本人比较喜欢收集壁纸,发现彼岸桌面壁纸唯美分类下的壁纸,我都很喜欢;于是写了个爬虫,后来发现整个网站的网页结构基本一致,于是加了点代码,把整个网页的高清壁纸都爬下来了
文章目录
目录一:概览
在电脑上,创建一个文件夹用来存放爬取彼岸桌面的图片
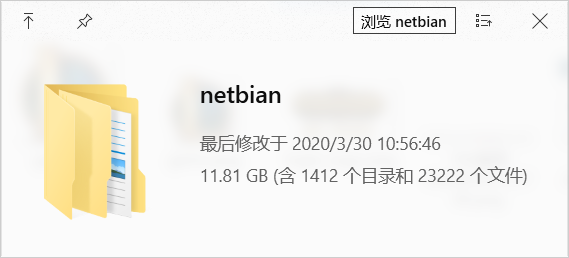
此文件夹下有25个文件夹,对应分类
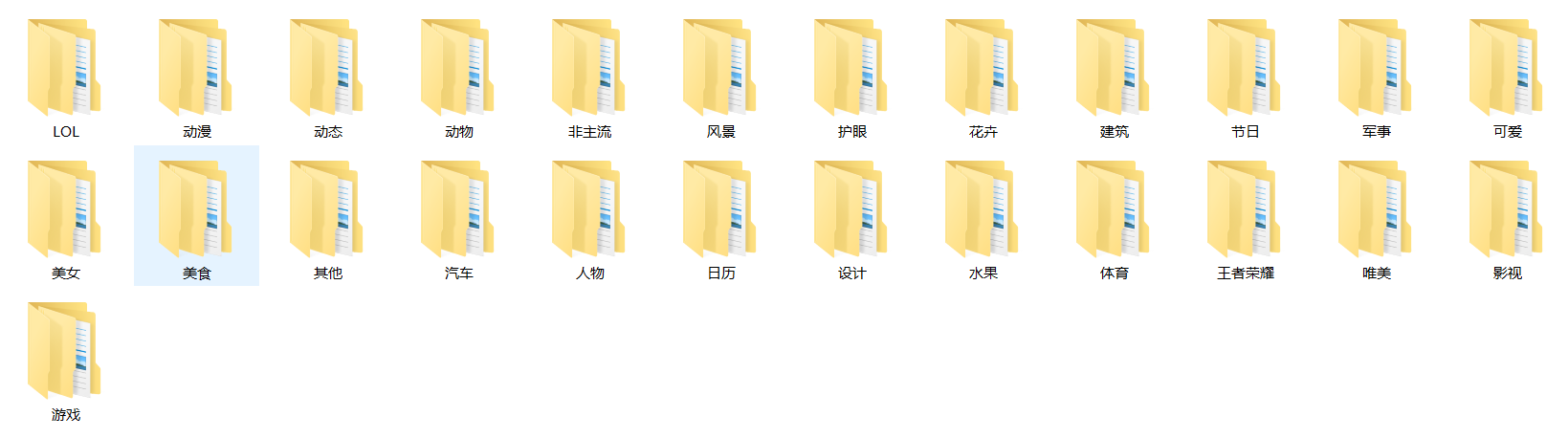
每个分类文件夹下有若干个文件夹,对应页码

页码文件夹下,存放图片文件
目录二:环境准备
还需要使用三个第三方包(有兴致的可以看看官方文档)
- requests:通过http请求获取页面,官方文档
- lxml:是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高,官方文档
- Beautiful Soup4:可以从HTML或XML文件中提取数据,官方文档
在终端中分别输入以下pip命令,安装它们
python -m pip install beautifulsoup4
python -m pip install lxml
python -m pip install requests
目录三:分析页面结构
- 因为我的电脑的分辨率为1920 × 1080,所以我爬取的图片的分辨率为此
- 彼岸桌面壁纸提供了许多分类供我们浏览:日历、动漫、风景、美女、游戏、影视、动态、唯美、设计…
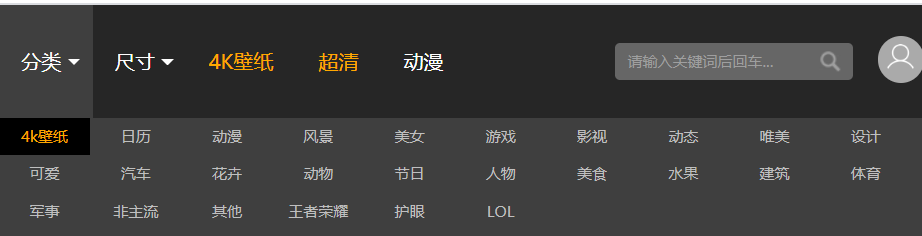
4k分类下的壁纸是该网站收益的重要资源,而且我没有4k壁纸的需求,对其不进行爬取

CSS选择器:#header > div.head > ul > li:nth-child(1) > div > a,定位到包裹分类的a标签
我以唯美分类下的壁纸,来讲解接下来怎么爬取图片

- 总共有73页,除了最后一页,每页有18张图片

但是在代码中我们最好需要自动获取总页码,嗯,彼岸桌面壁纸网站的结构是真的舒服,基本上每个页码的HTML结构都是类似的
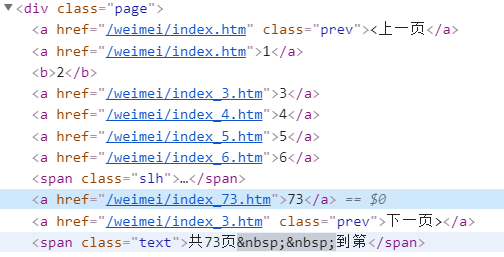
CSS选择器:div.page a,定位到包裹页码数的a标签,只有6个 - 并且每页的第三张图片都是一样的广告,需要在代码中把它过滤掉
- 每个分页的超链接很清晰:http://www.netbian.com/weimei/index_x.htm
x 恰好为该页的页码 - 注意:在分类下看到的图片是略缩图,分辨率都较低;要得到1920 × 1080分辨率的该图,需要进行两次跳转
以下图为例

在分类页面中我们可以直接获取该图片的url,但很可惜,它的分辨率并不令人满意;
通过检查,很明显的看到,在分类页中展示的每一个图片都指向另一个超链接

CSS选择器:div#main div.list ul li a,定位到包裹图片的a标签
点击该图片,第一次跳转,转到新的链接,页面中显示有下列内容:

CSS选择器:div#main div.endpage div.pic div.pic-down a,定位到包裹图片的a标签
点击下载壁纸(1920 × 1080)的按钮,第二次跳转,转向一个新的链接,终于达成目的,该链接中显示的图片的分辨率为 1920 × 1080
一波三折,终于给我找到了该图片的1920 × 1080高清图

CSS选择器:div#main table a img,定位到该图片的img标签
经过本人爬取检验,其中有极个别图片由于很多零碎的问题而下载失败,还有少部分图片因为网站虽然提供1920 × 1080分辨率的下载按钮却给的其它分辨率
目录四:代码分析
- 下文中凡是 红色加粗内容,请按照我的解释,根据自身情况进行修改
第一步:设置全局变量
index = 'http://www.netbian.com' # 网站根地址
interval = 10 # 爬取图片的间隔时间
firstDir = 'D:/zgh/Pictures/netbian' # 总路径
classificationDict = {
} # 存放网站分类子页面的信息
- index ,要爬取网页的网站根地址,代码中爬取图片需要使用其拼接完整url
- interval,我们去爬取一个网站的内容时要考虑到该网站服务器的承受能力,短时间内爬取该网站大量内容会给该网站服务器造成巨大压力,我们需要在爬取时设置间隔时间
单位:秒
由于我要爬取彼岸桌面网站的全部高清图片,若集中在短时间内爬取,一方面会给网站服务器巨大的压力,一方面网站服务器会将我们的链接强制断掉,所以我设置的每张图片爬取时间间隔为10秒;如果你只是爬取少量图片,可以将间隔时间设置的短点 - firstDir,爬取图片存放在你电脑上的根路径;代码中爬取图片时,在一级目录下会按照彼岸桌面唯美分类下的分页页码生成文件夹并存放图片
- classificationDict,存放网站下分类指向的url、对应的分类文件夹路径
第二步:获取页面筛选后的内容列表
写一个函数,获取页面筛选后的内容数组
- 传进来两个参数
url:该网页的url
select:选择器(与CSS中的选择器无缝对接,我很喜欢,定位到HTML中相应的元素) - 返回一个列表
def screen(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers()) # 随机获取一个headers
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)
- headers,作用是假装是个用户访问该网站,为了保证爬虫的成功率,每一次爬取页面随机抽取一个headers
- encoding ,该网站的编码

第三步:获取全部分类的url
# 将分类子页面信息存放在字典中
def init_classification():
url = index
select = '#header > div.head > ul > li:nth-child(1) > div > a'
classifications = screen(url, select)
for c in classifications:
href = c.get('href') # 获取的是相对地址
text = c.string # 获取分类名
if(text == '4k壁纸'): # 4k壁纸,因权限问题无法爬取,直接跳过
continue
secondDir = firstDir + '/' + text # 分类目录
url = index + href # 分类子页面url
global classificationDict
classificationDict[text] = {
'path': secondDir,
'url': url
}
接下来的代码,我以唯美分类下的壁纸,来讲解怎么通过跳转两次链接爬取高清图片
第四步:获取分类页面下所有分页的url
大部分分类的分页大于等于6页,可以直接使用上面定义的screen函数,select定义为div.page a,然后screen函数返回的列表中第6个元素可以获取我们需要的最后一页页码
但是,有的分类的分页小于6页,
比如:

需要重新写一个筛选函数,通过兄弟元素来获取
# 获取页码
def screenPage(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers())
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)[0].next_sibling.text
获取分类页面下所有分页的url
url = 'http://www.netbian.com/weimei/'
select = '#main > div.page > span.slh'
pageIndex = screenPage(secondUrl, select)
lastPagenum = int(pageIndex) # 获取最后一页的页码
for i in range(lastPagenum):
if i == 0:
url = 'http://www.netbian.com/weimei/index.htm'
else:
url = 'http://www.netbian.com/weimei/index_%d.htm' %(i+1)
由于该网站的HTML结构非常清晰,所以代码写起来简单明了
第五步:获取分页下图片所指url
通过检查,可以看到获取到的url为相对地址,需要将其转化为绝对地址

select = 'div#main div.list ul li a'
imgUrls = screen(url, select)
通过这两行代码获取的列表中的值,形如此:
<a href="/desk/21237.htm" target="_blank" title="星空 女孩 观望 唯美夜景壁纸 更新时间:2019-12-06"><img alt="星空 女孩 观望 唯美夜景壁纸" src="http://img.netbian.com/file/newc/e4f018f89fe9f825753866abafee383f.jpg"/><b>星空 女孩 观望 唯美夜景壁纸</b></a>
- 需要对获取的列表进行处理
- 获取a标签中的href属性值,并将其转化为绝对地址,这是第一次跳转所需要的url
第六步:定位到 1920 × 1080 分辨率图片
# 定位到 1920 1080 分辨率图片def handleImgs(links, path):
for link in links:
href = link.get('href')
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
# 第一次跳转
if('http://' in href): # 有极个别图片不提供正确的相对地址
url = href
else:
url = index + href
select = 'div#main div.endpage div.pic div.pic-down a'
link = screen(url, select)
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
href = link[0].get('href')
# 第二次跳转
url = index + href
# 获取到图片了
select = 'div#main table a img'
link = screen(url, select)
if(link == []):
print(url + " 该图片需要登录才能爬取,爬取失败")
continue
name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('<', '').replace('>', '')
print(name) # 输出下载图片的文件名
src = link[0].get('src')
if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
print()
download(src, name, path)
time.sleep(interval)
第七步:下载图片
下载操作
def download(src, name, path):
if(isinstance(src, str)):
response = requests.get(src)
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
with open(path,'wb') as pic:
for chunk in response.iter_content(128):
pic.write(chunk)
目录五:代码的容错能力
一:过滤图片广告
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
二:第一次跳转页面,无我们需要的链接
彼岸壁纸网站,对第一次跳转页面的链接,给的都是相对地址
但是极个别图片直接给的绝对地址,而且给的是该分类网址,所以需要做两步处理
if('http://' in href):
url = href
else:
url = index + href
...
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
下面是第二次跳转页面所遇问题
三:由于权限问题无法爬取图片
if(link == []):
print(url + "该图片需要登录才能爬取,爬取失败")
continue
四:获取img的alt,作为下载图片文件的文件名时,名字中携带\t 或 文件名不允许的特殊字符:
- 在Python中,’\t’ 是转义字符:空格
- 在windows系统当中的文件命名,文件名称中不能包含 \ / : * ? " < > | 一共9个特殊字符

name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('<', '').replace('>', '')
五:获取img的alt,作为下载图片文件的文件名时,名字重复
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
六:图片链接404
比如:

if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
目录六:完整代码
- 蓝奏云链接:Python爬虫,高清美图我全都要(彼岸桌面壁纸).zip
下载下来解压后,有两个python文件
原博客原址:https://blog.csdn.net/Zhangguohao666/article/details/105131503