解读:本质上是官方提供的Cpython解释器的问题,原因是上世纪90年代,当时是单核CPU的大背景下,龟叔为了解决多线程之间恶意竞争资源而出现的诸多问题,特别设计了GIL锁。但是由于科技的进步以及计算机硬件条件的改变,如今在多核CPU的大背景下,这个问题也是越来越突出,但是龟叔在社区反馈:考虑到GIL锁,已经植入到Cpython解释器多年,并与解释器产生千丝万缕的联系,所以强行调整可能会牵一发而动全身,导致Cpython解释器出现各种问题。所以Python的多线程并发问题,始终没有得到有效的解决。
那接下来我们谈谈Python中多线程的效率问题?
这个要从两方面来看待,CPU密集型操作和IO密集型操作:
-
1、CPU密集型代码(各种循环处理、计数等涉及科学计算业务部分),在这种情况下,ticks计数很快就会达到阈值,然后触发GIL的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以Cpython下的多线程对CPU密集型代码并不友好。
-
2、IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。所以Cpython的多线程对IO密集型代码比较友好。
-
3.而在python3.x中,GIL不使用ticks计数,改为使用计时器(执行时间达到阈值后,当前线程释放GIL),这样对CPU密集型程序更加友好,但依然没有解决GIL导致的同一时间只能执行一个线程的问题,所以效率依然不尽如人意。
铺垫结束,接下来今天重点来了,Python针对CPU密集型代码的执行真的无解了么?
长久以来,Python一直被人所诟病的“伪多线程”问题,随着开源的科学计算库Numpy的出现,很大程度上已经得到解决,今天我们就聊聊这个话题。
首先大家先来了解一下Numpy:
Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。
Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
ndarray与Python原生list运算效率对比:
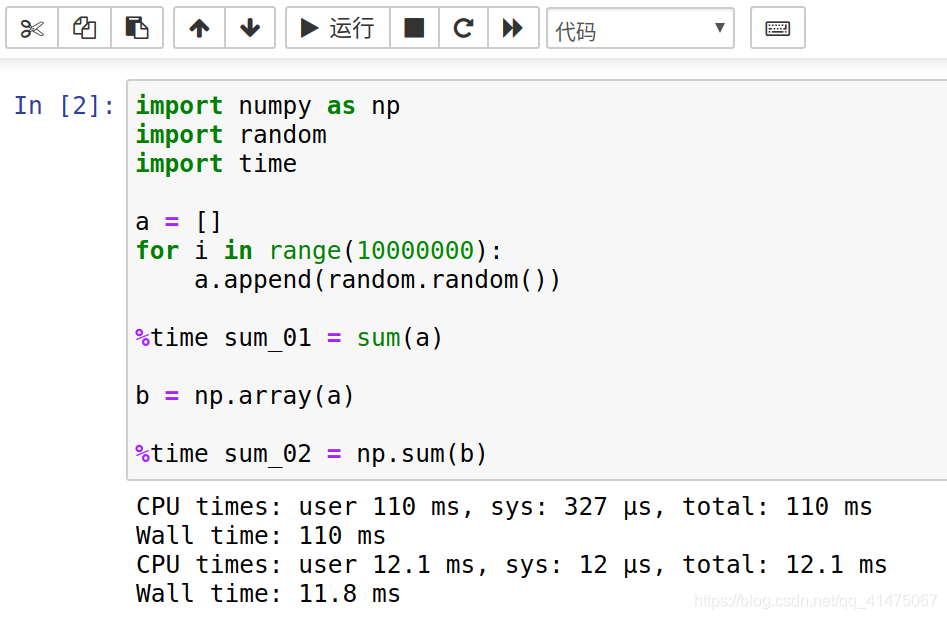
准备了一个简单的测试案例,测了下ndarray与Python原生list运算效率,从实际运行时间上不难看出,ndarray效率相对于Python原生list效率还是要高很多的。当然ndarray的运算效率优势会随着数组变大时优势更明显,也就是说数组越大,Numpy的优势就越明显。
ndarray效率相对于Python原生list效率高的原因是什么?
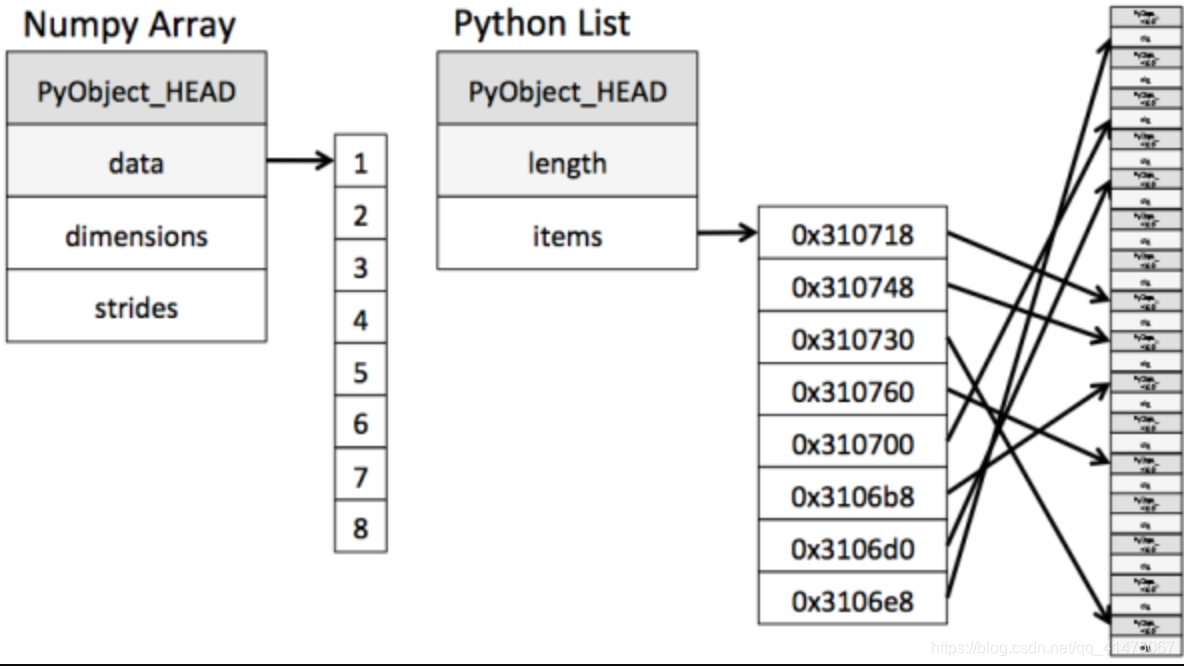
先简单看一下上图:
1.存储优势:
- 众所周知我们Python的原生list是顺序表的一种,而顺序表有根据信息区和数据区是否分离,分为一体式存储结构和分离式存储结构。而存储了大量数据的Python原生list,它存储数据的形式明显属于分离式存储并且元素外置,也就是说他并没有存储对应的数据,而是仅仅存储了元素的地址,所以python原生list就只能通过寻址方式找到下一个元素,这正是导致Python原生list计算效率低的原因之一。
- 图中我们可以看出ndarray在存储数据的时候明显属于一体式存储结构,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
2.在科学计算中,Numpy的ndarray就可以省掉很多循环语句,代码使用方面比Python原生list简单的多。
3.向量化运算,也可以理解为并行运算
numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算
4.Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制
总结:
使用Numpy科学计算库其效率远高于原生Python代码实现科学计算,Numpy可以称之为Python之光!!!