- 问题描述
编程实现遗传算法,解决五个多峰函数优化问题。五个函数分别如下:
![]()
![]()
![]()
![]()
![]()
他们在(0,1)区间内的分布如下:

求各个函数在(0,1)区间的极小值。
- 遗传算法基本原理
遗传算法(genetic algorithm(GA))是计算数学中用于解决最优化的搜索算法,是进化算法的一种。由遗传算法由密歇根大学的约翰·霍兰德和他的同事于二十世纪六十年代在对细胞自动机(英文:cellular automata)进行研究时率先提出。在二十世纪八十年代中期之前,对于遗传算法的研究还仅仅限于理论方面,直到在匹兹堡召开了第一届世界遗传算法大会。随着计算机计算能力的发展和实际应用需求的增多,遗传算法逐渐进入实际应用阶段。1989年,纽约时报作者约翰·马科夫写了一篇文章描述第一个商业用途的遗传算法--进化者(英文:Evolver)。之后,越来越多种类的遗传算法出现并被用于许多领域中,财富杂志500强企业中大多数都用它进行时间表安排、数据分析、未来趋势预测、预算、以及解决很多其他组合优化问题。

遗传算法GA把问题的解表示为“染色体”,也称为个体,在算法中即是以一定方式编码的串。并且,在执行遗传算法之前,会先初始化一个种群,这个种群包含若干个个体。然后,把这些个体置于问题的“环境”中,并按适者生存的原则,从中选择出较适应环境的个体(即适应度值高的个体)进行复制,再通过一定的概率进行交叉和变异操作产生更适应环境的新一代种群。这样,一代一代地进化,最后就会收敛到最适应环境的一个“染色体”上,他就是问题的最优解。
遗传算法的流程:
(1)确定编码方式:
二进制编码方式:这是GA中最常用的一种编码方式,受到人类染色体结构的启发,我们可以设想一下,假设目前只有“0”,“1”两种碱基,我们也用一条链条把他们有序的串连在一起,因为每一个单位都能表现出 1 bit的信息量,所以一条足够长的染色体就能为我们勾勒出一个个体的所有特征。这就是二进制编码法。染色体大致如下:
010010011011011110111110
二进制编码的串的长度与问题所要求的求解精度有关。设某一参数的取值范围为[A,B],A<B。则二进制编码的编码精度为:
,l 为编码长度
(2)初始化种群:在确定了编码方式后,我们需要先根据种群大小用相应的编码方式进行初始化种群。
(3)解码:对个体进行编码后肯定要经过解码后才能对其进行后续操作。这里仅介绍二进制编码方式的解码方式。假设某一变量的编码串为: ,则对应的解码公式为:
, l 为编码长度
(4)计算适应度值:
计算适应度值需要定义评估函数。评估函数常常根据问题的优化目标来确定,比如在求解函数优化问题时,问题定义的目标函数可以作为评估函数的原型。在遗传算法中,规定适应值越大的染色体越优。因此对于一些求解最大值的数值优化问题,我们可以直接套用问题定义的函数表达式。但是对于其他优化问题,问题定义的目标函数表达式必须经过一定的变换。
(5)选择:
在计算出每个个体的适应度值,以适者生存的原理选择种群中适应度值高的个体进行复制,淘汰掉适应度值低的个体。选择的方法有以下几种:
轮盘赌法:对于最大化问题,适应度比例可以描述为:
K-精英法:最好的K个个体被保留并传给下一代。
(6)交叉:交叉是以一定的概率选择若干个个体进行交叉重组。对于选中用于繁殖下一代的个体,随机地选择两个个体的相同位置,按交叉概率Pc在选中的位置实行交换。
(7)变异:染色体的变异作用于基因之上,对于交配后新种群中染色体的每一位基因,根据变异概率Pm判断该基因是否进行变异。如果Random(0, 1)小于Pm,则改变该基因的取值(其中Random(0, 1)为[0, 1]间均匀分布的随机数)。否则该基因不发生变异,保持不变。
遗传算法的流程图:
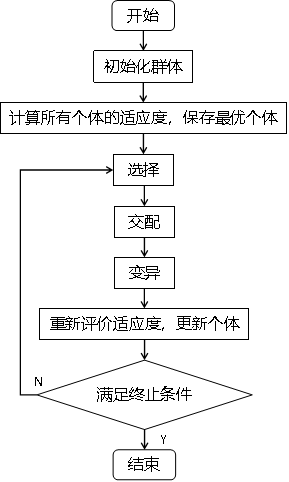
- 实验结果
|
|
|
| 极小值点为X: 0.7746610641479492 |
极小值为Y: -1.5122447570448196 |
| 极小值点为X: 0.7746696472167969 |
极小值为Y: -1.5122448106165713 |
| 极小值点为X: 0.7746686935424805 |
极小值为Y: -1.512244816229735 |
| 极小值点为X: 0.7746715545654297 |
极小值为Y: -1.5122447907159078 |
|
|
|
| 极小值点为X: 0.873723030090332 |
极小值为Y: -0.5786606258610059 |
| 极小值点为X: 0.8737049102783203 |
极小值为Y: -0.5786606993977528 |
| 极小值点为X: 0.8737163543701172 |
极小值为Y: -0.5786606647759943 |
| 极小值点为X: 0.8737010955810547 |
极小值为Y: -0.5786607019309087 |
|
|
|
| 极小值点为X: 0.7126836776733398 |
极小值为Y: -0.0660952026879191 |
| 极小值点为X: 0.7126846313476562 |
极小值为Y: -0.06609520269132968 |
| 极小值点为X: 0.7126855850219727 |
极小值为Y: -0.06609520266910421 |
| 极小值点为X: 0.7126846313476562 |
极小值为Y: -0.06609520269132968 |
|
|
|
| 极小值点为X: 0.108917236328125 |
极小值为Y: -2.8837720003022644 |
| 极小值点为X: 0.10891151428222656 |
极小值为Y: -2.883772017851351 |
| 极小值点为X: 0.10891151428222656 |
极小值为Y: -2.883772017851351 |
| 极小值点为X: 0.10888481140136719 |
极小值为Y: -2.8837712966161577 |
|
|
|
| 极小值点为X: 0.5192775726318359 |
极小值为Y: -2.288889004243957 |
| 极小值点为X: 0.5192909240722656 |
极小值为Y: -2.288888792676238 |
| 极小值点为X: 0.519291877746582 |
极小值为Y: -2.2888887428720013 |
| 极小值点为X: 0.5193109512329102 |
极小值为Y: -2.2888867753893867 |
以上表格表示每个函数运行四次分别输出的结果。

由图可得知,求的的结果均为全局极小值点。
- 代码展示
# -*-coding:utf-8 -*-
import random
import math
import matplotlib.pyplot as plt
import myfunction
class GA(object):
# 初始化种群 生成chromosome_length大小的population_size个个体的种群
def __init__(self, population_size, chromosome_length, max_value, pc, pm, epoch, funn):
self.population_size = population_size
self.choromosome_length = chromosome_length
self.max_value = max_value
self.pc = pc
self.pm = pm
self.epoch = epoch
self.funn = funn
def species_origin(self):
population = [[]]
for i in range(self.population_size):
temporary = []
# 染色体暂存器
for j in range(self.choromosome_length):
temporary.append(random.randint(0, 1))
# 随机产生一个染色体,由二进制数组成
population.append(temporary)
# 将染色体添加到种群中
return population[1:]
# 将种群返回,种群是个二维数组,个体和染色体两维
# 从二进制到十进制
# 编码 input:种群,染色体长度 编码过程就是将多元函数转化成一元函数的过程
def translation(self, population):
temporary = []
for i in range(len(population)):
total = 0
for j in range(self.choromosome_length):
total += population[i][j] * (math.pow(2, -1-j))
# 从第一个基因开始,每位对1/2求幂,再求和
# 如:0101 转成十进制为:0 * 1/2 + 1 * 1/4 + 0 * 1/8 + 1 * 1/16 = 0 + 1/4 + 0 + 1/16 = 0.3125
temporary.append(total)
# 一个染色体编码完成,由一个二进制数编码为一个十进制数
return temporary
# 返回种群中所有个体编码完成后的十进制数
# from protein to function,according to its functoin value
# a protein realize its function according its structure
# 目标函数相当于环境 对染色体进行筛选
def function(self, population):
a = [myfunction.fun1, myfunction.fun2, myfunction.fun3, myfunction.fun4, myfunction.fun5]
temporary = []
function1 = []
temporary = self.translation(population)
for i in range(len(temporary)):
# x = temporary[i] * self.max_value / (math.pow(2, self.choromosome_length) - 10)
function1.append((-1)*a[self.funn-1](temporary[i]))
return function1
# 定义适应度
def fitness(self, function1):
fitness_value = []
num = len(function1)
for i in range(num):
if (function1[i] > 0):
temporary = function1[i]
else:
temporary = 0.0
# 如果适应度小于0,则定为0
fitness_value.append(temporary)
# 将适应度添加到列表中
return fitness_value
# 计算适应度和
def sum(self, fitness_value):
total = 0
for i in range(len(fitness_value)):
total += fitness_value[i]
return total
# 计算适应度斐伯纳且列表
def cumsum(self, fitness1):
for i in range(len(fitness1) - 2, -1, -1):
# range(start,stop,[step])
# 倒计数
total = 0
j = 0
while (j <= i):
total += fitness1[j]
j += 1
fitness1[i] = total
fitness1[len(fitness1) - 1] = 1
# 3.选择种群中个体适应度最大的个体
def selection(self, population, fitness_value):
new_fitness = []
# 单个公式暂存器
total_fitness = self.sum(fitness_value)
# 将所有的适应度求和
for i in range(len(fitness_value)):
new_fitness.append(fitness_value[i] / total_fitness)
# 将所有个体的适应度正则化
self.cumsum(new_fitness)
#
ms = []
# 存活的种群
population_length = len(population)
# 求出种群长度
# 根据随机数确定哪几个能存活
for i in range(population_length):
ms.append(random.random())
# 产生种群个数的随机值
# ms.sort()
# 存活的种群排序
fitin = 0
newin = 0
new_population = []
# 轮盘赌方式
while newin < population_length:
if (ms[newin] < new_fitness[fitin]):
new_population.append(population[fitin])
# print(fitin)
newin += 1
else:
fitin += 1
return new_population
# 4.交叉操作
def crossover(self, population):
# pc是概率阈值,选择单点交叉还是多点交叉,生成新的交叉个体,这里没用
pop_len = len(population)
for i in range(pop_len - 1):
if (random.random() < self.pc):
cpoint = random.randint(0, len(population[0]))
# 在种群个数内随机生成单点交叉点
temporary1 = []
temporary2 = []
temporary1.extend(population[i][0:cpoint])
temporary1.extend(population[i+ 1][cpoint:len(population[i])])
# 将tmporary1作为暂存器,暂时存放第i个染色体中的前0到cpoint个基因,
# 然后再把第i+1个染色体中的后cpoint到第i个染色体中的基因个数,补充到temporary2后面
temporary2.extend(population[i + 1][0:cpoint])
temporary2.extend(population[i][cpoint:len(population[i])])
# 将tmporary2作为暂存器,暂时存放第i+1个染色体中的前0到cpoint个基因,
# 然后再把第i个染色体中的后cpoint到第i个染色体中的基因个数,补充到temporary2后面
population[i] = temporary1
population[i + 1] = temporary2
# 第i个染色体和第i+1个染色体基因重组/交叉完成
return population
def mutation(self, population):
# pm是概率阈值
px = len(population)
# 求出种群中所有种群/个体的个数
py = len(population[0])
# 染色体/个体基因的个数
for i in range(px):
for j in range(py):
if (random.random() < self.pm):
# 对每一个基因按概率变异
population[i][j] = 1 - population[i][j]
return population
# transform the binary to decimalism
# 将每一个染色体都转化成十进制 max_value,再筛去过大的值
def b2d(self, best_individual):
total = 0
b = len(best_individual)
for i in range(b):
total = total + best_individual[i] * math.pow(2, -1-i)
# total = total * self.max_value / (math.pow(2, self.choromosome_length)-1)
return total
# 寻找最好的适应度和个体
def best(self, population, fitness_value):
px = len(population)
bestindividual = []
bestfitness = fitness_value[0]
# print(fitness_value)
for i in range(1, px):
# 循环找出最大的适应度,适应度最大的也就是最好的个体
if (fitness_value[i] > bestfitness):
bestfitness = fitness_value[i]
bestindividual = population[i]
return [bestindividual, bestfitness]
def plot(self, results):
X = []
Y = []
for i in range(self.epoch):
X.append(i)
Y.append(results[i][0])
plt.plot(X, Y)
plt.show()
def main(self):
results = [[]]
population = self.species_origin()
best_fitness_inall = 0
best_individual_inall = 0
for i in range(self.epoch):
function_value = self.function(population)
# print('fit funtion_value:',function_value)
fitness_value = self.fitness(function_value)
# print('fitness_value:',fitness_value)
best_individual, best_fitness = self.best(population, fitness_value)
# print(best_fitness)
if best_fitness > best_fitness_inall:
best_fitness_inall = best_fitness
best_individual_inall = self.b2d(best_individual)
# print(best_individual_inall, best_fitness_inall)
results.append([best_fitness, self.b2d(best_individual)])
# 将最好的个体和最好的适应度保存,并将最好的个体转成十进制,适应度函数
population = self.selection(population, fitness_value)
population = self.crossover(population)
population = self.mutation(population)
# print("Length of Population: ", len(population))
results = results[1:]
print("最终结果: ", best_individual_inall, (-1)*best_fitness_inall)
# results.sort()
# self.plot(results)
# results.sort()
# self.plot(results)
if __name__ == '__main__':
population_size = 400
max_value = 1
chromosome_length = 20
pc = 0.6
pm = 0.01
epoch = 2000
for k in range(1, 6):
for _ in range(4):
ga = GA(population_size, chromosome_length, max_value, pc, pm, epoch,k)
ga.main()