NSGA-II学习笔记
阅读文献:A Fast and Elitist Multiobjective Genetic Algorithm:
NSGA-II
有兴趣的话可以阅读中文翻译版本:https://wenku.baidu.com/view/61daf00d0508763230121235.html
简介
从学长那里得知,NSGA-II和MOEAD是多目标优化算法的经典算法,不了解这两个讲点算法,相当于白学了多目标优化算法,很多算法也是基于NSGA-II和MOEAD来进行改进和拓展,从而衍生出一系列算法。
下面我先介绍一下NSGA-II
NSGA-II 是由Deb跟他的学生在2000年提出了NSGA的改进版本。NSGA2采用快速非支配排序以及拥挤距离的策略,时间复杂度在O(MN2)。由于其速度及效果上的优势,许多年来NSGA2都被作为对比算法。
下面来说一下,NSGA-II相比于NSGA有以下三点改进:
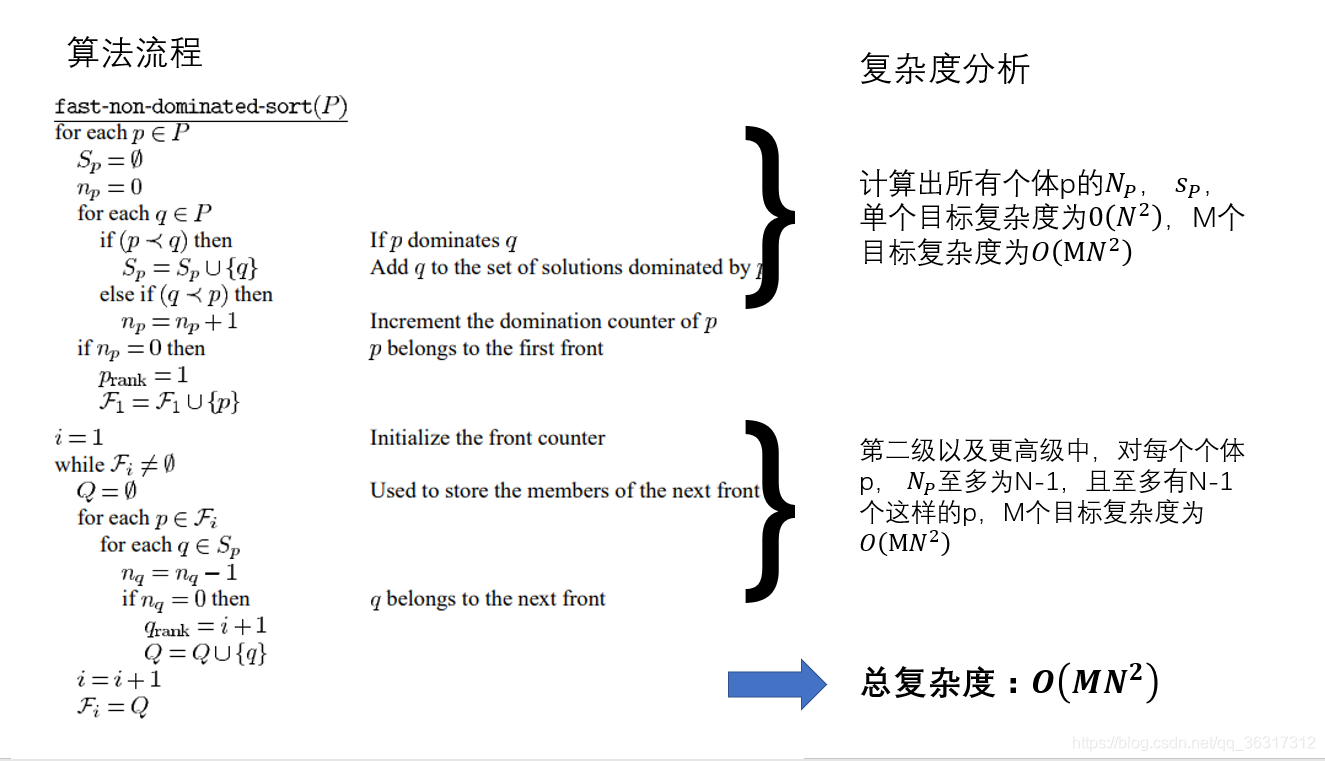
1.提出快速非支配排序算法,是计算复杂度由计算复杂度O(MN^3 )降低为O(MN^2 )
2.引入精英策略,扩大采样空间。将父代种群与其产生的子代种群组合,共同竞争产生下一代种群,有利于保持父代中的优良个体进入下一代,保证某些优良的种群个体在进化过程中不会被丢弃,从而提高了优化结果的精度。并通过对种群中所有个体的分层存放,使得最佳个体不会丢失,有效提高种群水平。
3.采用拥挤度和拥挤度比较算子,不但克服了NSGA中需要人为指定共享参数的缺陷,而且将其作为种群中个体间的比较标准,使得准Pareto域中的个体能均匀地扩展到整个Pareto域,保证了种群的多样性。
具体
1.大体算法流程
确定种群大小 n,交叉概率 t,迭代次数 g
随机产生 n 个个体,它们整体视为种群 P
for i = 1 to g
P’ = ∅
for j = 1 to n
产生一个 [0,1] 的随机数 a
if (a<t)
从 P 中随机选出两个个体作为父母,交叉产生一个新的个体并放入 P’ 中
else
从 P 中随机选出一个个体,变异产生一个新的个体并放入 P’ 中
end
end
利用非支配排序和拥挤距离,从 P∪P’ 中选出 n 个个体, 代替 P
end
输出最终种群 P 中的**非支配个体**

2.快速非支配排序
传统的NSGA排序方法:计算复杂度O(MN3) ,M为目标个数,N为种群大小。计算第一帕累托前沿时,每个解都要与其他N-1个解比较M次,即比较次数为M*(N-1)*N,则计算的复杂度为O(MN2),
如果按照最坏的打算来看的话,即每个解占一个前沿,每个前沿中只有一个解的时候,则计算的复杂度是O(MN3)。
在经过改进的NSGA-II的快速非支配算法中,计算的复杂度为O(MN2).
在上篇博客已经写到支配和非支配之间的关系以及表示形式,不熟悉的可以看上一篇博客。

符号含义:
•种群:P(大写)
•个体:p,q
•NP:支配个体p的个体数量
•SP:被个体p支配的个体集合
根据上图我们可以分析到对于每个种群P而言,p是属于P中的,SP所支配的集合不为空,NP一开始为0,如果p支配于q,那么个体q将并入Sp集合中,如果p被q支配,那么NP自动加一,如果NP为0,那么将是帕累托第一前沿,将p并入F1(第一帕累托前沿)。接着,访问帕累托最优解中S的集合中的解,对每个个体p被访问后,则所支配的个体q,Nq减一,Qrank=i+1。其中若有解对应n值为0,则保存至下一前沿面Frank+1 ,重复上一步骤,直到所有解都划分到对应的前沿面中。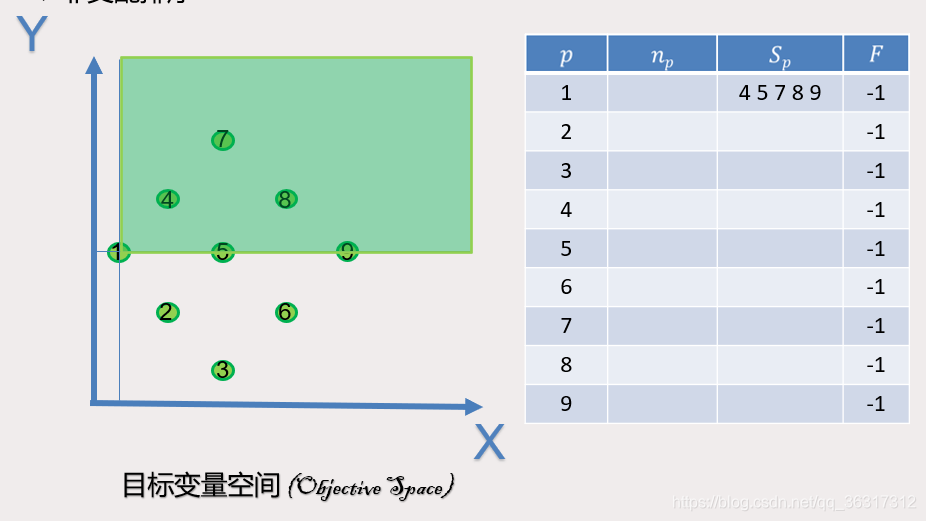
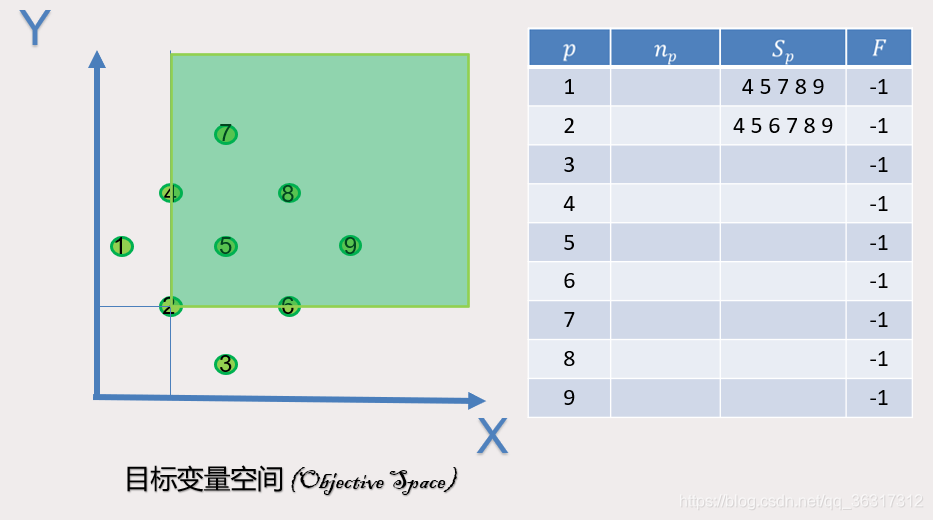
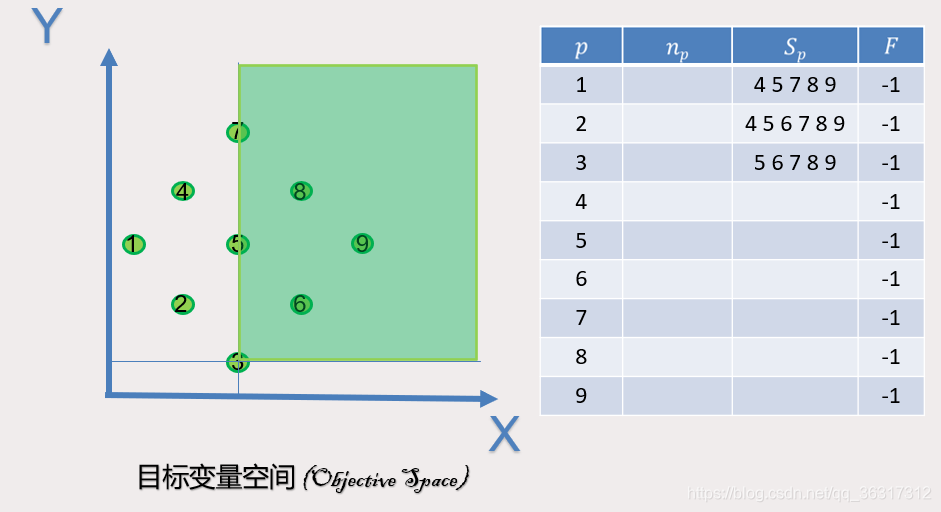
同理可得出以下的4.5.6.7.8.9各个点支配情况
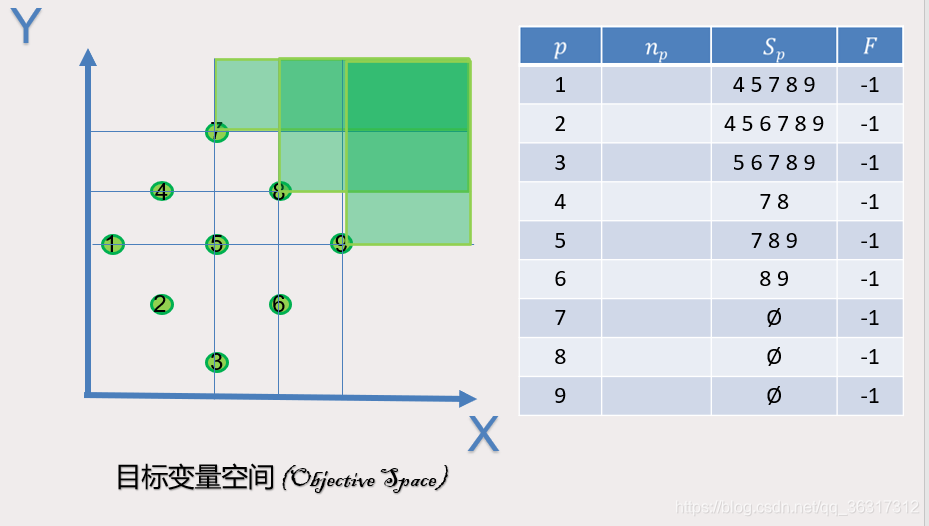
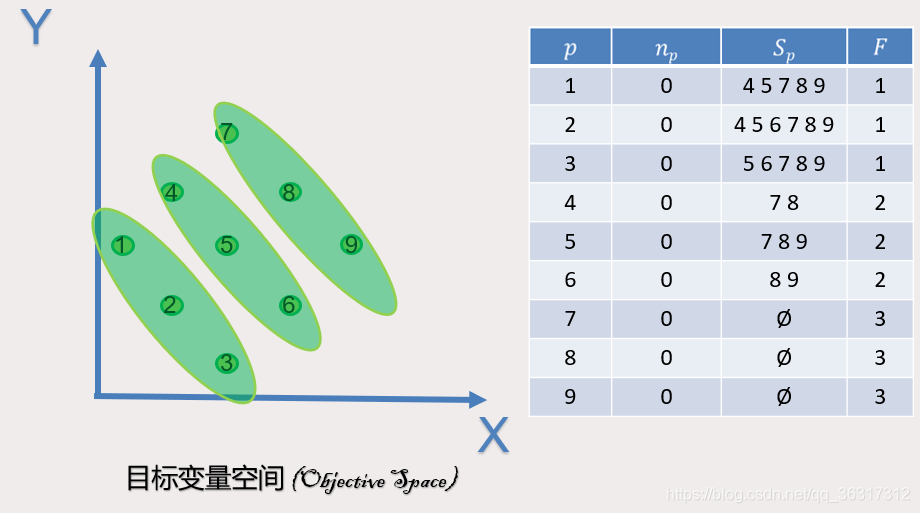
我们可以看出1,2,3号点并没有被支配,所以为第一帕累托前沿Np为0,同理可得,4号点被1,2号支配,Np为2,以此类推,N5=3,N6=2,N7=5,N8=6,N9=5。通过下面这张图,通过这张可以非常直观的看到NP和SP的具体情况。

对于4号点,当1号点进行确定后,则1号多支配的4,5,7,8,9的NP-1

以此类推,则可以看到下图,以及Frank的情况
3.拥挤比较算子
拥挤度
•目的 同一层非支配个体集合中,为了保证解的个体能均匀分配在Pareto前沿,就需要使同一层中的非支配个体具有多样性,否则,个体都在某一处“扎堆”。NSGA—II采用了拥挤度策略,即计算同一非支配层级中某给定个体周围其他个体的密度。
•计算 每个个体的拥挤距离是通过计算与其相邻的两个个体在每个子目标函数上的距离差之和来求取

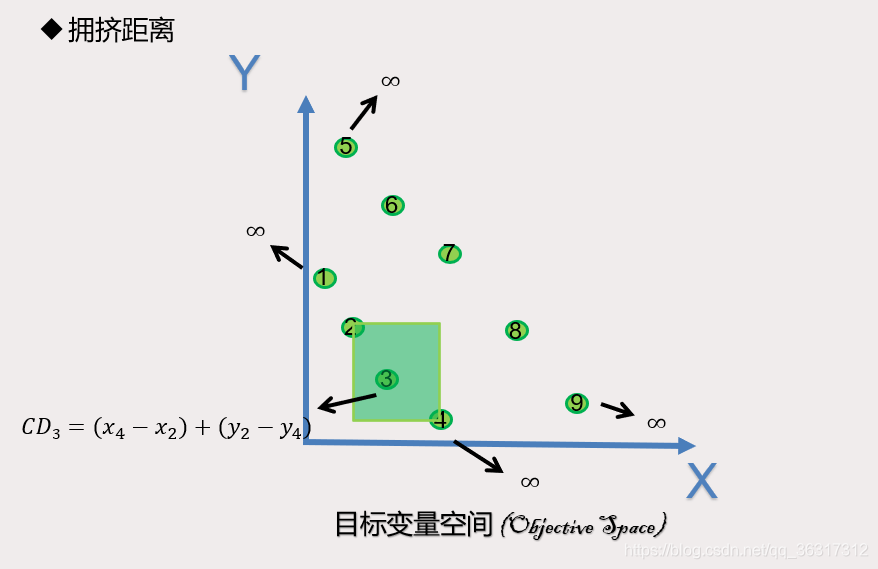
就是在目标变量空间,两个个体在每个子目标函数上的距离差之和来求取拥挤距离。
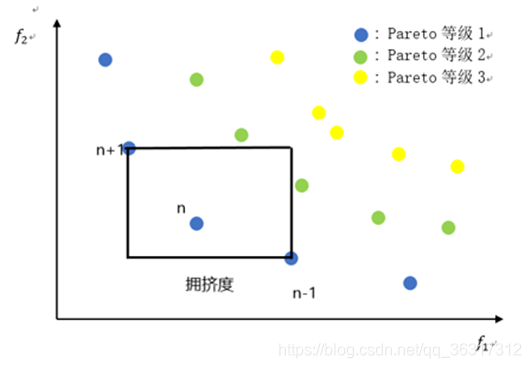
经过快速非支配排序和拥挤度计算之后,种群中每个个体拥有两个属性:非支配等级ⅈrank和拥挤度id
定义偏序<n如下:
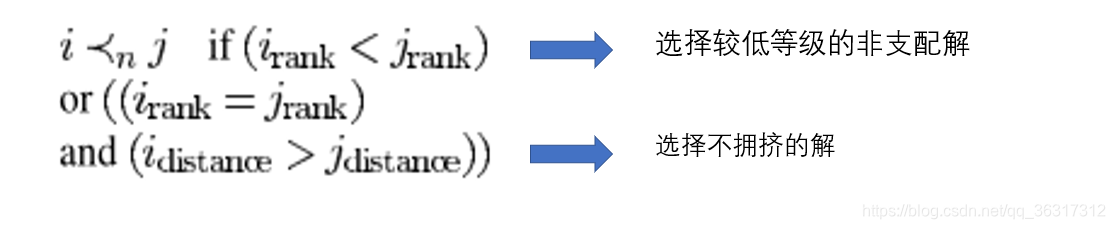
4.精英策略
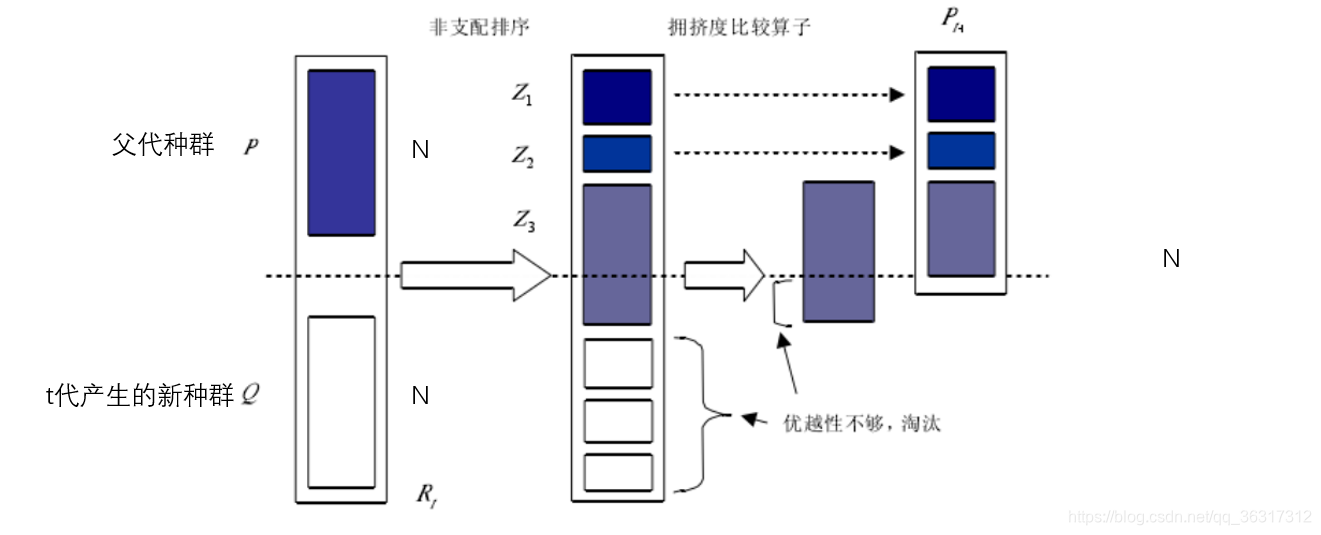
在父代种群p和t代产生的新种群Q中,通过非支配排序可以选择出帕累托最优解靠前的前沿面Z1,Z2,对于Z3来说,整体数量已经超过N,可以通过拥挤度比较算子来选择比较优越的个体,从而淘汰不够优越的个体,最终使得父代获得一个整体为N 的个体数量。
总结
这是我个人理解的NSGA-II算法大概思想,希望能够帮到大家,也是初学多目标优化算法,如果有一些不对的地方还请大佬们进行批评指正,同时也借鉴了https://blog.csdn.net/qq_35414569/article/details/79639848 这篇博客,使我受益匪浅。