目录
2.3 Redis对象类型——type(第一层)& encoding(第二层)
2.4 字符串内部实现——int & raw & embstr
2.5 列表的内部实现——ziplist & linkedlist编码
2.6 集合类型内部实现——intset & hashtable编码
2.7 有序集合类型内部实现——ziplist & skiplist 编码
2.8 哈希类型内部实现——ziplist & hashtable 编码
1 redis简单入门
redis是一款高性能的NOSQL系列的非关系型数据库
1.1 NOSQL
NOSQL(NOSQL = Not Only SQL),是一项全新的数据库理念,泛指非关系型的数据库。
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
相较于关系型数据库:
优点:
- 成本:nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
- 查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
- 存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
- 扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。
缺点:
- 维护工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10几年的技术同日而语。
- 不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。
- 不提供关系型数据库对事务的处理。
1.2 下载安装
1. 官网:https://redis.io
2. 中文网:http://www.redis.net.cn/
3. 解压直接可以使用:
redis.windows.conf:配置文件
redis-cli.exe:redis的客户端
redis-server.exe:redis服务器端
1.3 基本命令
1.3.1 redis的数据结构
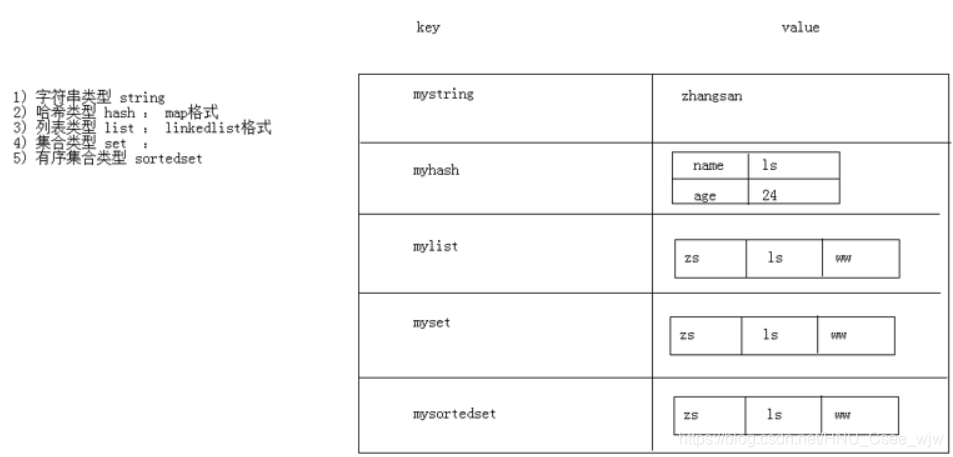
redis存储的是 key,value 格式的数据,其中key都是字符串,value有5种不同的数据结构
value的数据结构:
- 字符串类型 string
- 哈希类型 hash : map格式
- 列表类型 list : linkedlist格式。支持重复元素
- 集合类型 set : 不允许重复元素
- 有序集合类型 sortedset:不允许重复元素,且元素有顺序
1.3.2 字符串类型 string
1. 存储: set key value
127.0.0.1:6379> set username zhangsan
OK
2. 获取: get key
127.0.0.1:6379> get username
"zhangsan"
3. 删除: del key
127.0.0.1:6379> del age
(integer) 1
1.3.3 哈希类型 hash
1. 存储: hset key field value
127.0.0.1:6379> hset myhash username lisi
(integer) 1
127.0.0.1:6379> hset myhash password 123
(integer) 1
2. 获取:
- hget key field: 获取指定的field对应的值
127.0.0.1:6379> hget myhash username
"lisi"
- hgetall key:获取所有的field和value
127.0.0.1:6379> hgetall myhash
1) "username"
2) "lisi"
3) "password"
4) "123"
3. 删除: hdel key field
127.0.0.1:6379> hdel myhash username
(integer) 1
1.3.4 列表类型 list
可以添加一个元素到列表的头部(左边)或者尾部(右边)
1. 添加:
- lpush key value: 将元素加入列表左表
- rpush key value:将元素加入列表右边
127.0.0.1:6379> lpush myList a
(integer) 1
127.0.0.1:6379> lpush myList b
(integer) 2
127.0.0.1:6379> rpush myList c
(integer) 3
2. 获取:
- lrange key start end :范围获取
127.0.0.1:6379> lrange myList 0 -1
1) "b"
2) "a"
3) "c"
3. 删除:
- lpop key: 删除列表最左边的元素,并将元素返回
- rpop key: 删除列表最右边的元素,并将元素返回
1.3.5 集合类型 set : 不允许重复元素
1. 存储:sadd key value
127.0.0.1:6379> sadd myset a
(integer) 1
127.0.0.1:6379> sadd myset a
(integer) 0
2. 获取:smembers key:获取set集合中所有元素
127.0.0.1:6379> smembers myset
1) "a"
3. 删除:srem key value:删除set集合中的某个元素
127.0.0.1:6379> srem myset a
(integer) 1
1.3.6 有序集合类型 sortedset
不允许重复元素,且元素有顺序.每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
1. 存储:zadd key score value
127.0.0.1:6379> zadd mysort 60 zhangsan
(integer) 1
127.0.0.1:6379> zadd mysort 50 lisi
(integer) 1
127.0.0.1:6379> zadd mysort 80 wangwu
(integer) 1
2. 获取:zrange key start end [withscores]
127.0.0.1:6379> zrange mysort 0 -1
1) "lisi"
2) "zhangsan"
3) "wangwu"
127.0.0.1:6379> zrange mysort 0 -1 withscores
1) "zhangsan"
2) "60"
3) "wangwu"
4) "80"
5) "lisi"
6) "500"
3. 删除:zrem key value
127.0.0.1:6379> zrem mysort lisi
(integer) 1
1.3.7 通用命令
1. keys * : 查询所有的键
2. type key : 获取键对应的value的类型
3. del key:删除指定的key value
2 redis编码及数据结构
上面都是一些redis的基本入门级操作,接下来对于底层的分析是重点
2.1 redis支持的数据类型
2.2 Redis对象源码(3.0版)

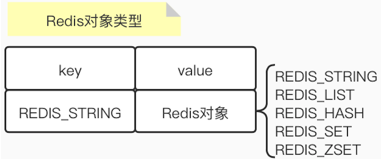
redisObject类的属性有三个:
- type:类型
- encoding:对象的编码
- int,embstr,raw,ht(哈希表),linkedlist,ziplist(连续空间),intset,skiplist(跳表)
- ptr:指向底层实现数据结构的指针
type可以看做是第一层、encoding可以看做是第二层、ptr可以看做是第三层,他们之间有一些对应关系。
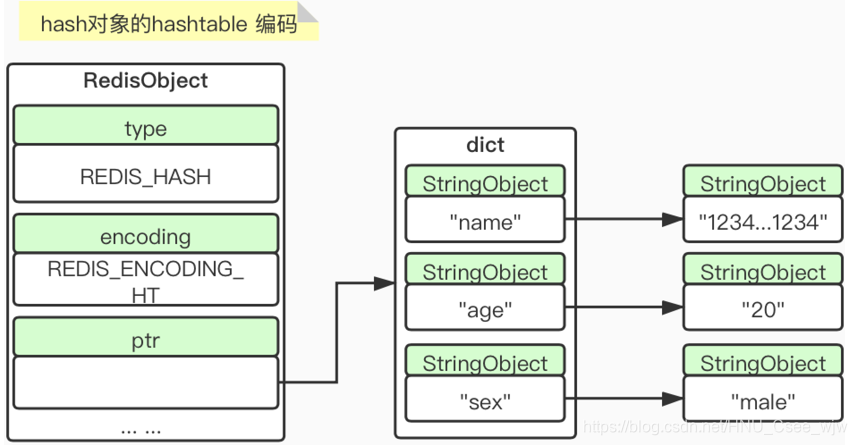
2.3 Redis对象类型——type(第一层)& encoding(第二层)
redis对象的key都是String的,value就是其支持的5种数据类型。我们可以用TYPE命令查看value的类型:
5个数据类型与源码中的8个encoding(编码)类型的对照关系(第一层和第二层对照):

之所以有这么多的对照关系是因为redis支持了针对不同应用场景来采用不同的数据结构,具有更大的灵活性。
我们可以用OBJECT encoding命令来查看相应的encoding类型:
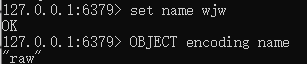
2.4 字符串内部实现——int & raw & embstr

int编码很简单,ptr指向一个int型数据
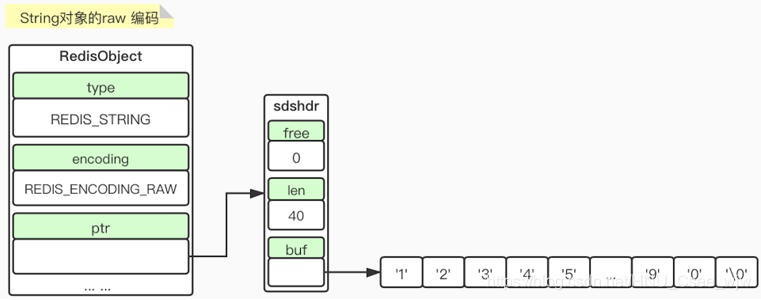
raw的内部实现是ptr指向一个sds(可以简单的理解为redis中实现的字符串)。
free属性表示预留的空闲空间,len表示实际字符串的长度,buf是指向一个字符数组的指针。
预留空间:当申请的空间较小时,C语言在申请len这么多的空间时会申请一份同样大小的预留空间。
惰性空间释放:删除数据时,free的值会增加,而不是真正的把数据给释放掉
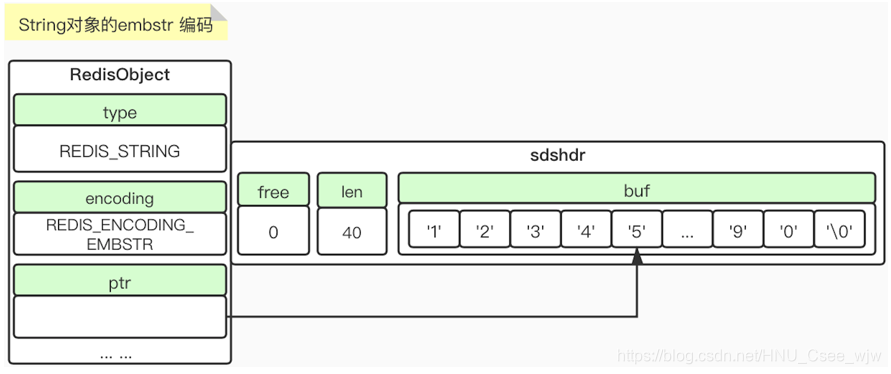
embstr结构和raw的类似,只不过ptr不是指向sds的指针了,而是一个连续空间,ptr后面紧跟着sds对象,所以查询会非常快,但这种方式并不适合存储大量数据。
选择编码格式的规则:
- 如果设置的数字是一个long类型的,那么其encoding就是int
- 如果不是long类型表示的整形数字,那么用raw或者embstr
- 长度小于等于39则是embstr
- 长度大于40则是raw
- embstr是一个只读的,如果要修改这样类型的数据,修改之后的结果会变为raw

2.5 列表的内部实现——ziplist & linkedlist编码
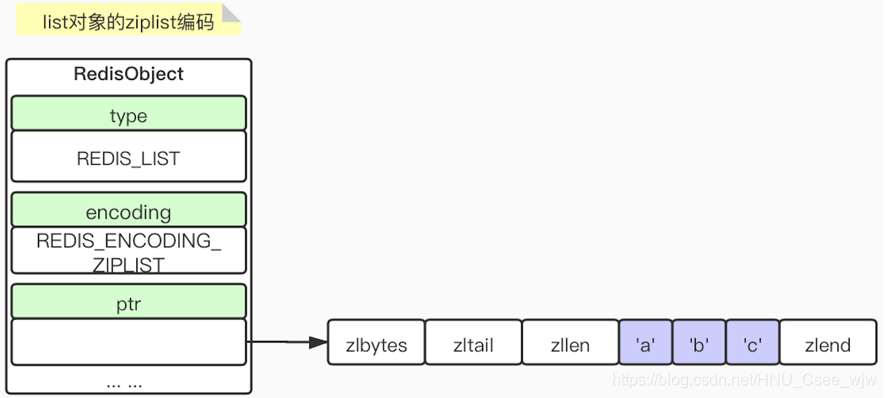
zlbytes:记录整个列表占用的内存字节数
zltail:记录列表尾节点距离压缩列表的起始地址有多少字节
zllen:包含的节点数量
zlend:标记压缩列表的末端

linkedlist是一个双向链表,但头节点的前驱指针指向的是null,尾节点的后继指针指向的是null,不是一个环形链表
2.6 集合类型内部实现——intset & hashtable编码
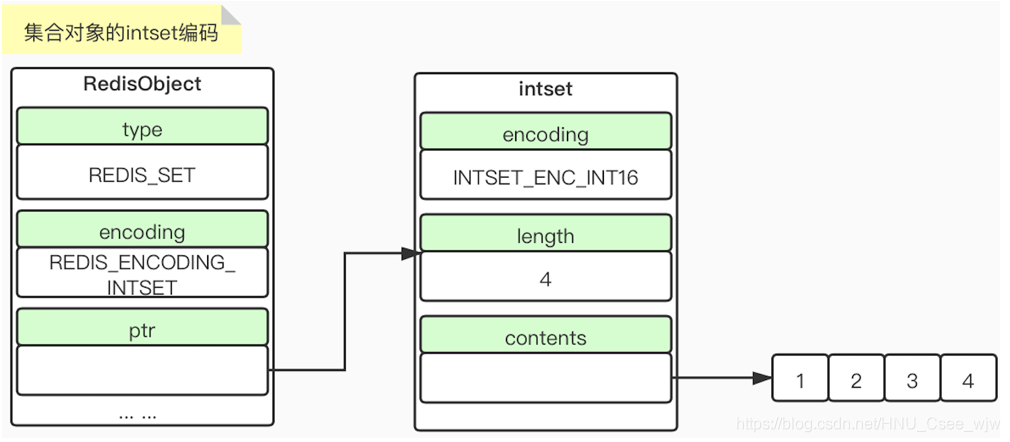
ptr指向intset,inset中针对不同的应用有不同的编码,为了防止空间的浪费。
length表示contents对应的数组的长度
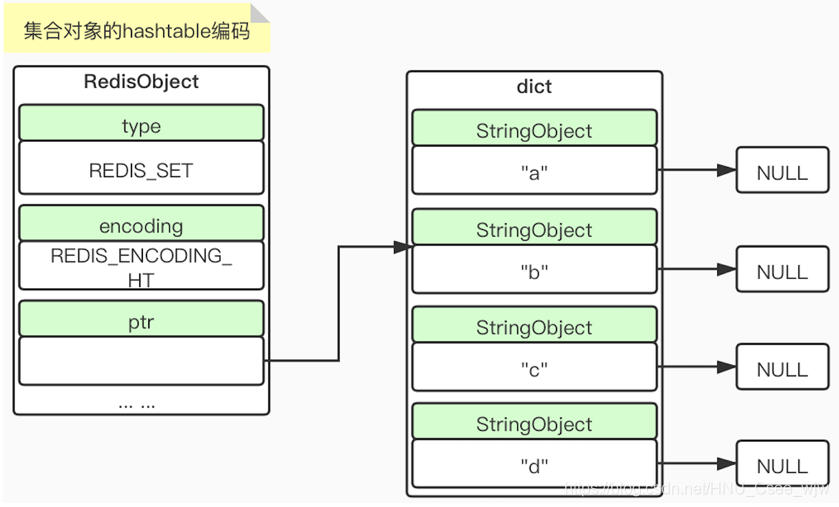
ptr指向一个dict(字典),并且这个dict的value部分都是null
当我们向set中添加整数类型的数据时,set用intset来实现,否则使用hashtable来实现的。此外,如果数据量较大,一般是超过512时也会使用hashtable
2.7 有序集合类型内部实现——ziplist & skiplist 编码
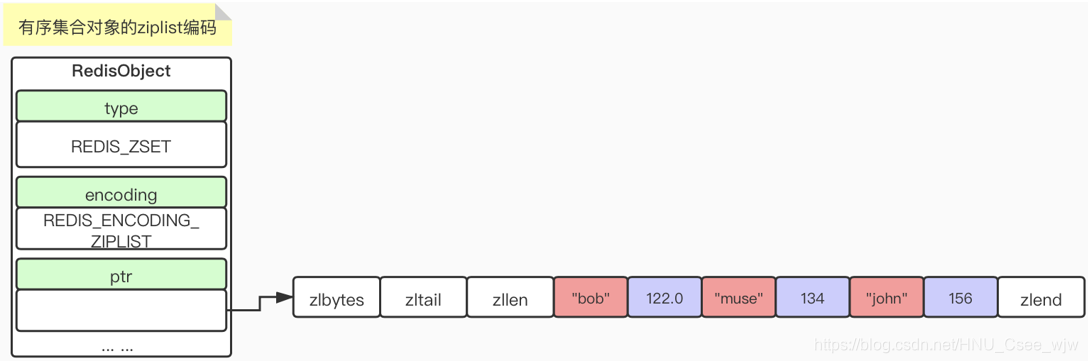
ziplist中的ptr指向一段连续的内存空间,所有的键值对紧密相连并从队尾推入,当我们zadd 122 bob 134 muse 156 john之后内存中的示意图就如上图所示。同样地,如果存储的数据元素个数超过一定的阈值的话,就会转换成skiplist
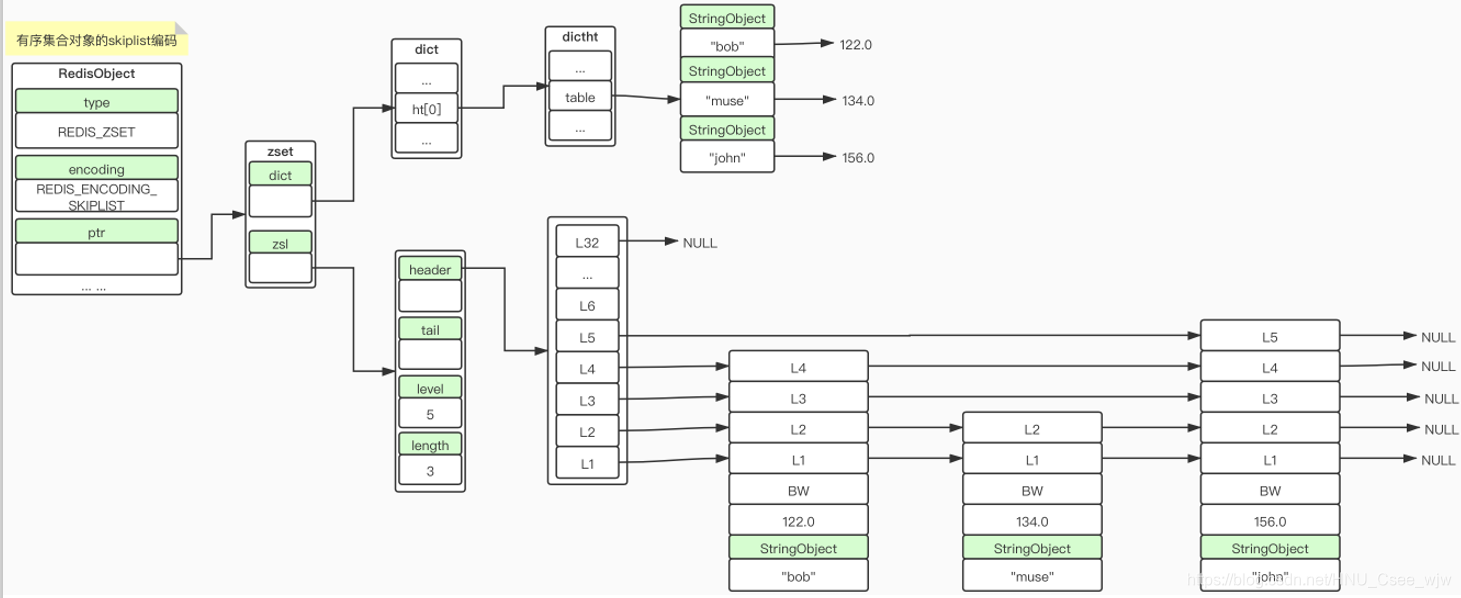
skiplist中有两种数据结构,跳表和哈希表(dictht),因为不同的业务逻辑无法用同一种数据结构来达到完美的效果。
跳表中的level对应的是maxlevel,即length最长的节点的层(L)数,上图一共有三个节点bob,muse和john对应length1,2,3。
跳表的查找过程:
如果要查找muse,先从L5往后查发现是john,又从L4开始查发现是bob和john,又从L2查到结果,因此level越大,查询的跨度越大
2.8 哈希类型内部实现——ziplist & hashtable 编码

和set类似,ziplist上面已经介绍过了就不再赘述,存储的键值对超过一定阈值时就转变为hashtable