之前呢,我怕去了百度贴吧的一些图片,并且保存的下来,然后我想用相同的方法爬取淘女郎-美人库的内容,发现不管怎么编写正则表达式都获取不了“Elements”其中的图片链接,之后去网上一查发现,原来我需要爬取的内容都是经过浏览器解析过的JS的内容,所以之前一直用的request.urlopen()方法此时就不管作用了,需要调用PhantomJS来解析网页,然后将解析过的源码进行筛选,就可以了,话不多说,看代码
from selenium import webdriver
import re
from urllib import request
class heiheihei:
#初始化方法,url参数是等待爬取的网址
def __init__(self,url):
self.url=url
# 此方法用来获取页面内 (JS解析之后的界面)
def getPage(self):
#调用PhantomJS解析器解析网页
driver = webdriver.PhantomJS(executable_path=r'C:\Users\liqifeng\AppData\Local\Programs\Python\Python36\Scripts\phantomjs')
#获取网页内容
driver.get(self.url)
#返回网页源代码
data = driver.page_source
return data
#获取网页中每个女模特的名字
def getName(self):
#首先,创建一个list,用来存储名字
list=[]
#调用getPage()方法获得网页解析过的源代码
content=self.getPage()
#编写pattern
pattern=re.compile('<span class="name">(.*?)</span>',re.S)
#将网页内容放进去匹配,并返回所有结果
result=re.findall(pattern,content)
#挨个遍历并将内容添加到list中
for item in result:
list.append(item)
#返回list
return list
#获取网页中所有模特图片的链接
def getJpg(self):
list=[]
content=self.getPage()
pattern=re.compile('<div class="img"><img src="//(.*?)"></div>')
result = re.findall(pattern, content)
for item in result:
#再编写一个pattern,筛选链接
pattern2=re.compile('gtd.*',re.S)
result2=re.search(pattern2,item)
list.append(result2.group())
return list
#此方法用来保存图片
#url为图片链接
#filename为图片名
def saveJpg(self,url,filename):
#一次遍历url和filename
for (jpg,name) in zip(url,filename):
#完善网址
jpgurl='http://'+jpg
#打开网址
req=request.urlopen(jpgurl)
#获取图片资源
u=req.read()
#完善文件名
files='E:/jpg/'+name+'.jpg'
#打开文件
file=open(files,'wb')
with file as f:
#写入图片资源
f.write(u)
print('保存图片'+name+'.jpg'+'成功')
#新建一个实例,并传入网址
test=heiheihei('https://mm.taobao.com/search_tstar_model.htm?spm=5679.126488.640745.2.b17c0adHu3H5A')
#获取姓名
lalala=test.getName()
#获取图片
hahaha=test.getJpg()
#保存图片
test.saveJpg(hahaha,lalala)
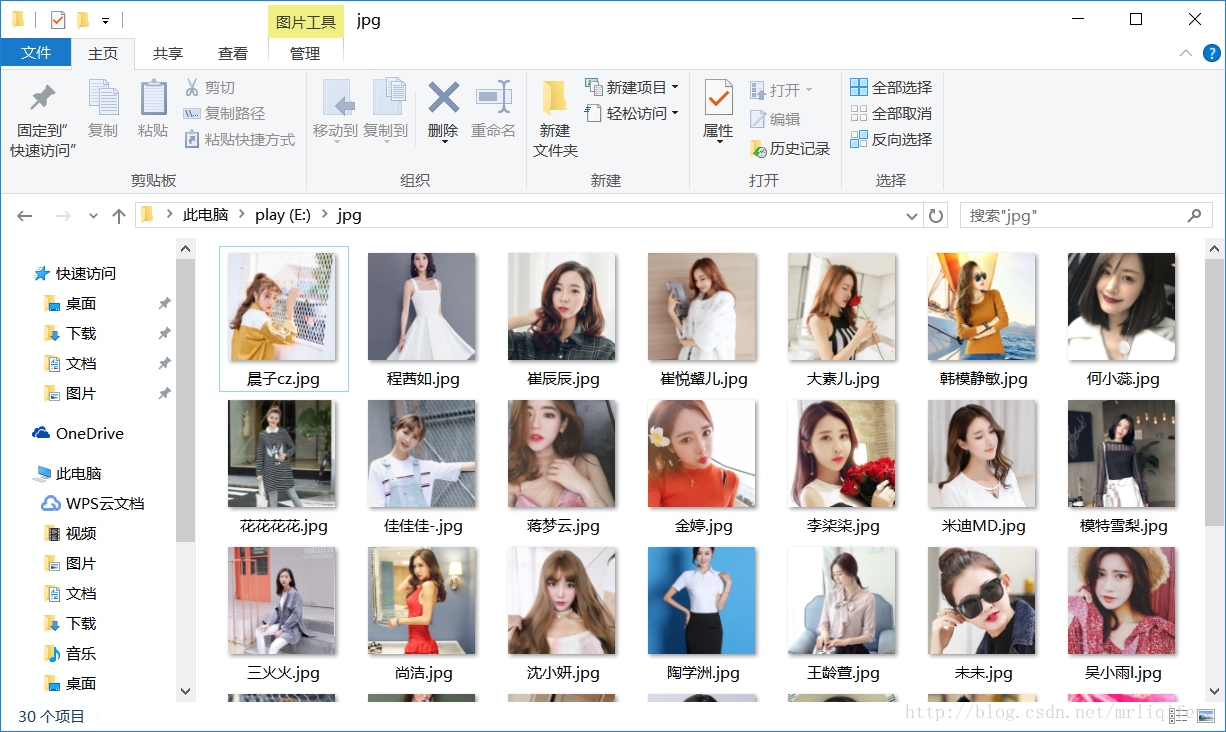
以上为程序运行的结果