SQuAD 数据预处理(2)
下面是SQuAD 数据预处理的一个应用实例,使用这个示例来理解proprecess.py这个文件中定义的函数
前言
一个数据处理的步骤
一、数据处理
数据加载与解析
# load dataset json files
train_data = load_json('data/squad_train.json')
valid_data = load_json('data/squad_dev.json')
-------------------------------------------------------
Length of data: 442
Data Keys: dict_keys(['title', 'paragraphs'])
Title: University_of_Notre_Dame
Length of data: 48
Data Keys: dict_keys(['title', 'paragraphs'])
Title: Super_Bowl_50
# parse the json structure to return the data as a list of dictionaries
# 解析数据,生成context、query和label三元组,还包含id和答案
train_list = parse_data(train_data)
valid_list = parse_data(valid_data)
print('Train list len: ',len(train_list))
print('Valid list len: ',len(valid_list))
-------------------------------------------------------
out:
Train list len: 87599
Valid list len: 34726
建立词表
# 转换lists到dataframes
train_df = pd.DataFrame(train_list)
valid_df = pd.DataFrame(valid_list)
train_df.head()
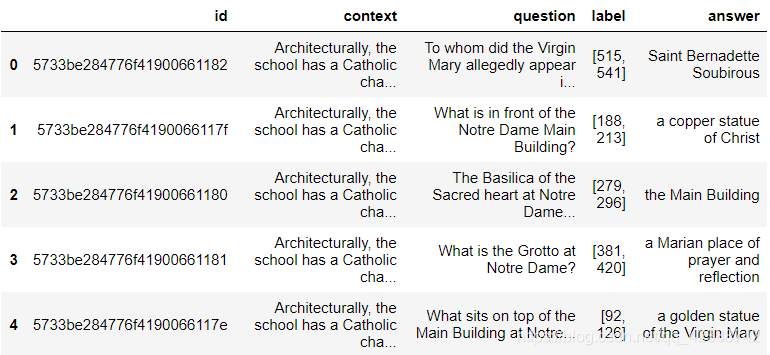
删除离群点,数据过长的点
# get indices of outliers and drop them from the dataframe
# 获得离群值的索引并删除
%time drop_ids_train = filter_large_examples(train_df)
train_df.drop(list(drop_ids_train), inplace=True)
%time drop_ids_valid = filter_large_examples(valid_df)
valid_df.drop(list(drop_ids_valid), inplace=True)
-----------------------------------------------------
out:
Wall time: 1min 25s
Wall time: 34.7 s
# 建立一个词汇表
vocab_text = gather_text_for_vocab([train_df, valid_df])
print("Number of sentences in the dataset: ", len(vocab_text))
-----------------------------------------------------
out:
Number of sentences in the dataset: 118441
建立一个word和character-level的词汇表
%time word2idx, idx2word, word_vocab = build_word_vocab(vocab_text)
print("----------------------------------")
%time char2idx, char_vocab = build_char_vocab(vocab_text)
-----------------------------------------
out:
raw-vocab: 110478
vocab-length: 110480
word2idx-length: 110480
Wall time: 22.5 s
----------------------------------
raw-char-vocab: 1401
char-vocab-intersect: 232
char2idx-length: 234
Wall time: 1.81 s
清除错误
为了删除因为符号弄错的标签
# numericalize context and questions for training and validation set
# 将训练集和验证集的context和questions数字化
%time train_df['context_ids'] = train_df.context.apply(context_to_ids, word2idx=word2idx)
%time valid_df['context_ids'] = valid_df.context.apply(context_to_ids, word2idx=word2idx)
%time train_df['question_ids'] = train_df.question.apply(question_to_ids, word2idx=word2idx)
%time valid_df['question_ids'] = valid_df.question.apply(question_to_ids, word2idx=word2idx)
print(train_df.loc[0])
----------------------------------------------------------------------
out:
Number of error indices: 1000
Number of error indices: 428
# get indices with tokenization errors and drop those indices
# 获取带有tokenization错误的索引,并删除这些索引,由于空格等原因出现的错误字
train_err = get_error_indices(train_df, idx2word)
valid_err = get_error_indices(valid_df, idx2word)
train_df.drop(train_err, inplace=True)
valid_df.drop(valid_err, inplace=True)
# get start and end positions of answers from the context
# this is basically the label for training QA models
# 从context中得到答案的开始和结束位置,这是训练QA模型的基本标签
train_label_idx = train_df.apply(index_answer, axis=1, idx2word=idx2word)
valid_label_idx = valid_df.apply(index_answer, axis=1, idx2word=idx2word)
train_df['label_idx'] = train_label_idx
valid_df['label_idx'] = valid_label_idx
总结
全部处理完后的一个示例
print(train_df.loc[0])
