前言
通过《redis概述》我们了解了其常用的五种数据结构。其内部是怎么编码的呢?
redis对象头
redis中所有对象的共同的头结构
// 可以使用 debug object key 查看
typedef struct redisObject {
// 类型属性存储的是对象的类型,也就是我们说的 string、list、hash、set、zset中的一种,
//可以使用命令 TYPE key 来查看。
unsigned type;
// 编码,记录了队形所使用的编码,即这个对象底层使用哪种数据结构实现。
// 可以使用 object encoding key 来查看
unsigned encoding;
// LRU 最近使用的时间
unsigned lru;
// 引用计数,=0时,会被回收
// redis 启动时会将1-9999的数,放到共享对象池。此时的refcount不是1
// object refcount key
int refcount;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
type与encoding对应关系如下图
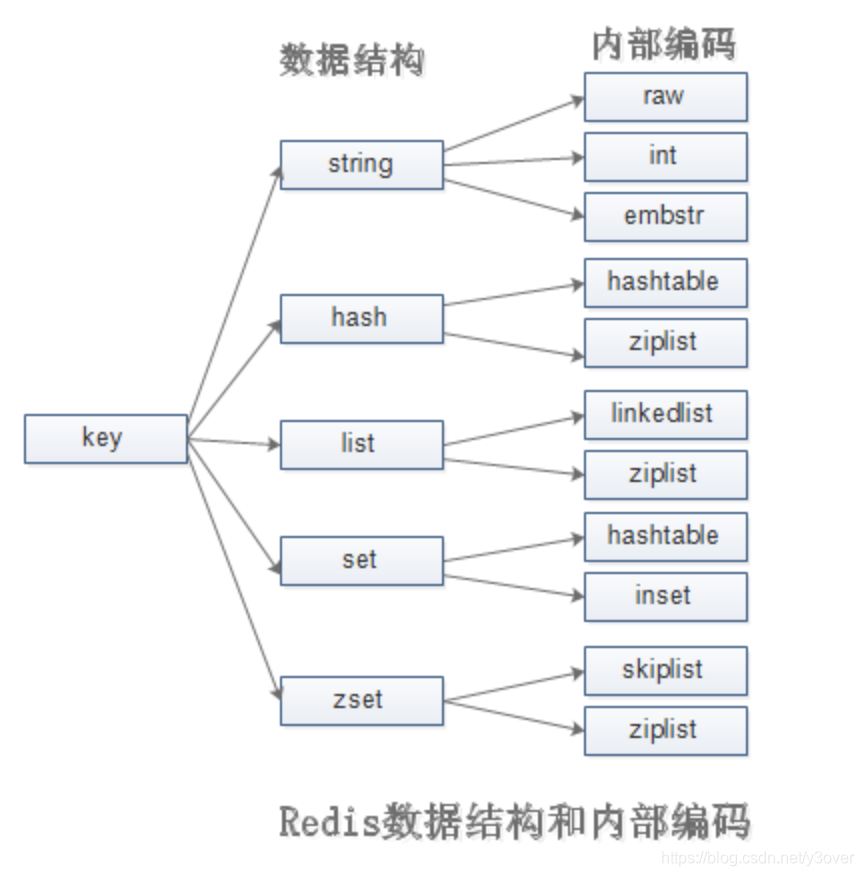
string
- int: java中long的取值范围8字节
- embstr: 44字节以内字符串
- raw:44字节以上的字符串
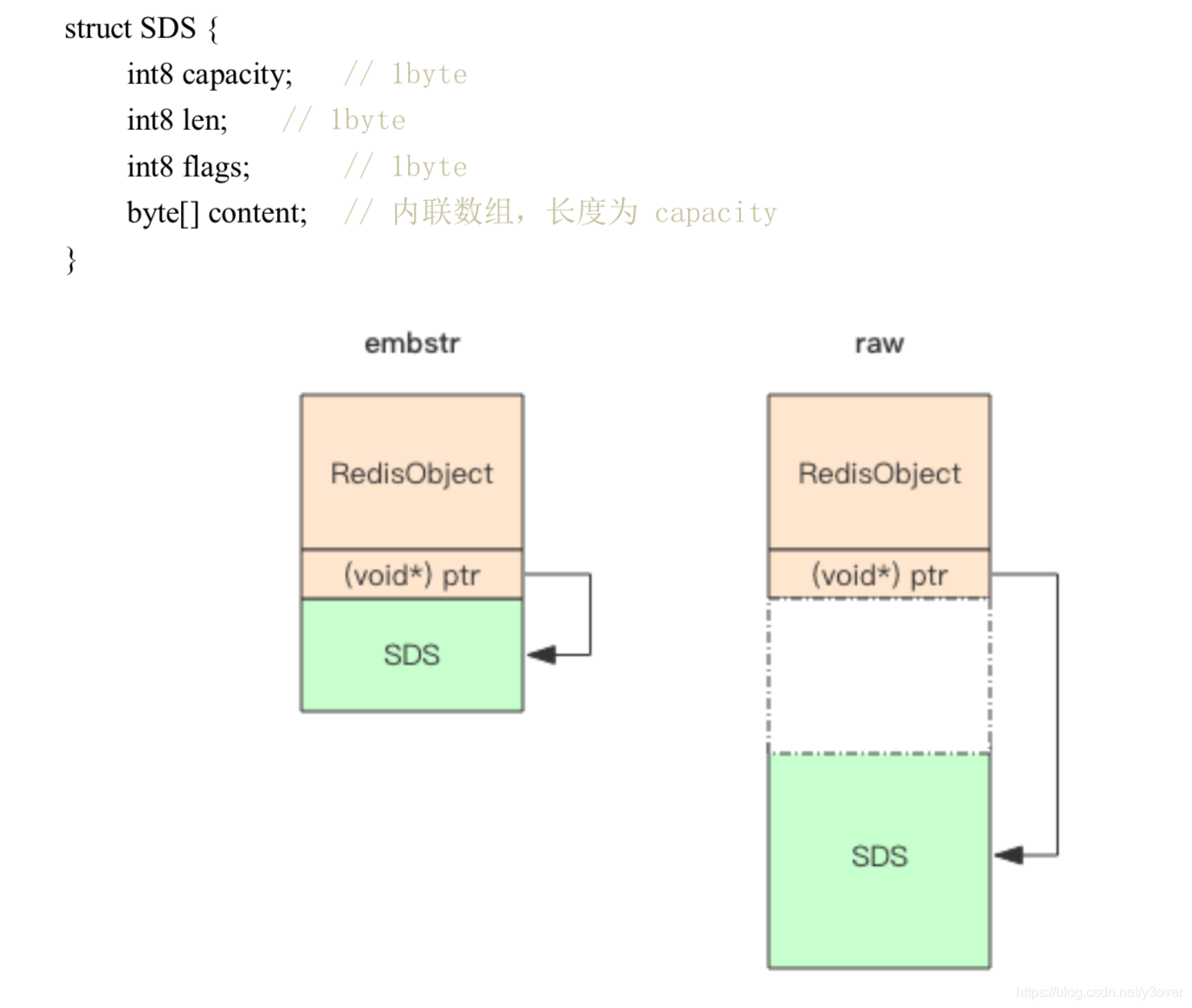
embstr 存储形式是这样一种存储形式,它将 RedisObject 对象头和 SDS 对象连续存在一起,使用 malloc 方法一次分配。而 raw 存储形式不一样,它需要两次 malloc,两个对象头在内存地址上一般是不连续的
为什么是44字节?
redisObject = 4bits + 4bits + 3byte + 4byte + 8 byte = 16byte
SDS = 3byte + content
content = 64(一次分配的大小) - 16 - 3 - 1(content最后面的结构符\0) = 44 byte;
- 扩容策略:在需要空间达1M之前按新空间两倍分配空间,否则按新空间大小+1M分配
- 惰性缩容:不释放空间,留给到期释放等机制释放。
List
Redis 列表使用主要使用两种数据结构双端链表与压缩列表作为底层实现。
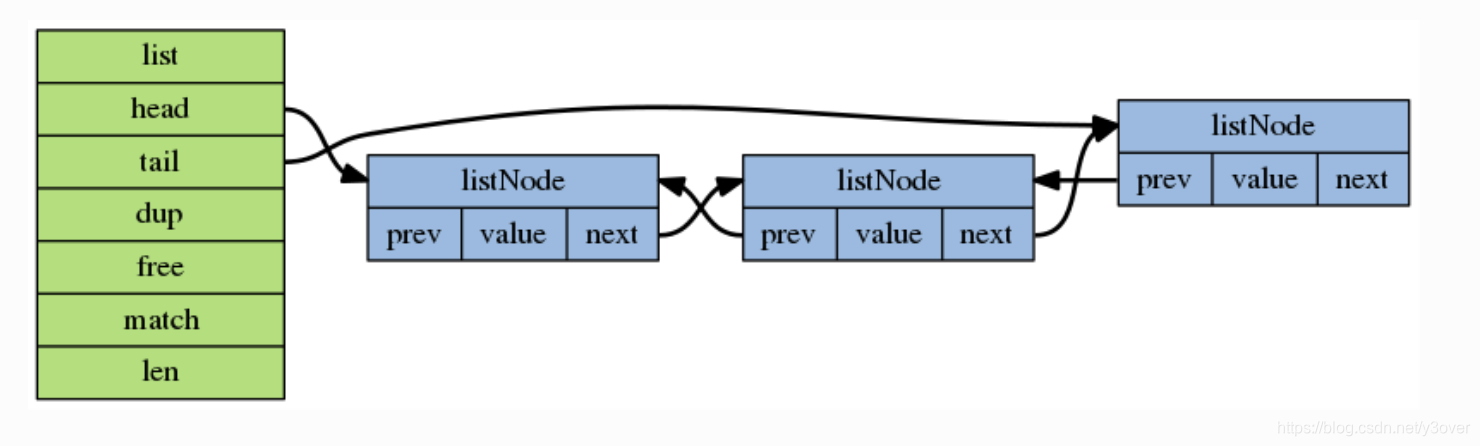
双端链表linkedlist
// 结点
typedef struct listNode {
//指向前一个节点
struct listNode *prev;
//指向后一个节点
struct listNode *next;
//值
void *value;
} listNode;
typedef struct list {
// 表头指针
listNode *head;
// 表尾指针
listNode *tail;
// 节点数量
unsigned long len;
} list;
双端链表ziplist
ziplist 是由一系列特殊编码的内存块构成的列表,它可以保存字符数组或整数值,它还是哈希键、列表键和有序集合键的底层实现之一。
struct ziplist<T> {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
struct entry {
int<var> prevlen; // 前一个 entry 的字节长度
int<var> encoding; // 元素类型编码
optional byte[] content; // 元素内容
}
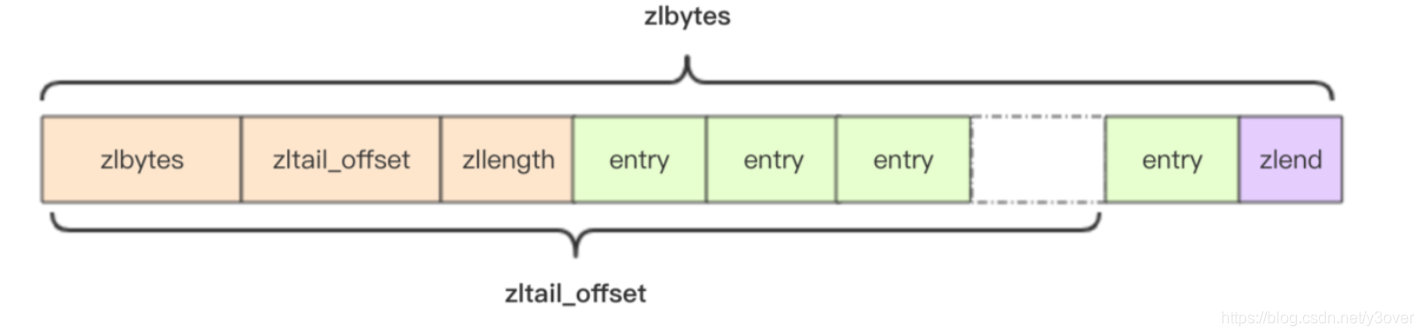
- ztail_offset 这个字段,用来快速定位到最后一个元素,然后配合prelen倒着遍历
- prelen是一个变长的整数,当字符串长度小于 254(0xFE) 时,使用一个字节表示;如果达到或超出 254(0xFE) 那就使用 5 个字节来表示。第一个字节是 0xFE(254),剩余四个字节表示字符串长度
- encoding字段存储了元素内容的编码类型信息,ziplist 通过这个字段来决定后面的 content 内容的形式。
- 00xxxxxx 最大长度位 63 的短字符串,后面的 6 个位存储字符串的位数,剩余的字节就是字符串的内容。
- 01xxxxxx xxxxxxxx 中等长度的字符串,后面 14 个位来表示字符串的长度,剩余的字节就是字符串的内容。
- 10000000 aaaaaaaa bbbbbbbb cccccccc dddddddd 特大字符串,需要使用额外 4 个字节来表示长度。第一个字节前缀是10,剩余 6 位没有使用,统一置为零。后面跟着字符串内容。不过这样的大字符串是没有机会使用的,压缩列表通常只是用来存储小数据的。
- 11000000 表示 int16,后跟两个字节表示整数。
- 11010000 表示 int32,后跟四个字节表示整数。
- 11100000 表示 int64,后跟八个字节表示整数。
- 11110000 表示 int24,后跟三个字节表示整数。
- 11111110 表示 int8,后跟一个字节表示整数。
- 11111111 表示 ziplist 的结束,也就是 zlend 的值 0xFF。
- 1111xxxx 表示极小整数,xxxx 的范围只能是 (0001~1101), 也就是1~13,因为0000、1110、1111都被占用了。读取到的 value 需要将 xxxx 减 1,也就是整数0~12就是最终的 value。
- content这个字段是可选的,对于很小的整数而言,它的内容已经内联到 encoding 字段的尾部了
快速列表quickList
Redis 早期版本存储 list 列表数据结构使用的是压缩列表 ziplist 和普通的双向链表linkedlist,也就是元素少时用 ziplist,元素多时用 linkedlist。 考虑到链表的附加空间相对太高,prev 和 next 指针就要占去 16 个字节 (64bit 系统的指针是 8 个字节),另外每个节点的内存都是单独分配,会加剧内存的碎片化,影响内存管理效率。后续版本使用了zipList 和 linkedList 的混合体quickList。
struct quicklistNode {
quicklistNode* prev;
quicklistNode* next;
ziplist* zl; // 指向压缩列表
int32 size; // ziplist 的字节总数
int16 count; // ziplist 中的元素数量
int2 encoding; // 存储形式 2bit,原生字节数组还是 LZF 压缩存储
}
struct quicklist {
quicklistNode* head;
quicklistNode* tail;
long count; // 元素总数
int nodes; // ziplist 节点的个数
int compressDepth; // LZF 算法压缩深度
...
}
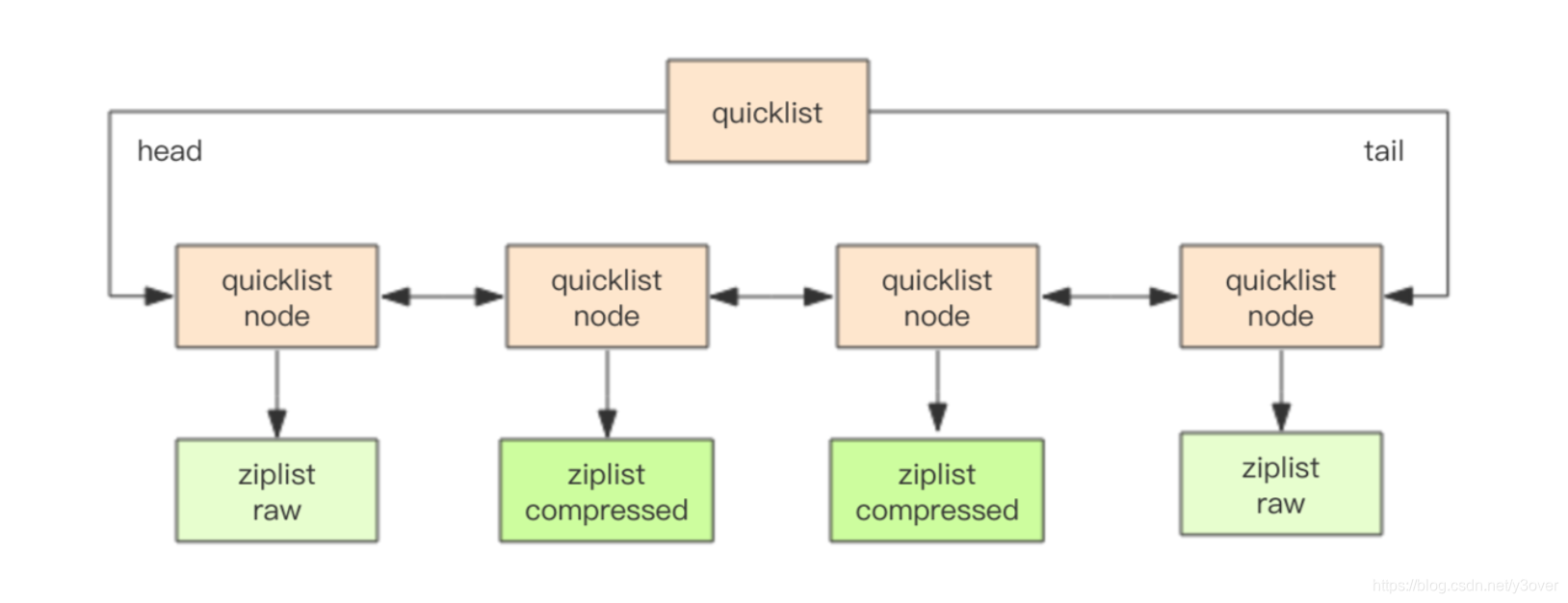
- 压缩深度:quicklist 默认的压缩深度是 0,也就是不压缩。压缩的实际深度由配置参数list-compress-depth决定。
- zipList 长度:quicklist 内部默认单个 ziplist 长度为 8k 字节,超出了这个字节数,就会新起一个 ziplist。ziplist 的长度由配置参数 list-max-ziplist-size 决定。
- 为了支持快速的 push/pop 操作,quicklist 的首尾两个 ziplist 不压缩,此时深度就是 1。如果深度为 2,就表示 quicklist 的首尾第一个 ziplist 以及首尾第二个 ziplist 都不压缩。
Hash
Redis 的 Hash 类型键使用字典和压缩列表结构ziplist作为底层实现。当一个哈希对象可以满足以下两个条件中的任意一个,哈希对象会选择使用ziplist编码来进行存储:
- 哈希对象中的所有键值对总长度(包括键和值)小于64字节(这个阈值可以通过参数hash-max-ziplist-value 来进行控制)。
- 哈希对象中的键值对数量小于512个(这个阈值可以通过参数hash-max-ziplist-entries 来进行控制)
字典hashtable
/*
* 字典
* 每个字典使用两个哈希表,用于实现渐进式 rehash
*/
typedef struct dict {
// 特定于类型的处理函数
dictType *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2 个)
dictht ht[2];
// 记录 rehash 进度的标志,值为-1 表示 rehash 未进行
int rehashidx;
// 当前正在运作的安全迭代器数量
int iterators;
} dict;
/*
* 哈希表
*/
typedef struct dictht {
// 哈希表节点指针数组(俗称桶,bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
/*
* hash节点
*/
typedef struct dictEntry {
//键
void *key;
//值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
//指向下一个节点
struct dictEntry *next;
} dictEntry;
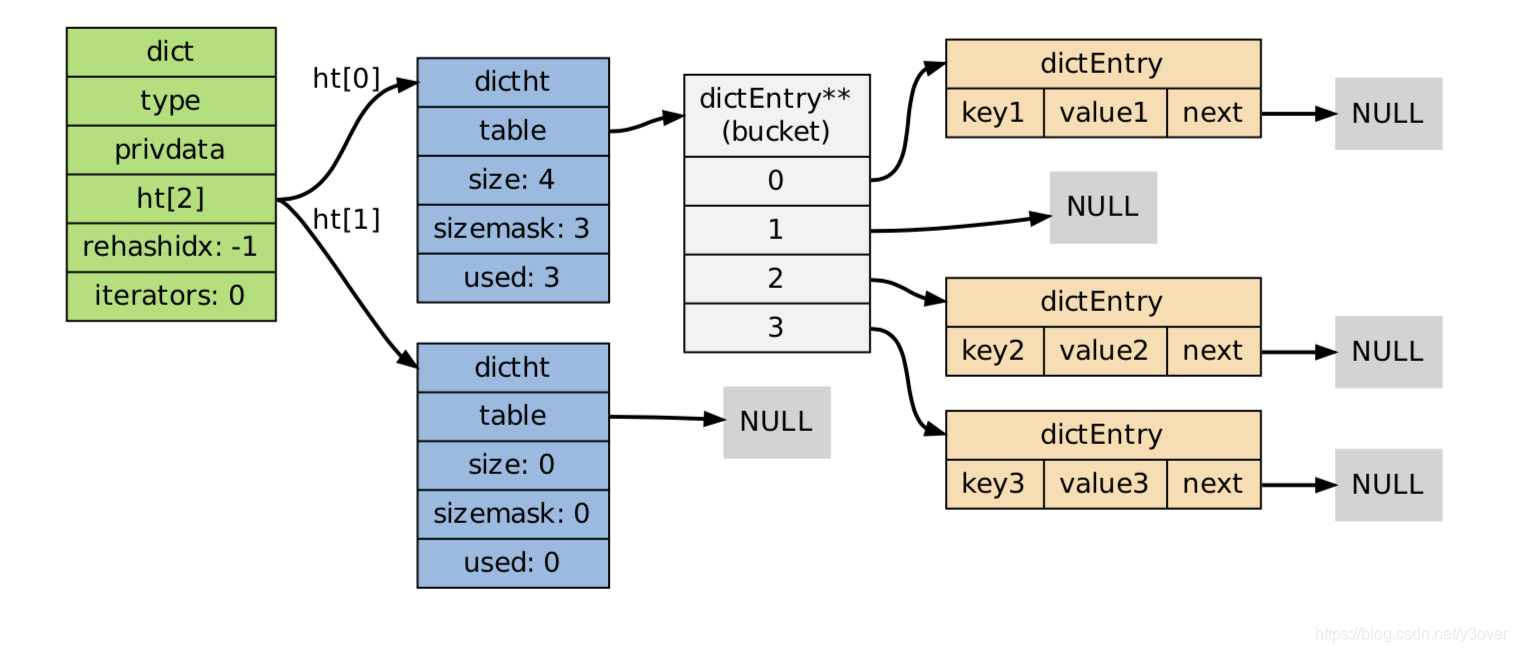
与java中《散列hash表》极其相似
- 哈希表使用链地址法来解决键冲突的问题。
- 每个字典使用两个哈希表ht[0]各ht[]1,一般情况下只使用 0 号哈希 表,只有在 rehash 进行时,才会同时使用 0 号和 1 号哈希表。
- Rehash 可以用于扩展或收缩哈希表。
- 当 hash 表中元素的个数等于第一维数组的长度时,就会开始扩容
- 缩容的条件是元素个数低于数组长度的 10%
- 对哈希表的 rehash 是分多次、渐进式地进行的。rehash过程必须将所有键值对迁移完毕之后才将结果返回给用户,这样的处理方式将是非常不友好的。
- 在执行添加操作时,新的节点会直接添加到ht[1]而不是ht[0]
- 在 rehash 时,字典会同时使用两个哈希表,所以在这期间的所有查找、删除等操作,除了在 ht[0] 上进行,还需要在 ht[1] 上进行。
压缩列表ziplist
哈希对象中的ziplist和列表对象中ziplist的不同之处在于哈希对象是一个key-value形式.
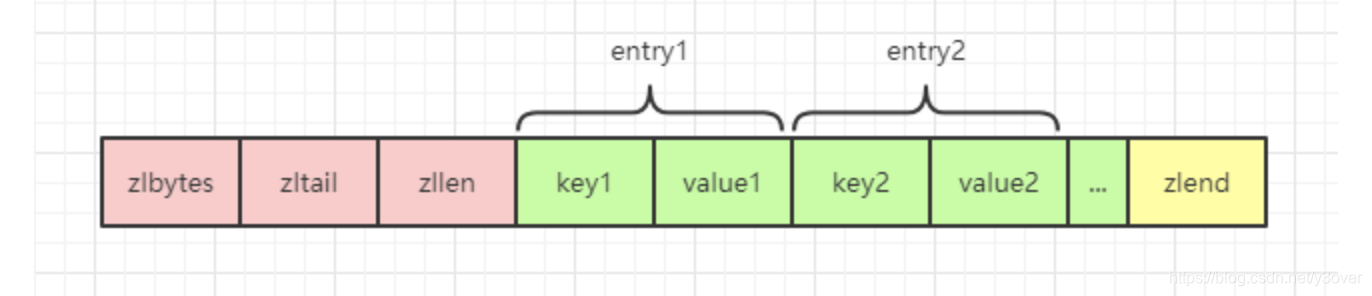
Set
集合对象的底层数据结构有两种:intset和hashtable.当一个集合满足以下两个条件时,Redis会选择使用intset编码:
- 集合对象保存的所有元素都是整数值。
- 集合对象保存的元素数量小于等于512个(这个阈值可以通过配置文件set-max-intset-entries来控制)。
字典hashtable
hashtable结构在前面讲述哈希对象的时候进行过详细分析
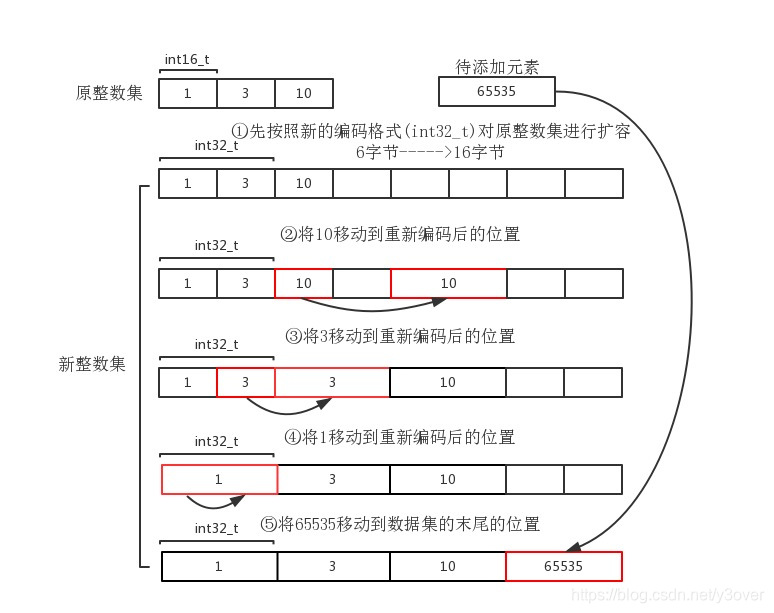
整数集合intset
整数集合intset的底层实现为数组,该数组中的元素有序、无重复的存放,为了更好的节省内存,intset提供了升级操作,但是不支持降级操作.
typedef struct intset {
// 保存元素所使用的类型的长度
uint32_t encoding;
// 元素个数
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
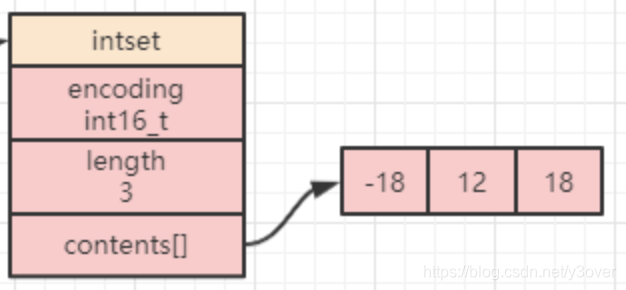
- encoding记录了当前集合的编码方式,主要有三种:
- INTSET_ENC_INT16:此时contents[]内的每个元素都是一个int16_t类型的整数值,范围是:-32768 ~ 32767(-215 ~ 215-1)
- INTSET_ENC_INT32:此时contents[]内的每个元素都是一个int32_t类型的整数值,范围是:-2147483648 ~ 2147483647(-231 ~ 231-1)
- INTSET_ENC_INT64:此时contents[]内的每个元素都是一个int64_t类型的整数值,范围是:-9223372036854775808 ~ 9223372036854775807(-263 ~ 263-1)
- contents[]虽然结构的定义上写的是int8_t类型,但是实际存储类型是由上面的encoding来决定的
整数集合的升级
假如一开始整数集合中的元素都是16位的,采用了int16_t类型来存储,此时需要再存储一个32位的整数,那么就需要对原先的整数集合进行升级,升级之后才能将32位的整数放入整数集合内。
Zset
有序集合对象的底层数据结构有两种:skiplist和ziplist.当有序集合对象同时满足以下两个条件时,会使用ziplist编码进行存储:
- 有序集合对象中保存的元素个数小于128个(可以通过配置zset-max-ziplist-entries修改)。
- 有序集合对象中保存的所有元素的总长度小于64字节(可以通过配置zset-max-ziplist-value修改)。
跳表skiplist
typedef struct zskiplist {
// 头节点,尾节点
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 目前表内节点的最大层数
int level;
} zskiplist;
typedef struct zskiplistNode {
// member 对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 这个层跨越的节点数量
unsigned int span;
} level[];
}zskiplistNode;
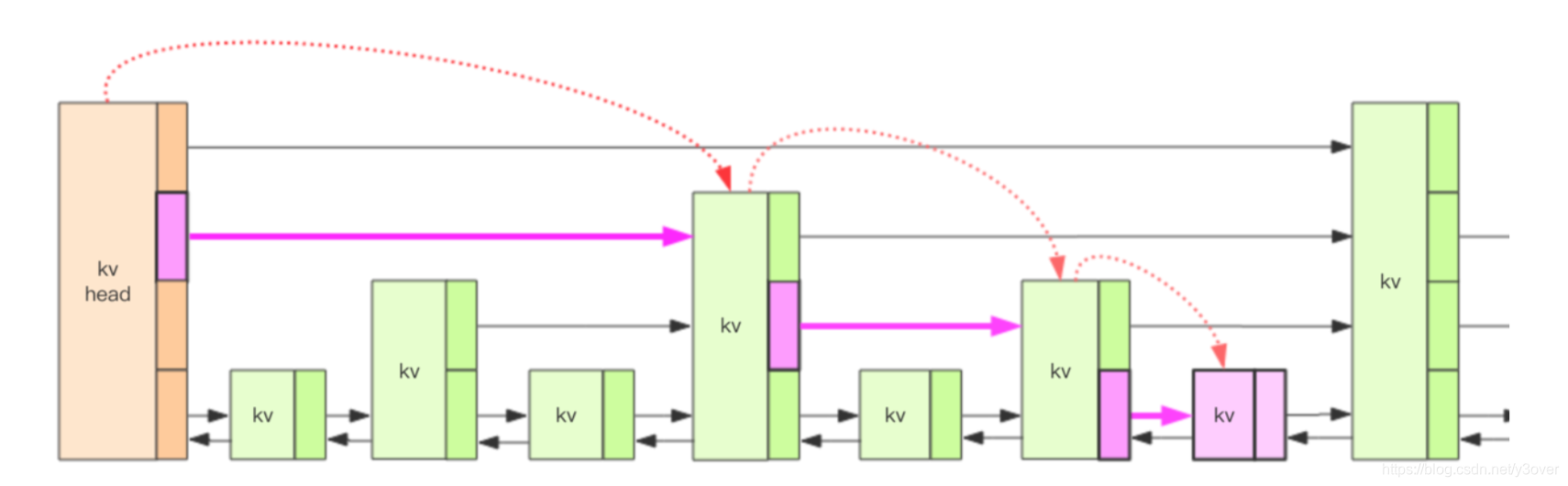
对于每一个新插入的节点,都需要调用一个随机算法给它分配一个合理的层数。直观上期望的目标是 50% 的 Level1,25% 的 Level2,12.5% 的 Level3,一直到最顶层2^-63,因为这里每一层的晋升概率是 50%。 与《跳跃表skipList》
压缩列表ziplist
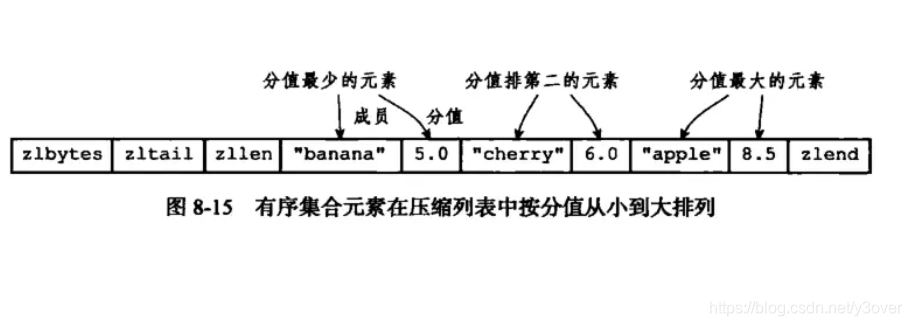
有序集合对象中的ziplist和列表对象中ziplist的不同之处在于哈希对象是一个value-score形式.
主要参考
《Redis 设计与实现》
《Redis开发与运维》
《Redis深度历险:核心原理和应用实践》
《Redis哈希对象之hashtable(哈希表)和ziplist(压缩列表)实现原理分析》
《极限Redis (7) 整数集合Intset》