python数据分析及其可视化实例
目录
一,数据来源
数据来源一般有两种方式,一是通过爬虫爬取的数据文件,二是原有的数据集。
1.爬虫获取数据
1.爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码,可用开发者工具获取获取网页所需的headers信息,以及通过查看源代码得到编码格式。源代码里包含了网页的部分有用信息,所以只要把源代码获取下来,就可以从中提取想要的信息了。前面讲了请求和响应的概念,向网站的服务器发送一个请求,返回的响应体便是网页源代码。所以,关键的部分就是构造一个请求并发送给服务器,然后接收到响应并将其解析出来, Python 提供了许多库来帮助我们实现这个操作,如 urllib、requests 等。我们可以用这些库来帮助我们实现 HTTP 请求操作,请求和响应都可以用类库提供的数据结构来表示,得到响应之后只需要解析数据结构中的 Body 部分即可,即得到网页的源代码,这样我们可以用程序来实现获取网页的过程了。
2.获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错。提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
3.提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为 TXT 文本或 JSON 文本,也可以保存到数据库,如 MySQL 和 MongoDB 等,也可保存至远程服务器,如借助 SFTP 进行操作等。
4.自动化程序是说爬虫可以代替人来完成这些操作。首先,我们手工当然可以提取这些信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序。爬虫就是代替我们来完成这份爬取工作的自动化程序,它可以在抓取过程中进行各种异常处理、错误重试等操作,确保爬取持续高效地运行。
2.原有数据
通常原有数据都用csv文件保存,这里所用到的实例就是csv文件,如下图

这是2020 01 22到2020 02 04的疫情数据,Confirmed是当天确诊人数,Deaths是当天死亡人数,Recovered是当天恢复人数。
二,数据分析及其可视化
1.获取某两天的柱状图进行比较
首先需要读取文件取出中国大陆的疫情数据保存到data,再取出其中某天的疫情数据保存到data1,去除不必要的数据,方便可视化。源代码如下:

运行结果如下图:取的是2020 01 23日的数据
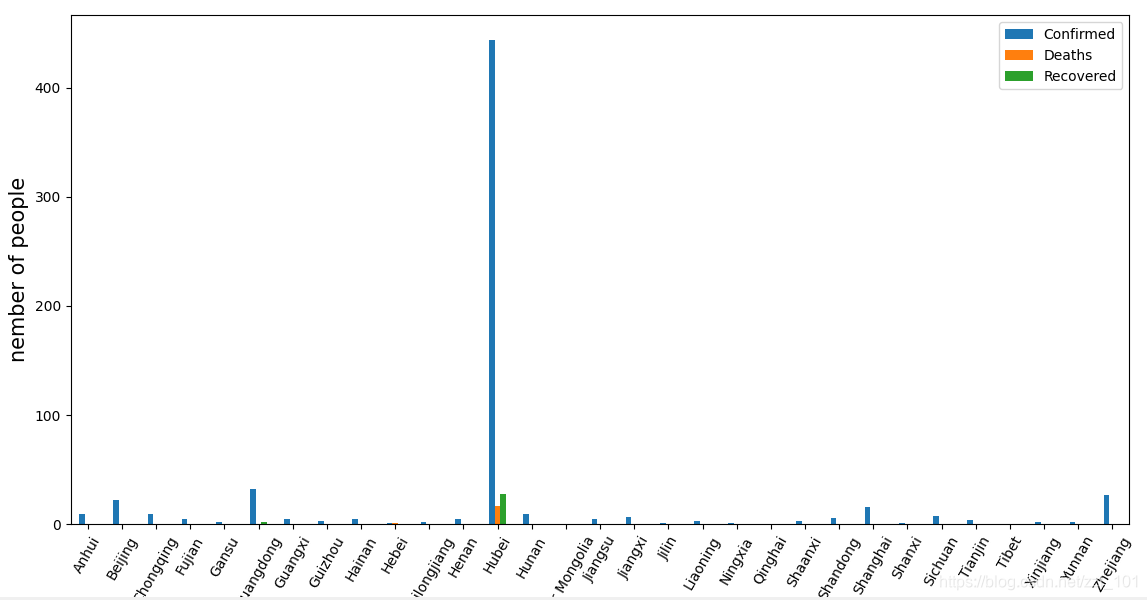
用同样方法取出2020 02 01日的数据

粗略可以看到柱状图没有明显变化,但看到纵坐标的人数,400和8000相差近20倍,说明病毒传的很迅速,急需预防,好在这时开始封锁,阻止了病毒的传播,由于还有潜伏期,还会快速增长十几天。
2.获取其中疫情最严重的省份的曲线图
接着上面写下列源代码,找到湖北省的数据,按照时间表示出疫情人数的折线图。
运行结果如下

可以看到确诊人数随着时间几乎成指数增长。对待这类疫情,我们应该少在外走动,不聚集活动,服从相关政策安排。
3.获取数据开始和总和的饼状图进行分析
先获取这段时间确诊人数总和,源代码如下:

运行结果为

再获取开始的数据

可以看到比例相差不大,其他城市病例较少,可能有点疏忽,占比变大了一点,总的来说防御措施还是相当不错的。
现在疫情似乎有卷土重来的迹象,现在大家还是安心待在家,尽量少走动,过个好年。