一、前言
BIGO旗下应用有多个内容流推荐场景,用户在内容流可以浏览图片、视频、音乐、链接等内容,推荐系统在内容的个性化分发中,发挥着重要的作用。本文将结合我们在BIGO内容流推荐中深度学习的具体实践,重点分享在多目标排序优化中的实践经验。
二、排序中多目标模型的应用
内容流场景是天然的多目标场景,核心目标是推荐用户感兴趣的内容,提升用户时长;兼顾点赞、关注、评论、分享等不同维度的目标,优化用户体验。多个目标如何建模;如何在样本分布不均衡时充分学习;如何调权融合,是多目标排序要解决的问题和难点。
深度神经网络凭借优秀的表达能力、灵活性、适用性在诸多领域和场景中有显著提升,我们在该框架下从单目标模型到多目标模型逐步探索。
1、单目标模型
内容流第一次上线DNN模型使用了单目标模型,采用经典的embedding+mlp结构:embedding对高纬稀疏特征进行表达,将高维离散空间映射到低维连续空间,相同类型稀疏特征会当作一个field(如用户点赞的视频集合),field内进行池化操作,之后与其他field及稠密特征拼接形成mlp的输入;多层mlp学习特征之间的高阶交叉组合,最终输出预测结果。Embedding和mlp在训练过程中同步更新,简单理解,embedding可以看做特征提取器,mlp则为特征组合器;端到端学习能够充分发挥深度模型的拟合能力。
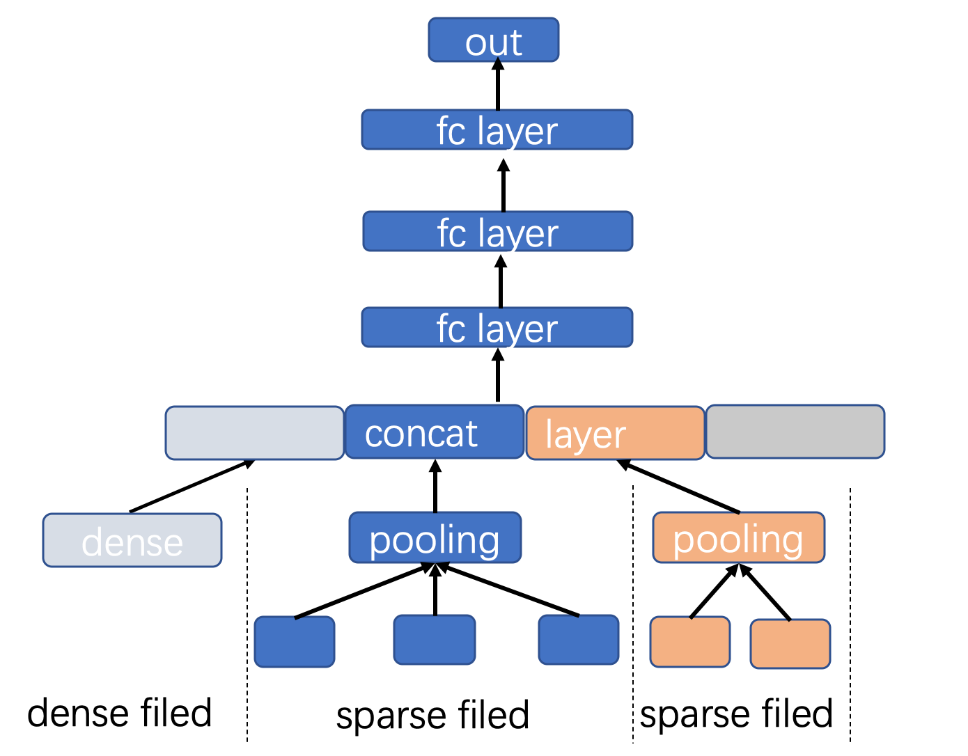
(图注:单目标模型)
单目标模型预测单个目标是直观自然的,如何实现多目标优化,我们尝试了多种方案:
● Label 融合:点击、播放、点赞等行为都看作正样本,不同的行为给予不同权重来平衡不同样本的比例,在考虑主要目标的基础上优化其他目标,近似实现多目标的优化。其他目标通过权重折算为主要目标,合理的权重需要通过多次AB测试结合效果来确定;每次调整样本分布会发生变化,模型也需重新训练模型,整个流程周期较长;在线也无法动态调整权重配比,迭代较慢。
● 多模型融合:每个目标单独训练一个DNN模型,分别预测出不同目标。一方面由于推荐领域的深度模型99%的参数位于Embedding层,分别训练多个模型算力和资源消耗随着目标增加会线性增长;另一方面低频目标(如点赞、分享)相较于主目标样本量较少,目标间不能共享有用信息,容易导致欠训练或者过拟合,预测方差较大。
上述方案在初步阶段能解决部分问题,但存在诸多限制,我们在网络结构上进行改造演进到多目标模型。
2、多目标模型
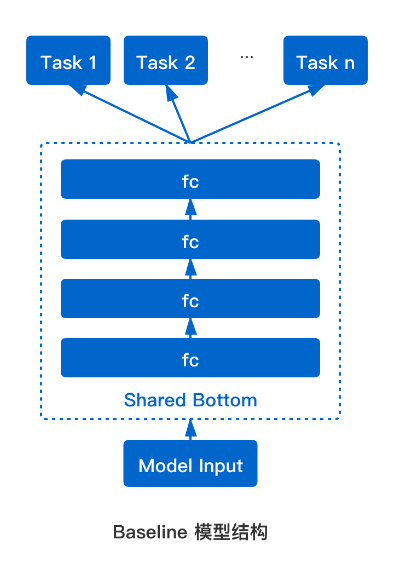
基于DNN灵活的结构可以让单个模型同时学习多个目标。Shared-Bottom结构加强底层参数和网络共享,学习公共特征表示,在最终输出前进行拆分;每个目标通过自己的全连接参数层学习预测单个目标。在反向传播时公共部分的梯度会求和后进行一次更新,因此离线训练计算量基本和单目标网络持平或略有上涨;预测时每个目标都会有打分,可结合业务场景和效果灵活进行在线调整。共享Embedding+Shared-Bottom结构使得多目标网络比较好地平衡了资源消耗、模型性能、方便调整等几个方面的需求,是一种性价比很高,目前推荐领域应用很广的技术。
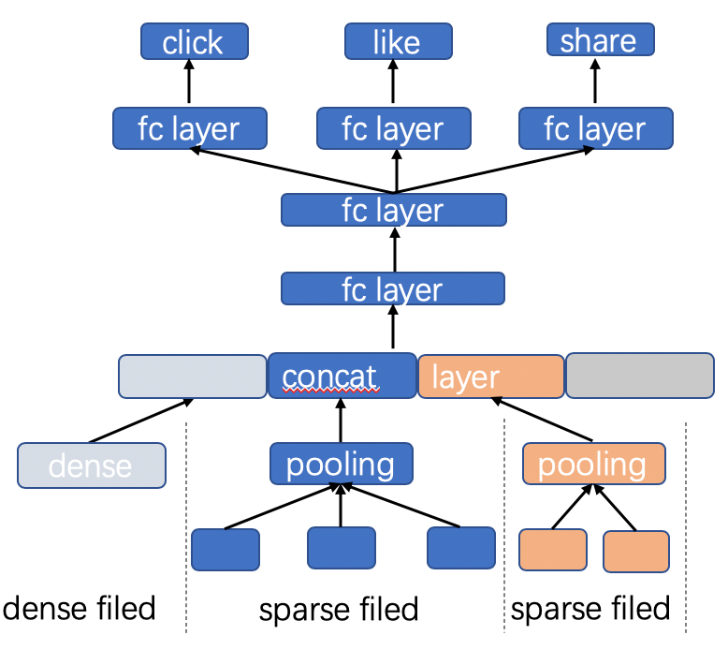
(图注:多目标模型)
三、多目标模型优化
引入多目标排序在业务实践中收获了巨大提升,但它也带来新的挑战:共享底层导致参数会被占绝大多数样本的目标所控制,目标间互相影响限制了差异性比较大的目标,如何让各个目标学习的更精准;多个目标以什么样的方式进行权衡融合,才能让业务指标收益最大化。
我们主要研究了两个方向:参数共享机制和目标权重融合调参。
1、参数共享机制
从单目标发展到多目标,排序模型获得更多的灵活性和更好的拟合效果。一般的多目标模型使用Share-Bottom结构,这是一种硬参数共享(Hard-Parameter-Sharing)的方法。在硬参数共享的模型中,各个目标共享哪些参数和共享方式是确定的。不精确地说,参数共享的层数越多,某些目标的拟合精度会下降同时泛化能力上升,因为模型更多捕捉了公共表示,而完全不共享MLP参数,因为损失了一部分公共表示的信息,会使得稀疏目标训练的方差较大。在imo内容流的实践中,我们进行了多组硬参数共享实验,差别并不明显。
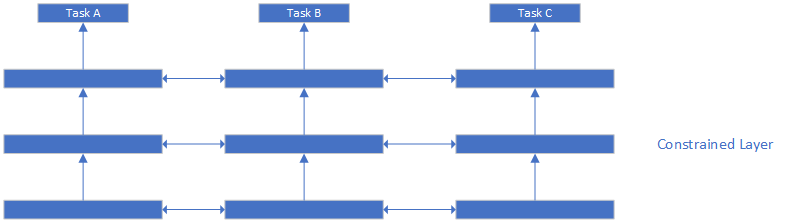
(图注:对多目标施加一致性约束)
而软参数共享(Soft-Parameter-Sharing)希望使用自适应的方法发现参数最好的共享方式,或者对一些参数施加一致性约束,从而避免多目标之间的表示学习相互干扰。使多目标之间尽可能共享公共的表示。软参数共享也解决了多目标一些遗留问题,比如任务之间的互相依赖或者互相独立都会影响模型的性能,软参数共享可以有目的地避免这些问题。
在参数共享方面学术界和工业界都进行了很多探索,我们在进行技术选型时,考虑了如一致性约束、Cross-Stitch(十字绣网络)、通过NAS(网络结构搜索)等。MMoE相比其他技术有一些显著优势,如针对推荐领域设计,网络简洁清晰,对于目标间的Negative Transfer抑制明显等。
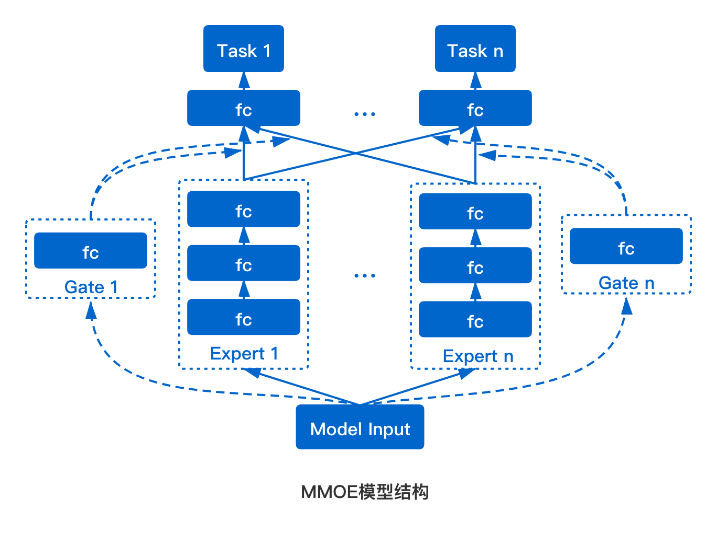
(图注:MMoE模型结构对比)
MMoE模型使用了Mixture of Experts的结构建模多个任务之间的相关关系,把多个独立的mlp tower看成expert,所有目标共享expert通过每个目标的gate来控制不同expert的贡献。Gate如果与输入无关,则退化为multi tower dnn;Gate优雅的解决了目标之间独立性和共享性的难题,学习(expert,特征,目标)三元组之间的关系,用公式表达为:
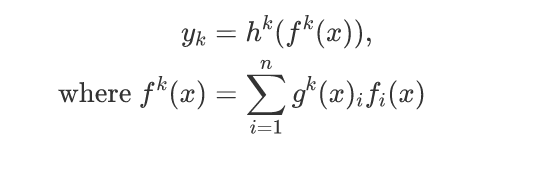
表示第i个expert网络;
表示控制第k个gate网络的第i维输出,由sigmoid激活函数输出到[0, 1];
表示分别输出目标值的网络。
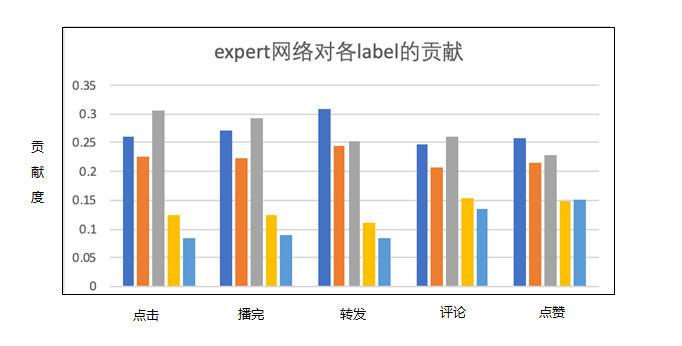
(图注:MMoE中expert对不同目标的贡献)
在MMoE的实验中,作者仿真了不同相关性的目标对学习效果的影响,证明了多目标网络对于目标关系是比较敏感的。内容流场景中,我们也进行了一些分析,通过记录各个expert对于最终结果的影响研究MMoE网络的多个expert是否是同质化的。通过上图可以看出,不同expert在不同gate的控制下,对于每个目标的贡献值是不同的。这说明MMoE的机制下,expert确实捕捉到了数据与不同目标之间的联系,expert之间形成了差异化的预测结果。我们对用户行为进行的数据分析显示出转评赞之间存在较强的依赖关系,消费指标和转评赞的相关关系较弱,时长、播完率、点击率也比较独立,这恰好也是MMoE比较匹配的引用场景。内容流场景上线MMoE后取得了整体消费1%~4%不等的收益,并在BIGO多个场景的实践中优化多目标参数共享都有比较确定的收益。
2、多目标在线融合
多目标排序模型的在线融合工作主要包括两方面:融合方法和融合参数寻优。
A.融合方法
通过多目标训练和预测,在线上我们能够得到推荐物料在多个目标维度上的预估分,在一个一般的精排系统中,多目标分数还需要融合成一个分数进行排序。
对于多目标融合,最直观的方法是线性融合,线性融合的参数满足约束,融合公式为
。
除了采取上述的线性融合方法,比较明显的优化点有加入指数因子和依赖关系。加入指数因子可以调整不同目标相对幅度有差距的问题,给多目标融合增加了非线性。刻画多目标之间的依赖关系最典型的方法是拆分CTR和CVR。拆分训练有多种方法,典型如全空间多任务模型(ESMM),这里就不展开介绍了。一般拆分CTR和CVR后,在线上融合时按照条件概率公式使用
B.参数寻优
推荐系统的多目标参数寻优不能简单看成离线流程,只通过离线训练样本评估多目标参数,比较有可能偏离真实结果。线上实时生成的结果数比样本中体现的更多,不容易在离线完全复现,希望多目标参数能从已曝光视频向未曝光视频泛化,是比较困难的。
在线多目标融合参数是一个典型的参数寻优问题,如上一节介绍的那样,融合公式越复杂,往往涉及到越多的超参数。简单两三个线性参数还可手工实验,一旦业务和模型复杂度提高,工程师则只能“拍脑门”定参数,或者疲于奔命进行实验。因此找到一种分布式的强鲁棒性的自动参数选择方法,对于推荐效果和解放人力大有裨益。
通过调整寻参过程中的Reward,我们可以将推荐系统的侧重点向某些指标倾斜,比如评论率、点击率等,对算法工程师和业务部门的合作也有帮助。在调整多目标时,通常我们有若干指标希望提升,但是前提是不能损失另一些指标,这一问题有一种比较通用的建模方法。举一个具体例子,问题表述为:
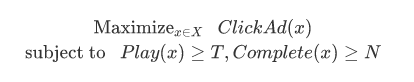
把优化目标记为,其中
是我们需要最大化的,其余目标的最低控制阈值记为
,如果希望得到某个目标的固定提升,可以把
设得略大一些。将这个带限制最优化问题,转化为一个参数平面光滑可导的函数,方法如下:
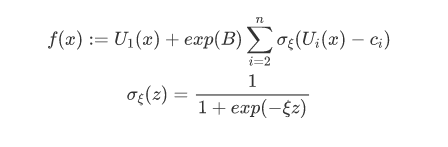
定义 σξ 函数是为了在满足限制时快速激活sigmoid,通常 ξ 设置为一个较大的数字。函数使用
作为满足条件的奖励项,将参数限制和最优化整合到一个公式中,方便作为梯度下降类算法或贝叶斯算法的目标函数。
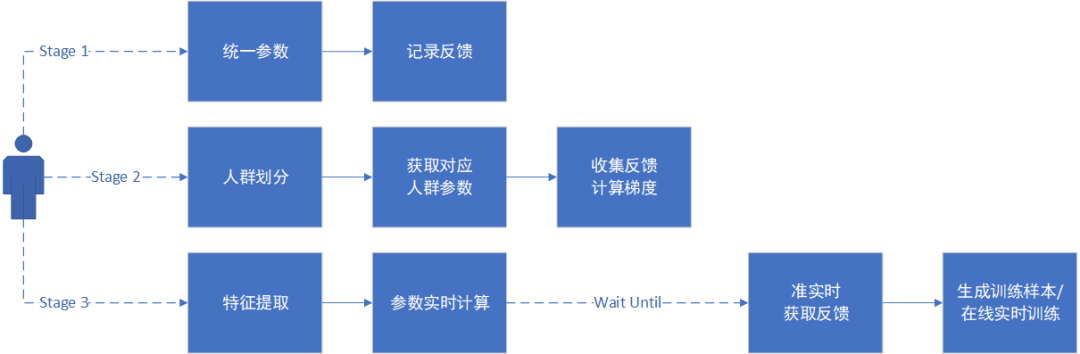
(图注:寻参的三阶段)
如下图所示,在内容流迭代中,我们按照参数和反馈粒度把多目标寻参分为整体寻参、场景化寻参、个性化寻参三个阶段。
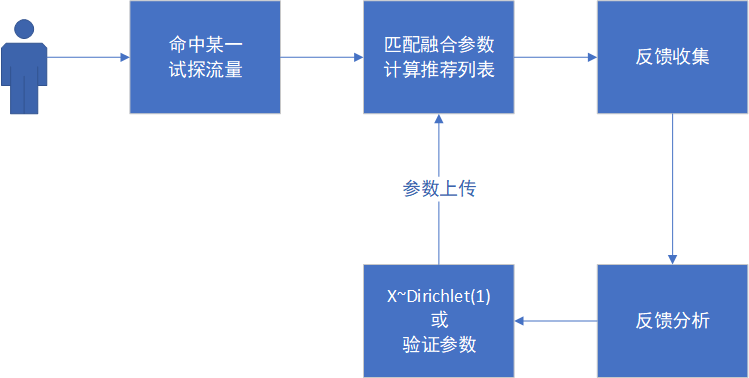
(图注:Grid-Search框架流程)
我们第一阶段采用了Grid-Search的方法,使用线上流量同时试探大量参数组合。记线上预估向量为X,采用线性加权,权重和为1的融合方法,对于n维的预估向量融合参数的自由度是(n-1),对这类融合参数的均匀采样相当于在一个n维Simplex中均匀采样,利用Dirchlet分布是多项分布的共轭先验这一点,我们可以快速地生成融合参数。利用AB实验平台划分流量,自动发布参数和收集反馈,最后计算Reward选择最优的若干组参数,就可以完成一个Grid-Search搜参系统的搭建。Grid-Search框架主要的局限性在于没有利用后验信息和没有降低反馈方差的方法,这两点制约了Grid-Search在更复杂和参数量更大的场景下的应用,但是作为一个实现简单且能很好利用用户并行的方法,比较适合自动寻参项目的启动阶段。
在获取暴力搜参的收益后,自动寻参的第二阶段可以拓展应用空间,也可以向场景化发展。这里举一些应用例子:
● 对于轻度用户和重度用户使用不同参数
● 对于不同展位、不同场景、不同时间分别寻参
● 在召回阶段使用自动寻参确定策略阈值
● 确定各个召回策略在粗排阶段的配额
● 使用更复杂的融合方法
场景化和更多样的使用方法对于寻参算法也提出了更高的要求。人群的细化带来反馈数据更加稀疏,参数量加大需要寻参算法能更快的收敛。为了解决第二阶段的主要问题,我们实验了多种方法框架。主要有:
● 贝叶斯优化方法,主要是一系列基于高斯过程的方法
● Natural Evolution Strategy(NES)
● 将参数视为多臂赌博机的Bandit系列算法
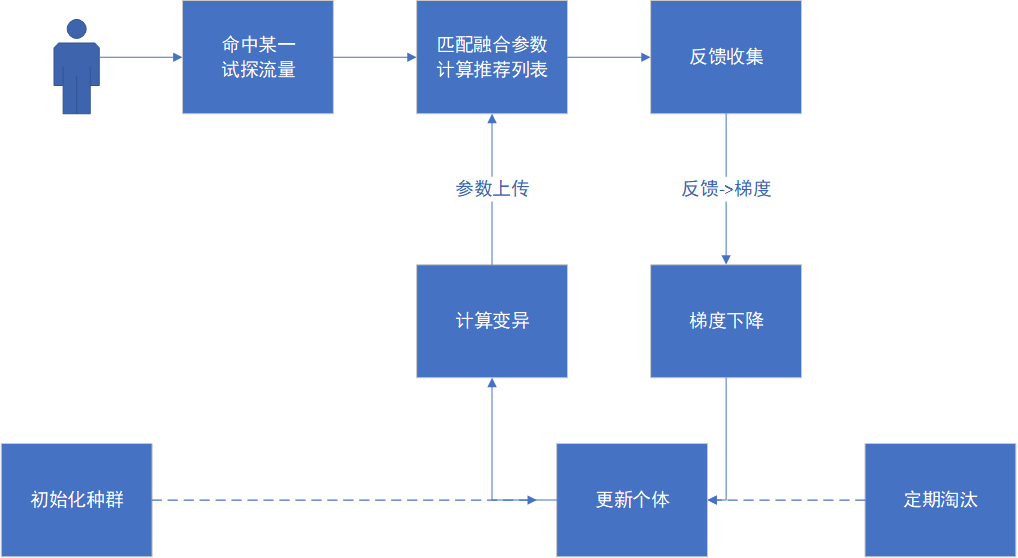
(图注:NES框架流程)
由于篇幅所限,我们主要介绍使用NES作为黑箱优化主框架的方法。这个方法受到了DBGD算法和OpenAI强化学习文章的启发。NES梯度求解过程来自REINFORCE算法:
这个公式把求解期望Reward的梯度转化成求解Reward的期望,只需要采样和计算反馈即可完成,使得NES不需要进行反向传播和求导操作,适用领域很广,尤其适合解决黑盒优化问题。这个公式的由来可以参考REINFORCE的推导:
NES使用梯度下降和遗传变异两个机制改进了搜索算法。
● 试探中的反馈方差可以理解为SGD中的噪声,前后噪声互相抵消使得参数向大致正确的方向前进,比较好地缓解了试探方差大的问题。
● 利用遗传变异机制,通过多样化的初始操作和变异操作可以避免陷入局部最优值,失败个体被淘汰,稳定提升的个体逐渐收敛。
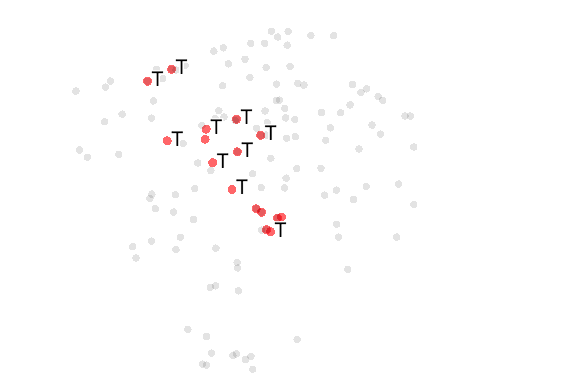
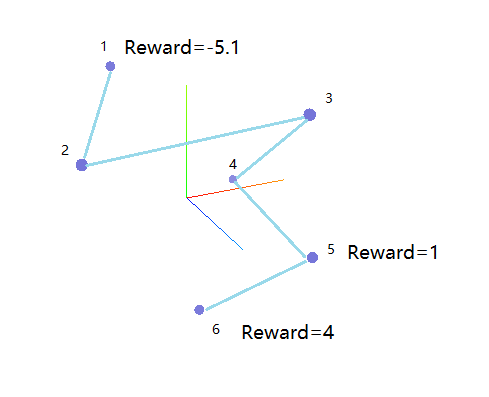
(图注:Grid-Search和NES的效率比较)
上图中左侧为Grid-Search一周时间收集到的几百组参数反馈,降维到二维空间的图像,红色点为显著好于基线的参数。右侧图为NES实验中,某个体经过5次梯度下降的结果,降维到三维空间中。从试探效率上比较,Grid-Search没有充分利用试探得到的后验信息,在实际表现中NES大约进行两天实验,就可以找到相比Grid-Search进行一周实验更好的参数。
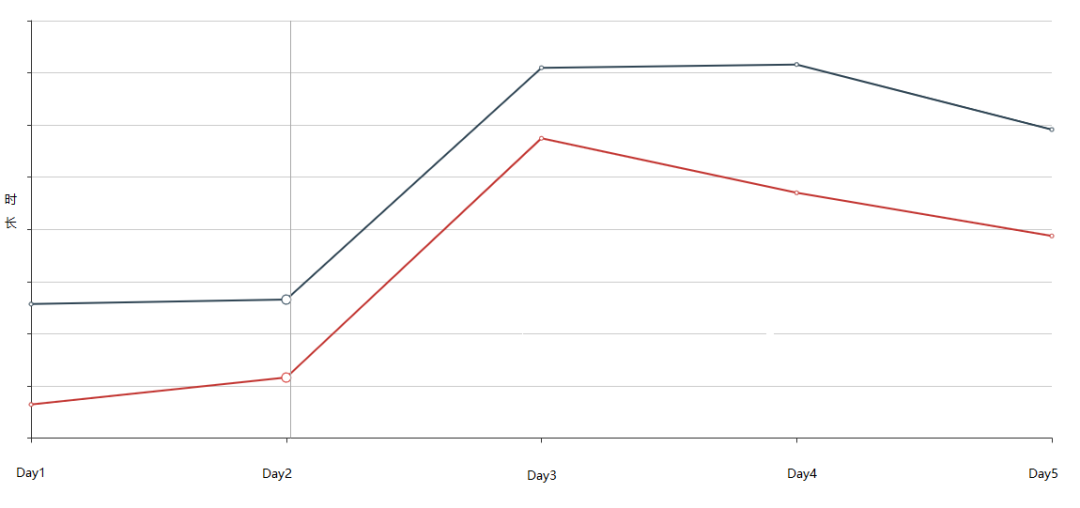
(图注:NES寻参线上实验效果)
在内容流的实践中,基于Grid-Search和NES的寻参都取得了显著的效果。首次应用自动寻参时,通过使推荐系统整体倾向播完率和时长目标,使全局有效播放数提升了10%+。上图为在第一阶段寻参基础上应用NES的进一步实验效果,试探速度的提升也使得自动寻参可以在更多的场景落地。
基于NES的方法已经隐含了一些强化学习的要素,但并没有引入模型。NES虽然可以进行分人群寻参,但是这要求对用户进行一个完善得划分,同时每一个分片中的用户量不能过少。如果想利用用户的特征和场景的特征进行寻参,又需要大量的样本进行训练,只能寻求模型化的方法,如DQN、Actor-Critic等,在这一方面我们正在积极探索。
四、总结
BIGO内容流业务经历了用户量从0到“亿”的飞跃,算法模型也从简单到复杂,单目标到多目标逐步演进。我们在单模型label融合,多目标网络共享参数,MMOE模型,在线自动搜参算法和框架等方面尝试前沿技术深入实践,通过自动化和算法化解决业务痛点。后续我们会在:网络共享、目标融合、异步任务引入、参数学习辅助任务等方向,结合业务场景持续迭代优化,取得进一步的突破。
Reference
[1] D. Agarwal, K. Basu, S. Ghosh, Y. Xuan, Y. Yang, and L. Zhang, “Online Parameter Selection for Web-based Ranking Problems,” Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018.
[2] Salimans, T., Ho, J., Chen, X., Sidor, S. and Sutskever, I., 2020. Evolution Strategies As A Scalable Alternative To Reinforcement Learning. [online] arXiv.org. Available at:[Accessed 13 July 2020].
[3] Ma, X., Zhao, L., Huang, G., Wang, Z., Hu, Z., Zhu, X., & Gai, K. (2018). Entire Space Multi-Task Model. The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. doi:10.1145/3209978.3210104
[4] Zhao, Z., Hong, L., Wei, L., Chen, J., Nath, A., Andrews, S., . . . Chi, E. (2019). Recommending what video to watch next. Proceedings of the 13th ACM Conference on Recommender Systems. doi:10.1145/3298689.3346997
[5] Covington, P., Adams, J., & Sargin, E. (2016). Deep Neural Networks for YouTube Recommendations. Proceedings of the 10th ACM Conference on Recommender Systems. doi:10.1145/2959100.2959190
[6] Misra, I., Shrivastava, A., Gupta, A., & Hebert, M. (2016). Cross-Stitch Networks for Multi-task Learning. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). doi:10.1109/cvpr.2016.433
[7] Williams, R. J. (1992). Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Reinforcement Learning, 5-32. doi:10.1007/978-1-4615-3618-5_2
版权声明
转载本网站原创文章需要注明来源出处。因互联网客观情况,原创文章中可能会存在不当使用的情况,如文章部分图片或者部分引用内容未能及时与相关权利人取得联系,非恶意侵犯相关权利人的权益,敬请相关权利人谅解并联系我们及时处理。
关于本文
本文首发于公众号【BIGO技术】,感兴趣的同学可以移步至公众号,获取最新文章~
