某天,隔壁大神正在看一份内核技术文档,我想研读下文档向大神“偷师”,恰好我的虚拟XP桌面无法使用搜索功能,而且项目组一般是一起使用共享目录的,这就导致大量资料杂糅在一起,我要找到大神的"葵花宝典"难上加难。
在日常工作中,大家基本都要自己记录重要文件路径,或者通过一层又一层目录去查找需要的文件,这不仅大海捞针,而且相当费时!
今天就为大家分享如何使用Python查找你最需要的文件,分为四个版本(初级、中级、高级、传说),默认以Win形式演示。
大纲
1. 介绍os.walk遍历目录树
2. 查找文件代码
2.1 初级查找
2.2 中级查找
2.3 高级查找
2.4 传说查找
3. Linux查找演示
01
介绍os.walk遍历目录树
在实际工作中,极有可能会遇到查找某个目录及其子目录下的所有文件。例如,查找某个目录及其目录下的所有的图片文件或者所有的Word文件名,查找某个目录及其子目录最大的十个文件。对于每个目录而言,os.walk返回一个三元组(dirpath,dirnames,filenames)。
dirpath:保存的是当前目录。
dirnames:当前目录下的子目录列表
filenames: 当前目录下的文件列表。
02
查找文件代码
本次默认Windows查找文件,演示的图片如下
主目录:F:\python\演示\流浪地球计划
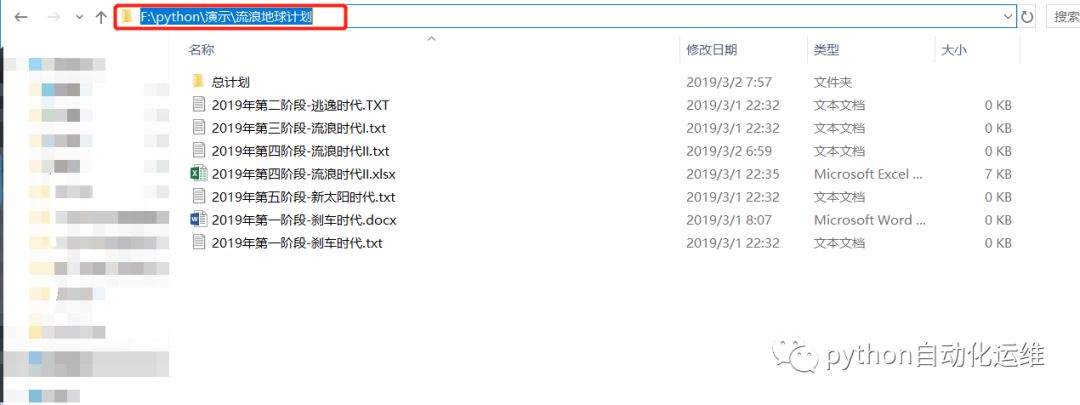
子目录:F:\python\演示\流浪地球计划\总计划
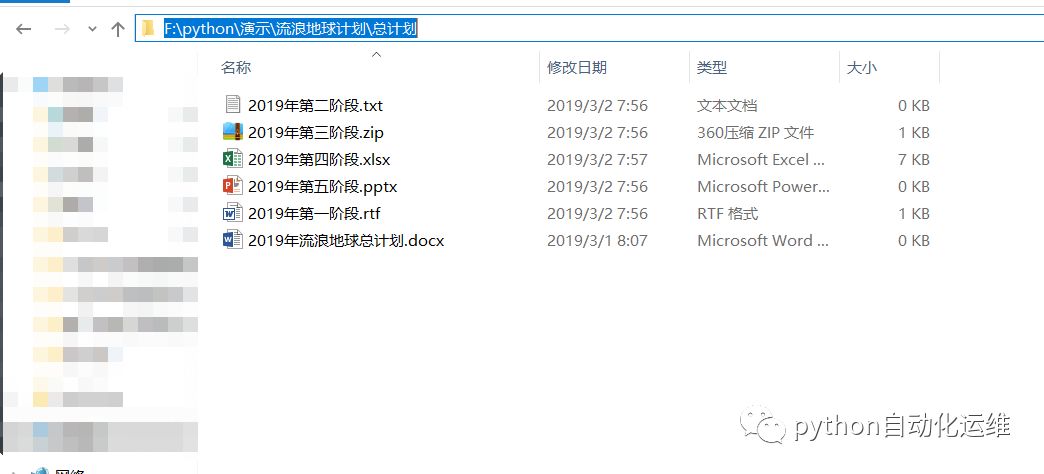
1. 初级查找文件(findfile_v1.py)
1import os
2
3def getFilepath(rootDir):
4 filepathresult = [] # 所需要的文件路径的集合
5 for dirpath,dirNames,fileNames in os.walk(rootDir):
6 for fileName in fileNames:
7 apath = os.path.join(dirpath, fileName)
8 filepathresult.append(apath)
9 for i in range(len(filepathresult)):
10 print(filepathresult[i])
11
12if __name__ == '__main__':
13 rootDir = r'F:\python\演示\流浪地球计划\\'
14 getFilepath(rootDir)
1.1 重点代码详解
1)执行流
rootDir:根目录(即需要查找的目录)
2)第7行 apath :文件的绝对路径
os.path.join(dirpath ,fileName) : 将当前目录和文件名组合
1.2 初级查找文件优缺点
优点:便捷,可以把该目录所有文件都查询出来。
缺点:无法根据文件名关键字或者指定文件类型进行筛选。
1.3 执行演示
初级查找文件findfile_v1.py确实是没有在带任何过滤的情况下,把该目录的所有文件都查询出来了。
2. 中级查找文件(findfile_v2.py)
1import os
2
3def getFilepath(rootDir,filepathmsg,filetype):
4 filepathresult = []
5 for dirpath,dirNames,fileNames in os.walk(rootDir):
6 for fileName in fileNames:
7 apath = os.path.join(dirpath ,fileName)
8 apathname = os.path.splitext(apath)[0]
9 apathtype = os.path.splitext(apath)[1]
10 if filetype == apathtype:
11 if filepathmsg in apathname:
12 filepathresult.append(apath)
13 for i in range(len(filepathresult)):
14 print(filepathresult[i])
15
16if __name__ == '__main__':
17 rootDir = r'F:\python\演示\流浪地球计划\\'
18 filepathmsg = "2019年"
19 filetype = ".txt"
20 getFilepath(rootDir,filepathmsg,filetype)2.1 重点代码详解
1)执行流
filepathmsg :文件名关键信息(字符串类型)
filetype :文件扩展名(字符串类型)
2) 第4行 filepathresult :为所需要的文件路径的集合
3)第8行 apathname = os.path.splitext(apath)[0]
4)第9行 apathtype = os.path.splitext(apath)[1]
os.path.splitext:返回一个除去扩展名的部分和扩展名的二元组
apathname:为路径+文件名,不包括扩展名
apathtype :为文件类型,得到"."+ "扩展名"
2.2 中级查找文件优缺点
优点:搜索唯一指定文件名关键字加指定的文件类型。
缺点:无法搜索多个文件名关键字或者多个指定的文件类型。
2.3 执行演示
中级查找文件findfile_v2.py,过滤信息为文件名信息"2019年"和文件类型".txt",符合该过滤信息的文件名(含子目录)都被筛选出来。有个要点,老铁们要注意,如果文件路径符合文件名关键字信息,也是会被筛选出来的!因为apathname包含路径和文件名(即除扩展名)。
3. 高级查找文件(findfile_v3.py)
1import os
2
3def getFilepath(rootDir,filepathmsg,filetype):
4 filepathresult = []
5 for dirpath,dirNames,fileNames in os.walk(rootDir):
6 for fileName in fileNames:
7 apath = os.path.join(dirpath ,fileName)
8 apathname = os.path.splitext(apath)[0]
9 apathtype = os.path.splitext(apath)[1]
10 for i in filetype:
11 if i in apathtype:
12 for j in filepathmsg:
13 if j in apathname:
14 filepathresult.append(apath)
15 for i in range(len(filepathresult)):
16 print(filepathresult[i])
17
18if __name__ == '__main__':
19 rootDir = r'F:\python\演示\流浪地球计划\\'
20 filetype = [".TXT",".xlsx",".docx",".txt"]
21 filepathmsg = ["流浪时代II","新太阳时代","逃逸时代"]
22 getFilepath(rootDir,filepathmsg,filetype)3.1 重点代码详解
1)执行流
filepathmsg :字符串(中级版)转变为数组(高级版)
filetype :字符串类(中级版)转变为数组(高级版)
2)第10-11行 循环判断体(文件类型)
3)第12-13行 循环判断体(文件路径/文件名)
3.2 高级查找文件优缺点
优点:可以进行多个文件名关键信息和多个扩展名进行联合查找。
缺点:若搜索更广的范围,查找时间就会更长。
3.3 执行演示
3.3.1 执行源码
执行源码可以发现符合文件名关键字信息和文件类型都查询出来了,没有docx的出现是因为没有符合文件名关键字信息。那究竟谁才是主,谁才是次呢?
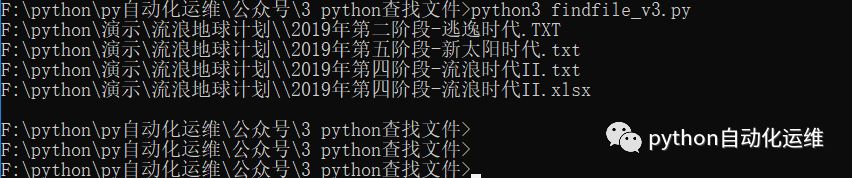
3.3.2 修改逻辑演示
将上述执行流代码修改如下:
1filetype = [".TXT",".xlsx",".docx",".txt"]
2filepathmsg = ["流浪时代II","新太阳时代","逃逸时代","第三阶段"]
执行代码,可以发现子目录的"2019年第三阶段.zip"没有被查询出来,可是文件名关键字信息不是有"第三阶段"吗?怎么回事?老铁们如果这里有点懵了,可以回看代码。第一次执行循环判断体是文件类型,第二次执行循环判断体是关键文件名信息。如果第一次判断都不符合,就不会进入第二循环判断体了。
设计思路:如果你想查找更多文件类型,那filetype少填写,不就OK了吗?如果你知道要的是什么文件类型,那就多填写几个!
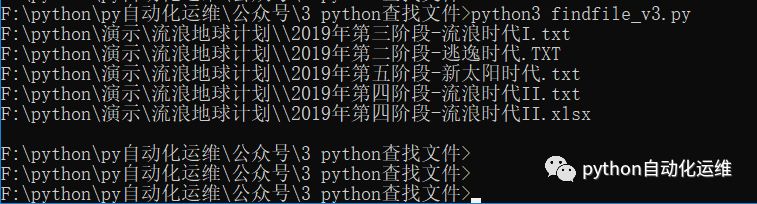
03
Linux演示
演示的文件如下,和Win的演示大致相同。
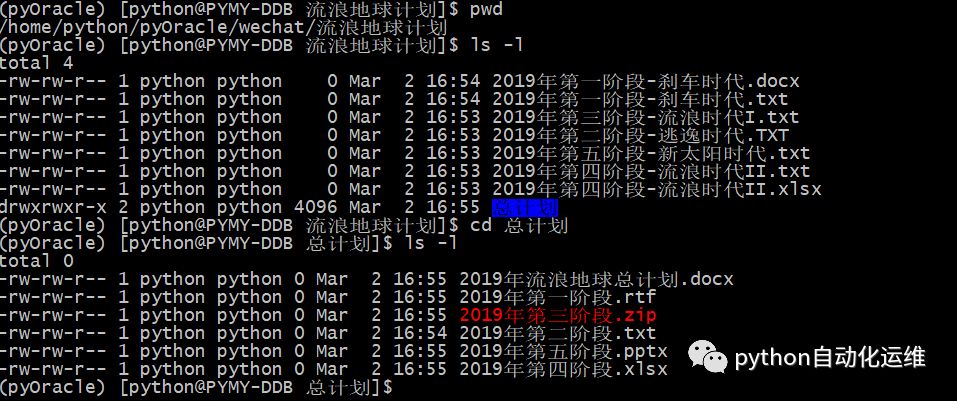
1 初级查找
1(pyOracle) [python@PYMY-DDB findfile]$ pwd
2/home/python/pyOracle/findfile
3(pyOracle) [python@PYMY-DDB findfile]$ cat findfile_v1.py
4#!/usr/bin/python
5# coding=utf8
6import os
7
8def getFilepath(rootDir):
9 filepathresult = []
10 for dirpath,dirNames,fileNames in os.walk(rootDir):
11 for fileName in fileNames:
12 apath = os.path.join(dirpath, fileName)
13 filepathresult.append(apath)
14 for i in range(len(filepathresult)):
15 print(filepathresult[i])
16if __name__ == '__main__':
17 rootDir = r'/home/python/pyOracle/wechat/流浪地球计划//'
18 getFilepath(rootDir)
初级查找演示结果
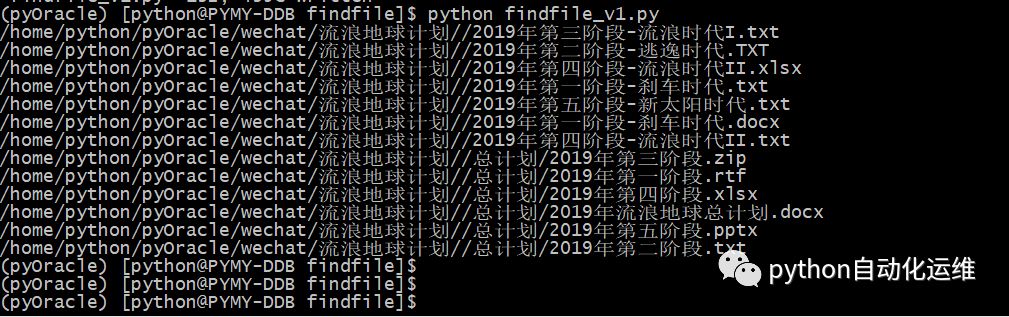
2 中级查找
1(pyOracle) [python@PYMY-DDB findfile]$ pwd
2/home/python/pyOracle/findfile
3(pyOracle) [python@PYMY-DDB findfile]$ cat findfile_v2.py
4
5#!/usr/bin/python
6# coding=utf8
7import os
8def getFilepath(rootDir,filepathmsg,filetype):
9 filepathresult = []
10 #for maindir,subdir,file_name_list in os.walk(dirpath):
11 for dirpath,dirNames,fileNames in os.walk(rootDir):
12 for fileName in fileNames:
13 apath = os.path.join(dirpath ,fileName)
14 apathname = os.path.splitext(apath)[0]
15 apathtype = os.path.splitext(apath)[1]
16 if filetype == apathtype:
17 if filepathmsg in apathname:
18 filepathresult.append(apath)
19 for i in range(len(filepathresult)):
20 print(filepathresult[i])
21if __name__ == '__main__':
22 filepathmsg = "2019年"
23 rootDir = r'/home/python/pyOracle/wechat/流浪地球计划//'
24 filetype = ".txt"
25 getFilepath(rootDir, filepathmsg, filetype)
中级查找演示结果

3 高级查找
1(pyOracle) [python@PYMY-DDB findfile]$ pwd
2/home/python/pyOracle/findfile
3(pyOracle) [python@PYMY-DDB findfile]$ cat findfile_v3.py
4#!/usr/bin/python
5# coding=utf8
6import os
7
8def getFilepath(rootDir,filepathmsg,filetype):
9 filepathresult = []
10 for dirpath,dirNames,fileNames in os.walk(rootDir):
11 for fileName in fileNames:
12 apath = os.path.join(dirpath ,fileName)
13 apathname = os.path.splitext(apath)[0]
14 apathtype = os.path.splitext(apath)[1]
15 #for i in range(len(filetype)):
16 for i in filetype:
17 if i in apathtype:
18 #for j in range(len(filepathmsg)):
19 for j in filepathmsg:
20 if j in apathname:
21 filepathresult.append(apath)
22 for i in range(len(filepathresult)):
23 print(filepathresult[i])
24
25if __name__ == '__main__':
26 rootDir = r'/home/python/pyOracle/wechat/流浪地球计划//'
27 filetype = [".TXT",".xlsx",".doc",".txt"]
28 filepathmsg = ["流浪时代II","新太阳时代","逃逸时代","第三阶段"]
29 getFilepath(rootDir,filepathmsg,filetype)
高级查找演示结果

最后
细心的老铁有没有发现,为什么rootDir最后面的路径多要加"\\"(Win)或”//“(Linux),其实是为了转义。
"安老师,说好的传说皮肤呢?"。
“是说好的传说版的代码吧?不用急,本次分享消耗了安老师太多的功力
有机会再跟大家分享秒级查找方法哈
"
可能你会问,找文件用python干嘛?当然是方便老铁们找羞羞的电影入门学习啦!你把文件夹藏起来都没有用,它都能到喔!