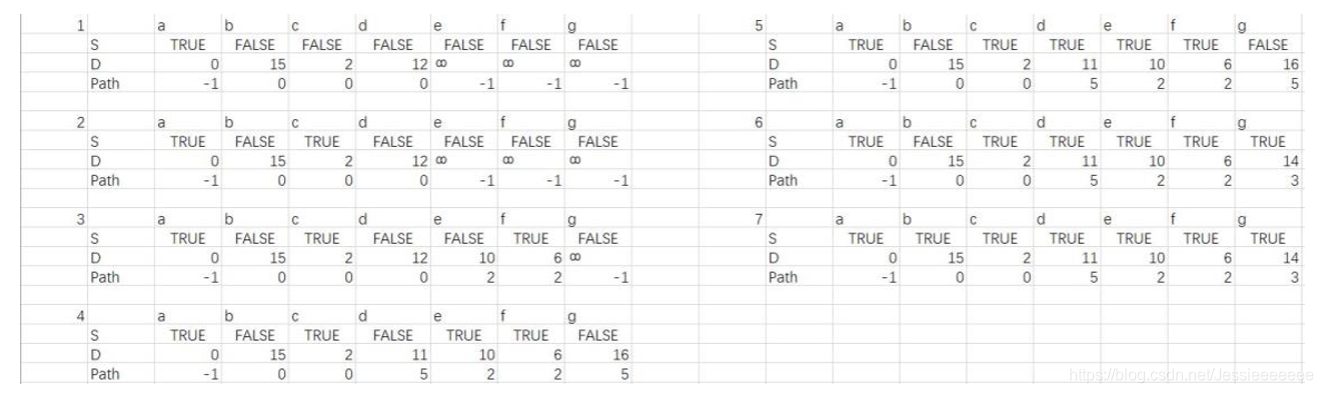
1- 初始化,2-7 做了 6 趟
(2)

8-12 两个顶点间是否有边 (20分)
写出算法,判别以邻接表方式存储的有向图G中是否存在由顶点vi到顶点vj的边(i!=j)。
假设有向图 G 的邻接表如下:
#define MVNum 100 //最大顶点个数
typedef struct ArcNode {
int adjvex; // 该弧所指向的顶点的位置
struct ArcNode *nextarc; // 指向下一条弧的指针
OtherInfo info; // 该弧相关的信息,如权值等,若无信息可缺省
} ArcNode;
typedef struct VNode {
VerTexType data; // 顶点信息
ArcNode *firstarc; // 指向第一条依附该顶点的弧
} VNode, AdjList[MVNum];
typedef struct {
AdjList vertices;
int vexnum, arcnum;
} ALGraph;
答: 假如有向图为 ALGraph G,定位查找到顶点 vi 在一维数组 G.vertices 的位置为 i,顶点 vj 在一维数组 G.vertices 的位置为 j。然后遍历以 G.vertices[i]这个顶点为头结点的单链表,边遍历边判断当前结点的 adjvex 的值是否等于 j,如果等于,则由顶点 vi 到顶点 vj 存在边。 否则,由顶点 vi 到顶点 vj 不存在边。
8-13 哈希表的构造与查找 (25分)
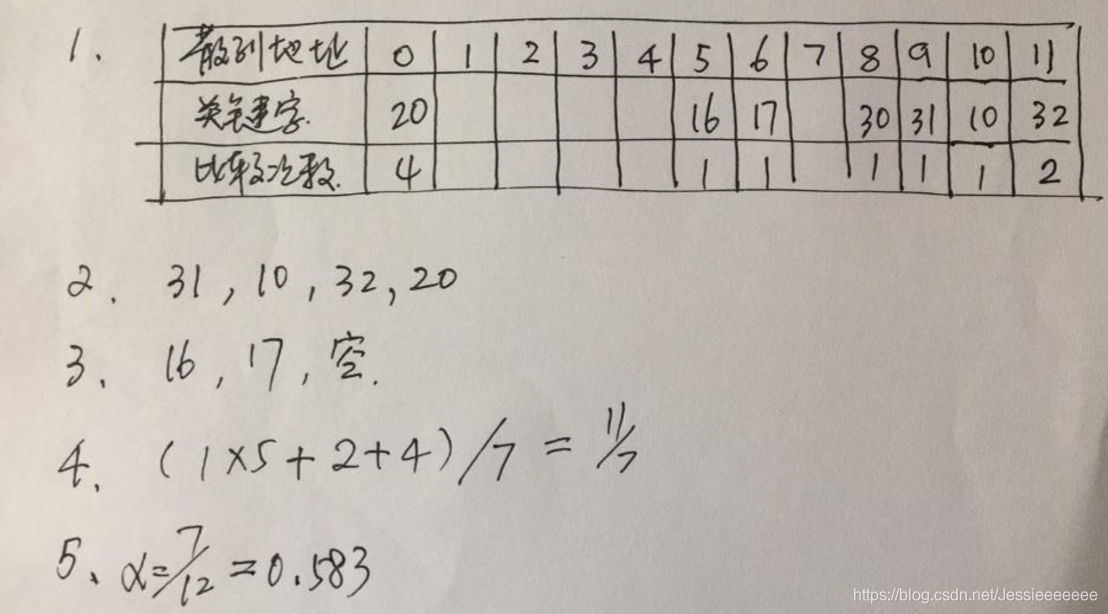
设有一组关键字:(10,16,32,17,31,30,20),哈希函数为:H(key) =key MOD 11,表长为12,线性探测法处理冲突。试回答下列问题:
1、画出哈希表的示意图;
2、若查找关键字20,需要依次与哪些关键字进行比较?
3、若查找关键字27,需要依次与哪些关键字比较?
4、假定每个关键字的查找概率相等,求查找成功时的平均查找长度。
5、求装填因子。
8-14 普里姆-最小生成树 (10分)
对下图,写出以普里姆算法,从顶点,1为起点,构建最小生成树的顶点序列和边的序列。
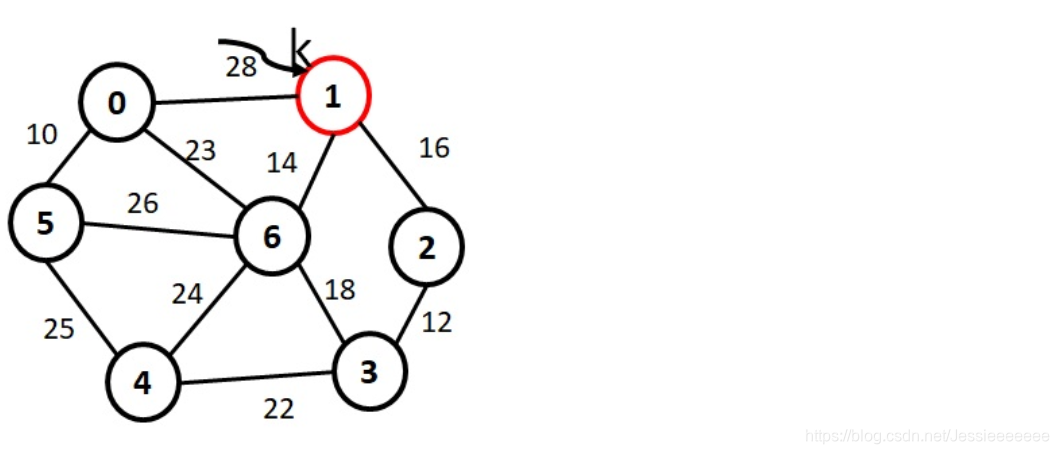
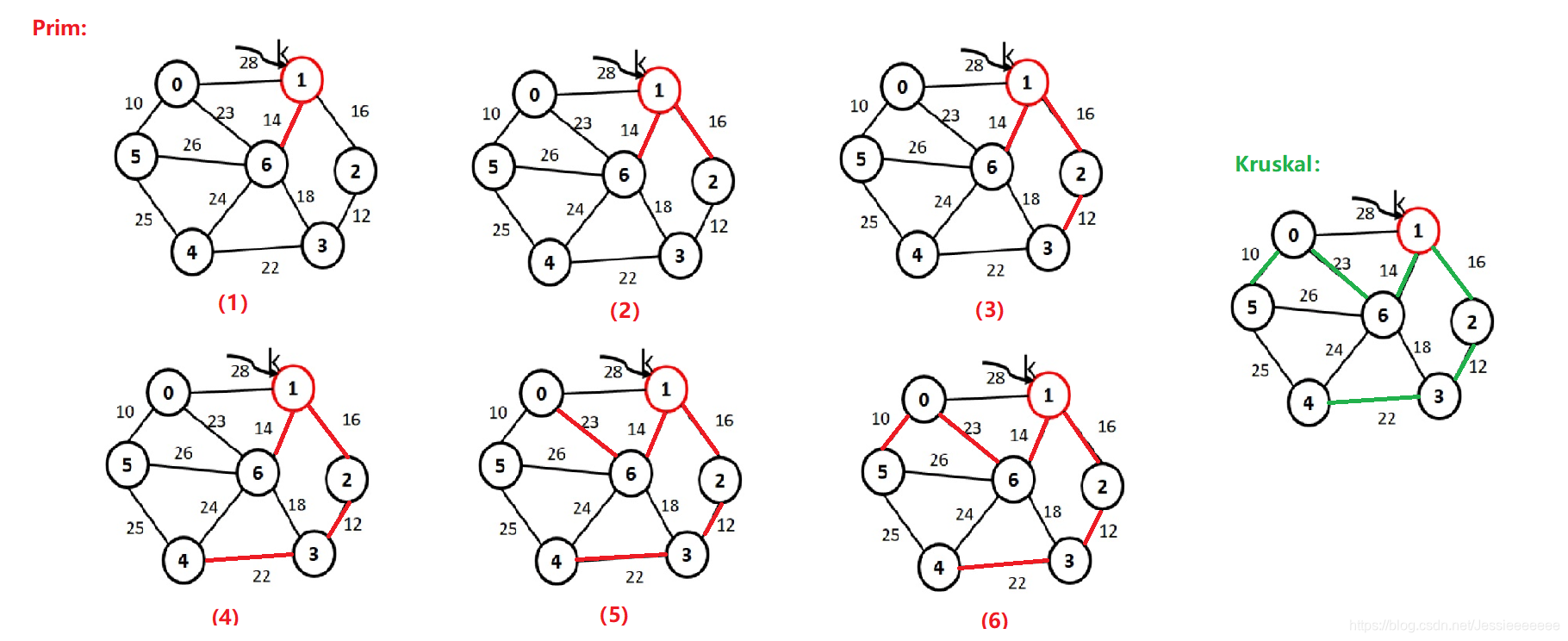
顶点序列:V={1,6,2,3,4,0,5}
边序列:E={(1,6)14, (1,2)16, (2,3)12, (3,4)22, (6,0)23, (0,5),10}
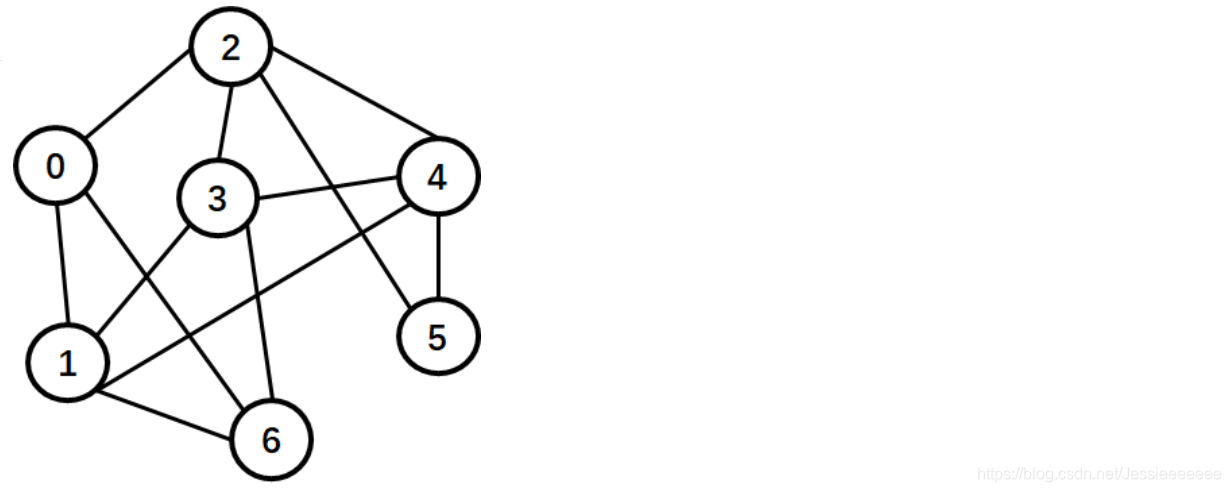
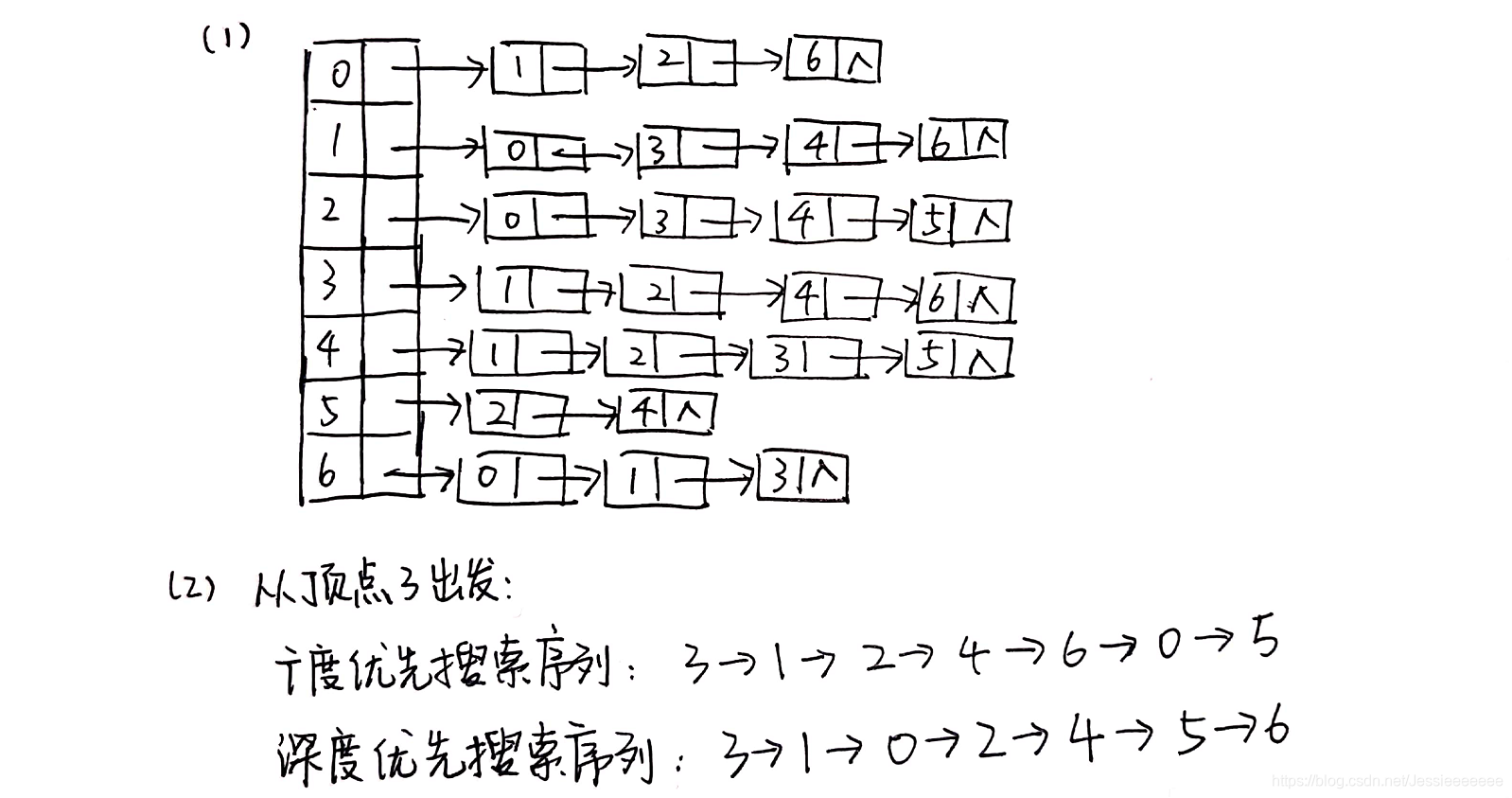
8-15 根据邻接表写出图的广度优先遍历序列 (10分)
(1)写出下图的邻接表(边结点序号从小到大);
(2)写出从顶点3出发的广度优先搜索序列和深度优先搜索序列,顶点之间用空格隔开。约定以结点小编号优先次序访问。 (答题可插入图片)
8-16 二叉排序树的构建 (5分)
在一个空的二叉排序树中依次插入关键字序列为12,7,17,11,16,2,13,9,21,4,请画出所得到的二叉排序树。

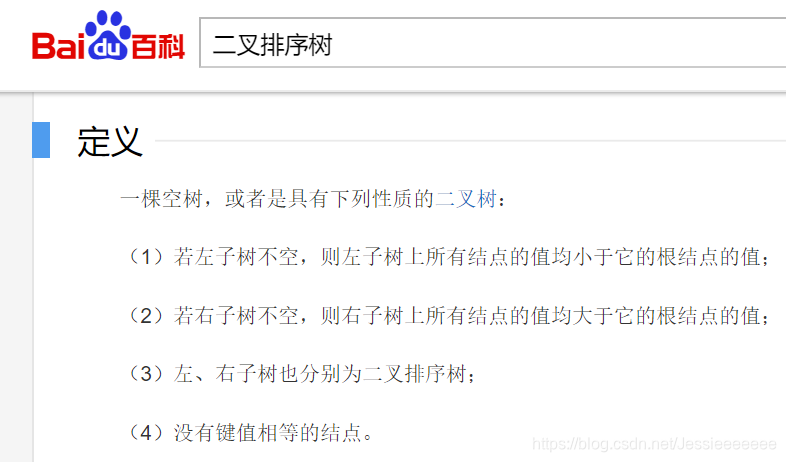
8-17 二分查找 (5分)
已知如下11个元素的有序表(8,16,19,23,39,52,63,77,81,88,90),画出其二分查找的判定树,给出查找元素88和17的折半查找过程。
判定树的概念见课本P194;
8-18 堆排序的初始堆 (6分)
若一组记录的关键码为(46,79,56,38,40,84),请写出利用堆排序的方法建立的初始堆。请写详细过程(3分)和结果(3分).
参考课本P252 例8.6:从最后一个非终端结点开始筛选;
结果:84,79,56,38,40,46;
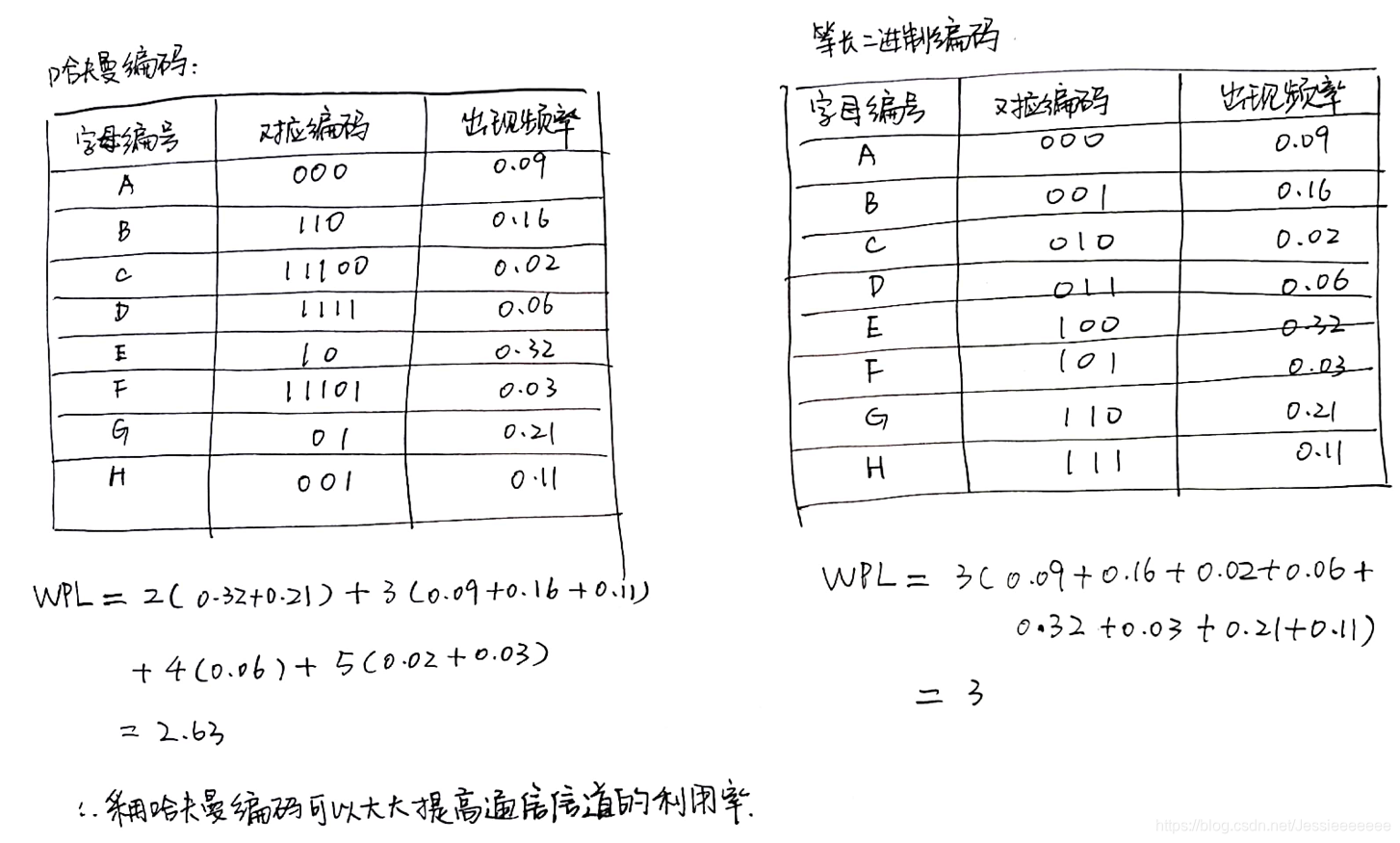
8-19 哈夫曼树的构建 (9分)
假设用于通信的电文仅由8个字母组成,字母在电文中出现的频率分别为0.09,0.16,0.02,0.06,0.32,0.03,0.21,0.11。
(1)试为这8个字母设计哈夫曼编码,请写出哈夫曼树的构建详细过程和编码;(4分)
(2) 设计另一种由二进制表示的等长编码方案;(2分)
(3) 对于上述实例,分析两种方案的编码长度,分析两种方案的优缺点(3分)
答:
(1) ①初始化:首先动态申请 28 = 16 个单元;然后循环 28-1 = 15 次,从1号单元开始,依次将 1 至 15 所有单元中的双亲、左孩子、右孩子的下标都初始化为0;最后再循环 8 次,输入前 8 个单元中叶子结点的权值;
②创建树:循环 8-1 = 7 次,通过 n-1 = 7次的选择、删除与合并来创建哈夫曼树。选择是从当前森林中选择双亲为 0 且权值最小的两个树根结点 s1 和 s2;删除是指将结点 s1 和 s2 的双亲改为非 0;合并就是将 s1 和 s2 的权值和作为一个新结点的权值依次存入到数组的第 n+1 = 9 之后的单元中,同时记录这个新结点左孩子的下标为 s1,右孩子的下标为 s2。
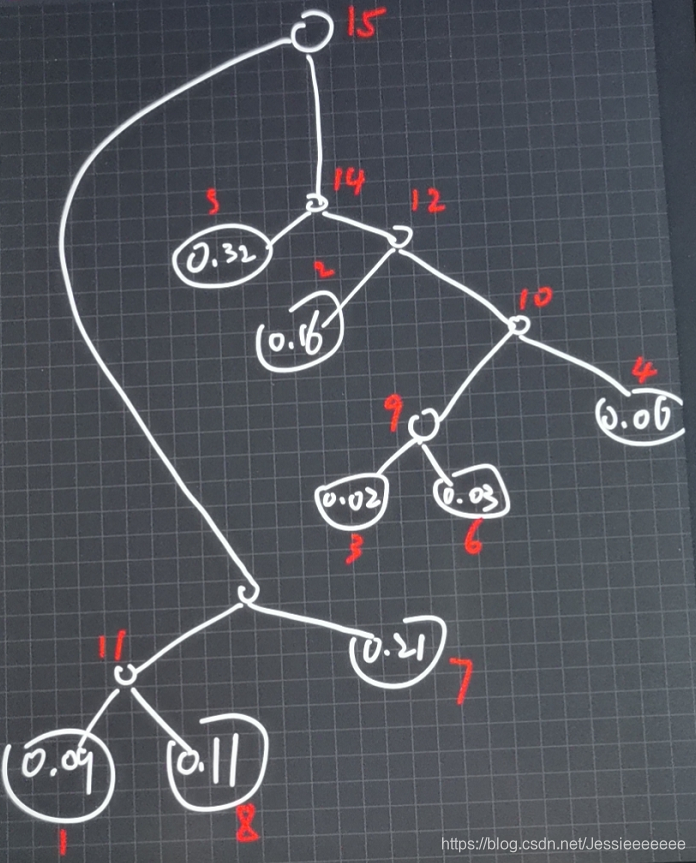
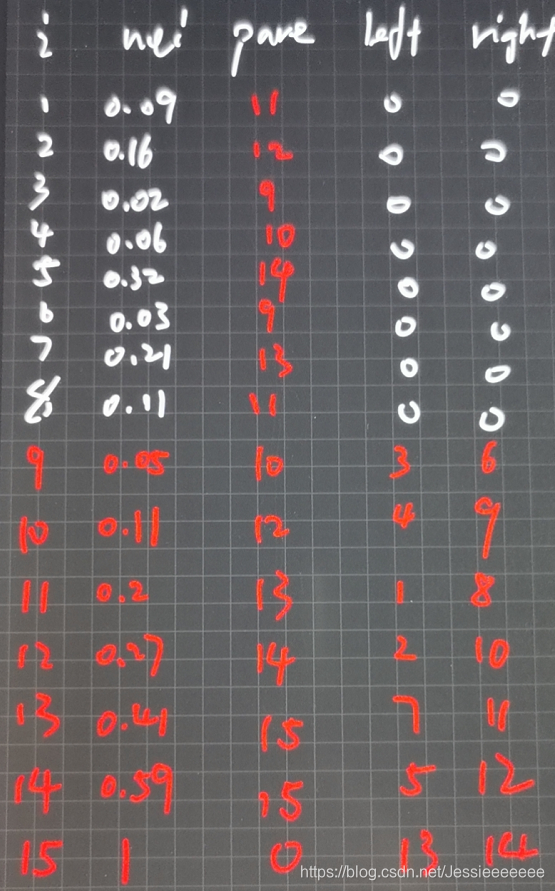
编码:
A:000
B:110
C:11100
D:1111
E:10
F:11101
G:01
H:001
(2) (3)