遗传算法求解优化问题
目录
1.遗传算法的解读
1.1参数编码
1.1.1二进制编码
1.1.2十进制编码
1.2初始化群体的设定
1.3适应度函数的设定
1.4遗传操作设计
1.4.1选择
1.4.2交叉
1.4.3变异
1.5控制参数设定
2.遗传算法的验证
2.1参数编码
2.2初始化群体的设定
2.3适应度函数的设定
2.4遗传操作设计
2.4.1选择
2.4.2交叉
2.4.3变异
2.5控制参数设定
3.遗传算法的参数解读
3.1初始参数运行结果:
3.2种群内个体数目(N) 对结果的影响 9
3.2.1 N = 20
3.2.2 N = 60
3.2.3 N = 200
3.2.4 N = 500
3.2.5总结
3.3迭代次数(iter)对结果的影响
3.3.1 iter = 3
3.3.2 iter = 7
3.3.3 iter = 50
3.3.4 iter = 1000
3.3.5总结
3.4突变概率(mut) 对结果的影响
3.4.1 mut = 0.05
3.4.2 mut = 0.1
3.4.3 mut = 0.3
3.4.4 mut = 0.4
3.4.5总结
3.5交叉概率(arc) 对结果的影响
3.5.1 arc = 0.05
3.5.2 arc = 0.1
3.5.3 arc = 0.3
3.5.4 arc = 0.4
3.5.5总结
3.6优参数带入的的结果
4遗传算法的程序源码
4.1 主函数
4.2 Initialize函数(对每个个体的染色体进行随机赋值)
4.3 CalFitness函数(计算适应度函数)
4.4 FindBest函数(寻找出当前种群中的最优染色体,并将其保存在chrom_best)
4.5 CalAveFitness函数(计算当前种群中的平均适应度)
4.6 MutChrom函数(对种群进行染色体变异操作)
4.7 IfOut函数(判定突变值是否越界)
4.8 AcrChrom函数(染色体交叉函数)
4.9 ReplaceWorse函数(将种群中的最劣染色体用最优的染色体给替换掉)
4.10 PlotModel函数(给最优解作图)
4.11 PlotModel2函数(给所有的解作图)
1.遗传算法的解读
遗传算法可包含以下五个基本要素
1.1参数编码
参数编码可分为二进制编码和十进制编码
1.1.1二进制编码
染色体上的基因都是以0,1的形式保存的。
优点:
类似生物染色体的组成,算法易于用生物遗传理论解释,遗传操作如交叉、变异等易于 实现;算法处理的模式数最多。
缺点:
求解高维优化问题的二进制编码串长,搜索效率低。
1.1.2十进制编码
染色体上的基因是以0,1,2,3,4,5,6,7,8,9的形式保存的。
优点:
采用实数表达法不必进行数制转换,可直接在解的表现型上进行遗传操作;用于求解高维或者复杂的优化问题。
1.2初始化群体的设定
随机产生一些个体
1.3适应度函数的设定
若目标函数f(x)为最大化(求最大值)问题,那么适应度函数取为
F(f(x))= f(x)
若目标函数f(x)为最小化(求最小值)问题,那么适应度函数取为
F(f(x))= 1/f(x)
1.4遗传操作设计
1.4.1选择
1.4.1.1个体选择概率分配方法
适应度比例方法(蒙特卡罗算法)
选择适应度高的
排序方法
先按适应度排序,之后再选择
1.4.1.2选择个体方法
轮盘赌选择
最佳个体保存方法
将最优的保留,不做交叉,直接复制到下一代
1.4.2交叉
1.4.2.1一点交叉
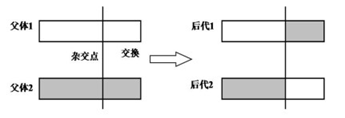
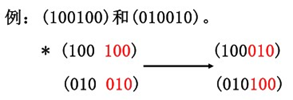
1.4.2.2二点交叉
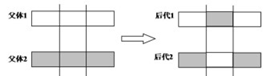

1.4.3变异
1.4.3.1位点变异
1.4.3.2逆转变异
1.4.3.3插入变异
1.5控制参数设定
种群内个体数目
一条染色体上的基因数
迭代次数
突变概率
交叉概率
2.遗传算法的验证
我将我对掌握程度,并用求测试函数二维Sphere函数(f(x,y) = xx +yy[-100,100])的最小值来验证。
2.1参数编码
由于考虑到有两个自变量且自变量的定义域比较大,于是采用十进制编码,且精度为0.01。那么我们相当于用[-99.99,99,99]去替换了原来的[-100,100],且每个变量由4个来表达,一条染色体含有8个基因。
变量x = 基因110 + 基因2 + 基因3/10 + 基因4/100
变量y = 基因510 + 基因6 + 基因7/10 + 基因8/100
基因1和基因5取值范围都是[-9,9],其他基因都为[0,9]

2.2初始化群体的设定
为了更好的找到测试函数Sphere的最小值,我们初始选取了100个染色体。
2.3适应度函数的设定
由于我们是找Sphere函数的最小值,那么适应度函数取为
F(f(x,y))= 1/f(x,y)
2.4遗传操作设计
2.4.1选择
2.4.1.1个体选择概率分配方法
采用适应度比例方法(蒙特卡罗算法)选择适应度高的。
2.4.1.2选择个体方法
采用最佳个体保存方法,将最优的保留,不做交叉,直接复制到下一代。
2.4.2交叉
采用一点交叉。
2.4.3变异
采用位点变异。
2.5控制参数设定
种群内个体数目:N = 100。
迭代次数:iter = 10。
突变概率:mut = 0.2。
交叉概率:arc = 0.2。
3.遗传算法的参数解读
3.1初始参数运行结果:
种群内个体数目:N = 100。
一条染色体上的基因数:N_chrom = 8。
迭代次数:iter = 10。
突变概率:mut = 0.2。
交叉概率:arc = 0.2。

图3.1.1平均适应度与最优适应度曲线

图3.1.2 最优点坐标

图3.1.3 最优点坐标和最优解

3.2种群内个体数目(N) 对结果的影响
由于我们之前设定的是个体数目N = 100。为了更好的观察出个体数目(N)对结果的影响,且要避免偶然性。则我们以N = 100为分界,分别在此左右各取两个不同的值,其它参数不变。
3.2.1 N = 20

图3.2.1.1平均适应度与最优适应度曲线

图3.2.1.2最优点坐标

图3.2.1.3 最优点坐标和最优解

3.2.2 N = 60

图3.2.2.1平均适应度与最优适应度曲线

图3.2.2.2最优点坐标

图3.2.2.3 最优点坐标和最优解

3.2.3 N = 200

图3.2.3.1 平均适应度与最优适应度曲线

图3.2.3.2 最优点坐标

图3.2.3.3 最优点坐标和最优解

3.2.4 N = 500

图3.2.4.1 平均适应度与最优适应度曲线

图3.2.4.2 最优点坐标

图3.2.4.3 最优点坐标和最优解

3.2.5总结
通过以上的实验,我们可以发现,当N越大,最优适应度越大,算出来的结果也越接近已知的最优解。
3.3迭代次数(iter)对结果的影响
由于我们之前设定的是迭代次数iter = 10。为了更好的观察出迭代次数(iter)对结果的影响,且要避免偶然性。则我们以iter = 10为分界,分别在此左右各取两个不同的值,其它参数不变。
3.3.1 iter = 3

图3.3.1.1 平均适应度与最优适应度曲线

图3.3.1.2 最优点坐标

图3.3.1.3 最优点坐标和最优解

3.3.2 iter = 7

图3.3.2.1 平均适应度与最优适应度曲线

图3.3.2.2 最优点坐标

图3.3.2.3 最优点坐标和最优解

3.3.3 iter = 50

图3.3.3.1 平均适应度与最优适应度曲线

图3.3.3.2 最优点坐标

图3.3.3.3 最优点坐标和最优解

3.3.4 iter = 1000

图3.3.4.1 平均适应度与最优适应度曲线

图3.3.4.2 最优点坐标

图3.3.4.3 最优点坐标和最优解

3.3.5总结
当迭代次数过小时,算出来的最优适应度变化很随机。但从宏观来看,随着迭代次数的增多,最优适应度也会增大,越靠近最优解,当达到一定值时,即可找到最优解。
3.4突变概率(mut) 对结果的影响
由于我们之前设定的是突变概率mut = 0.2。为了更好的观察出突变概率(mut)对结果的影响,且要避免偶然性。则我们以为mut = 0.2分界,分别在此左右各取两个不同的值,其它参数不变。
3.4.1 mut = 0.05

图3.4.1.1 平均适应度与最优适应度曲线

图3.4.1.2 最优点坐标

图3.4.1.3 最优点坐标和最优解

3.4.2 mut = 0.1

图3.4.2.1 平均适应度与最优适应度曲线

图3.4.2.2 最优点坐标

图3.4.2.3 最优点坐标和最优解

3.4.3 mut = 0.3

图3.4.3.1 平均适应度与最优适应度曲线

图3.4.3.2 最优点坐标

图3.4.3.3 最优点坐标和最优解

3.4.4 mut = 0.4

图3.4.4.1 平均适应度与最优适应度曲线

图3.4.4.2 最优点坐标

图3.4.4.3 最优点坐标和最优解

3.4.5总结
我通过以上的一些数据测试,我发现在其它参数固定不变,且这种情况下,突变概率设置成mut = 0.05的时候,适应度是这些测试的数据中最大的,但是当其它的参数变化的时候,最优的突变概率也会变,则在解决实际问题当中,我们应该要多测试最优突变概率为多少。且突变概率最高,结果往往越不会陷入局部最优解中。
3.5交叉概率(arc) 对结果的影响
由于我们之前设定的是突变概率arc=0.2。为了更好的观察出突变概率(arc)对结果的影响,且要避免偶然性。则我们以arc = 0.2为分界,分别在此左右各取两个不同的值,其它参数不变。
3.5.1 arc = 0.05

图3.5.1.1 平均适应度与最优适应度曲线

图3.5.1.2 最优点坐标

图3.5.1.3 最优点坐标和最优解

3.5.2 arc = 0.1

图3.5.2.1 平均适应度与最优适应度曲线

图3.5.2.2 最优点坐标

图3.5.2.3 最优点坐标和最优解

3.5.3 arc = 0.3

图3.5.3.1 平均适应度与最优适应度曲线

图3.5.3.2 最优点坐标

图3.5.3.3 最优点坐标和最优解

3.5.4 arc = 0.4

图3.5.4.1 平均适应度与最优适应度曲线

图3.5.4.2 最优点坐标

图3.5.4.3 最优点坐标和最优解

3.5.5总结
我通过以上的一些数据测试,我发现在其它参数固定不变,且这种情况下,交叉概率设置成arc= 0.1的时候,适应度是这些测试的数据中最大的,通过对适应度的观察,我发现交叉概率是在一个点会达到峰值,总体趋势是随着交叉概率的递增,结果出现先增后减。
3.6优参数带入的的结果
通过上面的分析,我们选出了一组优的参数。种群数目N = 500;迭代次数iter=200;突变概率mut = 0,05;交叉概率arc=0.1。

图3.6.1 平均适应度与最优适应度曲线

图3.6.2 最优点坐标

图3.6.3 最优点坐标和最优解

4遗传算法的程序源码(MATLAB)
4.1 主函数
%%
%函数说明: 本函数是对二维的Sphere测试函数(即f(x,y) = x*x +y*y[-100,100])进行求最小值的(x,y)
% 由于有两个变量,我们将x,y变量进行实数编码,精度为0.01。那么我们
% 相当于用[-99.99,99,99]去替换了原来的[-100,100],且每个变量由4个
% 来表达,一条染色体含有8个基因。
% 变量x = 基因1*10 + 基因2 + 基因3/10 + 基因4/100
% 变量y = 基因5*10 + 基因6 + 基因7/10 + 基因8/100
% 基因1和基因5取值范围都是[-9,9],其他基因都为[0,9]
% 本函数中选择的是一点交叉,变异选择的是位点变异。
%函数功能说明:利用遗传算法对最大最小问题求解
%
%求不同问题时候,需要修改的地方说明:
% 若该函数的自变量的基因个数发生变化,则需要修改
% 1.主函数中的染色体节点数N_chrom = 8; %染色体节点数
% 2.主函数中的各基因的取值范围chrom_range = [-9 0 0 0 -9 0 0 0;9 9 9 9 9 9 9 9];%每个节点的值的区间
% 3.主函数中的最优染色体中的变量组成和输出精度
% 我们先需要对chrom_best的取整
% disp(['最优染色体为', ])
% x = floor(chrom_best(1))*10 + floor(chrom_best(2))+
% floor(chrom_best(3))/10 + floor(chrom_best(4))/100;
% y = floor(chrom_best(5))*10 + floor(chrom_best(6)) +
% floor(chrom_best(7))/10 + floor(chrom_best(8))/100;
% %结果以两位小数输出
% fprintf('x = %6.2f ; y = %6.2f\n',x,y);
% 4.CalFitness 中的 (得根据实际的选择修改)
% x = chrom(i, 1)*10 + chrom(i, 2) + chrom(i, 3)/10 + chrom(i, 4)/100;
% y = chrom(i, 5)*10 + chrom(i, 6) + chrom(i, 7)/10 + chrom(i, 8)/100;
% fitness(i) = 1.0/(x*x + y*y); %找最小值用的,结果越小,适应度越高
% fitness(i) = x*x + y*y; %找最大值用的,结果越大,适应度越高
% 5. PlotModel中的关系式和显示范围
% 6. PlotModel2中的关系式和显示范围
%
%注意: chrom(i,N) 和chrom_best(i,N)里面存的都是对应的每个基因在该区间内的一些数值(带小数),
% 所需根据实际情况,按是否使用floor取整函数
%%
clc, clear, close all
%%基础参数
N = 100; %种群内个体数目100
N_chrom = 8; %一条染色体上的基因数8
iter = 10; %迭代次数10
mut = 0.2; %突变概率0.2
acr = 0.4; %交叉概率0.2
best = 1;
chrom_range = [-9 0 0 0 -9 0 0 0;9 9 9 9 9 9 9 9];%每个节点的值的区间
chrom = zeros(N, N_chrom);%存放染色体的矩阵
fitness = zeros(N, 1);%存放染色体的适应度
fitness_ave = zeros(1, iter);%存放每一代的平均适应度
fitness_best = zeros(1, iter);%存放每一代的最优适应度
chrom_best = zeros(1, N_chrom+1);%存放当前代的最优染色体与适应度
%%初始化
chrom = Initialize(N, N_chrom, chrom_range); %初始化染色体
fitness = CalFitness(chrom, N, N_chrom); %计算适应度
chrom_best = FindBest(chrom, fitness, N_chrom); %寻找最优染色体
fitness_best(1) = chrom_best(end); %将当前最优存入矩阵当中
fitness_ave(1) = CalAveFitness(fitness); %将当前平均适应度存入矩阵当中
for t = 2:iter
chrom = MutChrom(chrom, mut, N, N_chrom, chrom_range, t, iter); %变异
chrom = AcrChrom(chrom, acr, N, N_chrom); %交叉
fitness = CalFitness(chrom, N, N_chrom); %计算适应度
chrom_best_temp = FindBest(chrom, fitness, N_chrom); %寻找最优染色体
if chrom_best_temp(end)>chrom_best(end) %替换掉当前储存的最优
chrom_best = chrom_best_temp;
end
%%替换掉最劣
[chrom, fitness] = ReplaceWorse(chrom, chrom_best, fitness);
fitness_best(t) = chrom_best(end); %将当前最优存入矩阵当中
fitness_ave(t) = CalAveFitness(fitness); %将当前平均适应度存入矩阵当中
end
%%作图
figure(1)
plot(1:iter, fitness_ave, 'r', 1:iter, fitness_best, 'b')
grid on
legend('平均适应度', '最优适应度')
v = PlotModel2(chrom,N)
e = PlotModel(chrom_best)
%%输出结果
% disp(['最优染色体为', num2str(chrom_best(1:end-1))])
%计算x,y变量
%我们先需要对chrom_best的取整
disp(['最优染色体为', ])
x = floor(chrom_best(1))*10 + floor(chrom_best(2))+ floor(chrom_best(3))/10 + floor(chrom_best(4))/100;
y = floor(chrom_best(5))*10 + floor(chrom_best(6)) + floor(chrom_best(7))/10 + floor(chrom_best(8))/100;
%结果以两位小数输出
fprintf('x = %6.2f ; y = %6.2f\n',x,y);
disp(['最优适应度为', num2str(chrom_best(end))])
4.2 Initialize函数(对每个个体的染色体进行随机赋值)
function chrom_new = Initialize(N, N_chrom, chrom_range)
chrom_new = rand(N, N_chrom);
for i = 1:N_chrom %每一列乘上范围
chrom_new(:, i) = chrom_new(:, i)*(chrom_range(2, i)-chrom_range(1, i))+chrom_range(1, i);
end
4.3 CalFitness函数(计算适应度函数)
function fitness = CalFitness(chrom, N, N_chrom)
fitness = zeros(N, 1);
%开始计算适应度
for i = 1:N
% chrom(i, N)是单个基因的值,该值介于你设定的该基因取值范围内的一个浮点数。我们需要先对它取整
x = floor(chrom(i, 1))*10 + floor(chrom(i, 2)) + floor(chrom(i, 3))/10 + floor(chrom(i, 4))/100;
y = floor(chrom(i, 5))*10 + floor(chrom(i, 6)) + floor(chrom(i, 7))/10 + floor(chrom(i, 8))/100;
fitness(i) = 1.0/(x*x + y*y); %找最小值用的
% fitness(i) = x*x + y*y; %找最大值用的
end
4.4 FindBest函数(寻找出当前种群中的最优染色体,并将其保存在chrom_best)
function chrom_best = FindBest(chrom, fitness, N_chrom)
chrom_best = zeros(1, N_chrom+1);
[maxNum, maxCorr] = max(fitness);
chrom_best(1:N_chrom) =chrom(maxCorr, :);
chrom_best(end) = maxNum;
4.5 CalAveFitness函数(计算当前种群中的平均适应度)
function fitness_ave = CalAveFitness(fitness)
[N ,~] = size(fitness);
fitness_ave = sum(fitness)/N;
4.6 MutChrom函数(对种群进行染色体变异操作)
function chrom_new = MutChrom(chrom, mut, N, N_chrom, chrom_range, t, iter)
for i = 1:N
for j = 1:N_chrom
mut_rand = rand; %是否变异
if mut_rand <=mut
mut_pm = rand; %增加还是减少
mut_num = rand*(1-t/iter)^2;
if mut_pm<=0.5
chrom(i, j)= chrom(i, j)*(1-mut_num);
else
chrom(i, j)= chrom(i, j)*(1+mut_num);
end
chrom(i, j) = IfOut(chrom(i, j), chrom_range(:, j)); %检验是否越界
end
end
end
chrom_new = chrom;
4.7 IfOut函数(判定突变值是否越界)
function c_new = IfOut(c, range)
if c<range(1) || c>range(2)
if abs(c-range(1))<abs(c-range(2))
c_new = range(1);
else
c_new = range(2);
end
else
c_new = c;
end
4.8 AcrChrom函数(染色体交叉函数)
function chrom_new = AcrChrom(chrom, acr, N, N_chrom)
for i = 1:N
acr_rand = rand;
if acr_rand<acr %如果交叉
acr_chrom = floor((N-1)*rand+1); %要交叉的染色体
acr_node = floor((N_chrom-1)*rand+1); %要交叉的节点
%交叉开始
for m = acr_node:N_chrom
temp = chrom(i, m);
chrom(i, m) = chrom(acr_chrom, m);
chrom(acr_chrom, m) = temp;
end
end
end
chrom_new = chrom;
4.9 ReplaceWorse函数(将种群中的最劣染色体用最优的染色体给替换掉)
function [chrom_new, fitness_new] = ReplaceWorse(chrom, chrom_best, fitness)
max_num = max(fitness);
min_num = min(fitness);
limit = (max_num-min_num)*0.2+min_num;
replace_corr = fitness<limit;
replace_num = sum(replace_corr);
chrom(replace_corr, :) = ones(replace_num, 1)*chrom_best(1:end-1);
fitness(replace_corr) = ones(replace_num, 1)*chrom_best(end);
chrom_new = chrom;
fitness_new = fitness;
end
4.10 PlotModel函数(给最优解作图)
function y = PlotModel(chrom)
x = floor(chrom(1))*10 + floor(chrom(2)) + floor(chrom(3))/10 + floor(chrom(4))/100;
y = floor(chrom(5))*10 + floor(chrom(6)) + floor(chrom(7))/10 + floor(chrom(8))/100;
z = x*x+y*y;
figure(2)
subplot(1,2,1); %将界面分成左右两部分
plot(x,y,'rp','MarkerSize',15) % MarkerSize 表示点的大小,b.表示绿色的点
xlabel('x'); %横坐标栏
ylabel('y'); %纵坐标栏
axis([-100,100,-100,100]);
hold on
%非设定固定的x,y,z区间,以便于更好的观察
subplot(1,2,2); %将界面分成左右两部分
plot(x,y,'rp','MarkerSize',15) % MarkerSize 表示点的大小,b.表示绿色的点
xlabel('x'); %横坐标栏
ylabel('y'); %纵坐标栏
hold on
figure(3)
plot3(x,y,z,'rp','MarkerSize',5) % MarkerSize 表示点的大小,b.表示绿色的点。
xlabel('x'); %横坐标栏
ylabel('y'); %纵坐标栏
zlabel('f(x,y)'); %f(x,y)
axis([-100,100,-100,100,0,20000]);
hold on
[X, Y] = meshgrid(-100:0.1:100);
Z = X.*X + Y.*Y;
mesh(X, Y, Z)
axis([-100,100,-100,100,0,20000]);
y=1;
4.11 PlotModel2函数(给所有的解作图)
function y = PlotModel2(chrom,N)
for i = 1:N
x = floor(chrom(i,1))*10 + floor(chrom(i,2)) + floor(chrom(i,3))/10 + floor(chrom(i,4)/100);
y = floor(chrom(i,5))*10 + floor(chrom(i,6)) + floor(chrom(i,7))/10 + floor(chrom(i,8)/100);
z = x*x+y*y;
figure(2)
subplot(1,2,1); %将界面分成左右两部分
plot(x,y,'bo','MarkerSize',5) % MarkerSize 表示点的大小,b.表示绿色的点。
xlabel('x'); %横坐标栏
ylabel('y'); %纵坐标栏
hold on
%非设定固定的x,y,z区间,以便于更好的观察
subplot(1,2,2); %将界面分成
plot(x,y,'bo','MarkerSize',5)
xlabel('x'); %横坐标栏
ylabel('y'); %纵坐标栏
hold on
figure(3)
plot3(x,y,z,'bo','MarkerSize',5) % MarkerSize 表示点的大小,b.表示绿色的点。
xlabel('x'); %横坐标栏
ylabel('y'); %纵坐标栏
zlabel('f(x,y)'); %f(x,y)
axis([-100,100,-100,100,0,20000]);
hold on
end
y=1;