今天我们继续爬取一个网站,这个网站为 http://image.fengniao.com/ ,蜂鸟一个摄影大牛聚集的地方,本教程请用来学习,不要用于商业目的,不出意外,蜂鸟是有版权保护的网站。

Python学习资料或者需要代码、视频加Python学习群:960410445
2. 网站分析
第一步,分析要爬取的网站有没有方法爬取,打开页面,找分页
http://image.fengniao.com/index.php?action=getList&class_id=192⊂_classid=0&page=1¬_in_id=5352384,5352410http://image.fengniao.com/index.php?action=getList&class_id=192⊂_classid=0&page=2¬_in_id=5352384,5352410http://image.fengniao.com/index.php?action=getList&class_id=192⊂_classid=0&page=3¬_in_id=5352384,5352410http://image.fengniao.com/index.php?action=getList&class_id=192⊂_classid=0&page=4¬_in_id=5352384,5352410
上面的页面发现一个关键的参数 page=1 这个就是页码了,但是另一个比较头疼的问题是,他没有最后的页码,这样我们没有办法确定循环次数,所以后面的代码编写中,只能使用 while 了
这个地址返回的是JSON格式的数据,这个对爬虫来说,非常友好!省的我们用正则表达式分析了。

分析这个页面的头文件,查阅是否有反爬措施

发现除了HOST和User-Agent以外,没有特殊的点,大网站就是任性,没啥反爬,可能压根不在乎这个事情。
第二步,分析图片详情页面,在我们上面获取到的JSON中,找到关键地址

关键地址打开之后,这个地方有一个比较骚的操作了,上面图片中标注的URL选的不好,恰好是一个文章了,我们要的是组图,重新提供一个新链接 http://image.fengniao.com/slide/535/5352130_1.html#p=1
打开页面,你可能直接去找规律了,找到下面的一堆链接,但是这个操作就有点复杂了,我们查阅上述页面的源码
http://image.fengniao.com/slide/535/5352130_1.html#p=1http://image.fengniao.com/slide/535/5352130_1.html#p=2http://image.fengniao.com/slide/535/5352130_1.html#p=3....
网页源码中发现了,这么一块区域

大胆的猜测一下,这个应该是图片的JSON,只是他打印在了HTML中,我们只需要用正则表达式进行一下匹配就好了,匹配到之后,然后进行下载。
第三步,开始撸代码。

3. 写代码

上面的链接已经生成,下面就是下载图片了,也非常简单
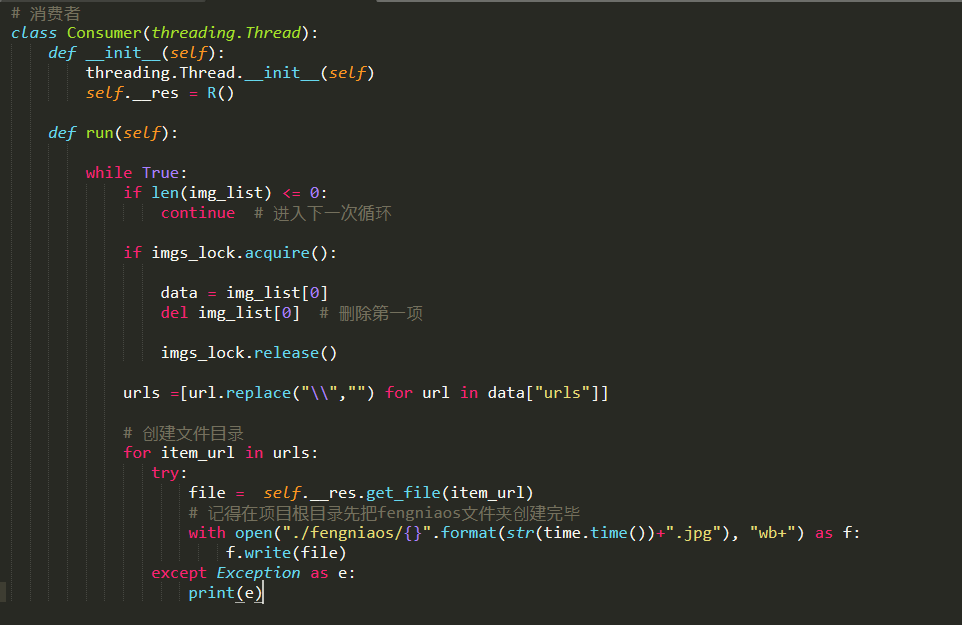
代码走起,结果
