一、Sharding
Sharding 是把数据库横向扩展(Scale Out)到多个物理节点上的一种有效的方式,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。Shard这个词的意思是“碎片”。如果将一个数据库当作一块大玻璃,将这块玻璃打碎,那么每一小块都称为数据库的碎片(DatabaseShard)。将整个数据库打碎的过程就叫做sharding,可以翻译为分片。
形式上,Sharding可以简单定义为将大数据库分布到多个物理节点上的一个分区方案。每一个分区包含数据库的某一部分,称为一个shard,分区方式可以是任意的,并不局限于传统的水平分区和垂直分区。一个shard可以包含多个表的内容甚至可以包含多个数据库实例中的内容。每个shard被放置在一个数据库服务器上。一个数据库服务器可以处理一个或多个shard的数据。系统中需要有服务器进行查询路由转发,负责将查询转发到包含该查询所访问数据的shard或shards节点上去执行。
三、分表和分区
分表从表面意思说就是把一张表分成多个小表,分区则是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上。
分表和分区的区别
1,实现方式上
mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完正的一张表,都对应三个文件(MyISAM引擎:一个.MYD数据文件,.MYI索引文件,.frm表结构文件)。
2,数据处理上
分表后数据都是存放在分表里,总表只是一个外壳,存取数据发生在一个一个的分表里面。分区则不存在分表的概念,分区只不过把存放数据的文件分成了许多小块,分区后的表还是一张表,数据处理还是由自己来完成。
3,提高性能上
分表后,单表的并发能力提高了,磁盘I/O性能也提高了。分区突破了磁盘I/O瓶颈,想提高磁盘的读写能力,来增加mysql性能。
在这一点上,分区和分表的测重点不同,分表重点是存取数据时,如何提高mysql并发能力上;而分区呢,如何突破磁盘的读写能力,从而达到提高mysql性能的目的。
4,实现的难易度上
分表的方法有很多,用merge来分表,是最简单的一种方式。这种方式和分区难易度差不多,并且对程序代码来说可以做到透明的。如果是用其他分表方式就比分区麻烦了。 分区实现是比较简单的,建立分区表,跟建平常的表没什么区别,并且对代码端来说是透明的。
分区的适用场景
1. 一张表的查询速度已经慢到影响使用的时候。
2. 表中的数据是分段的
3. 对数据的操作往往只涉及一部分数据,而不是所有的数据
分表的适用场景
1. 一张表的查询速度已经慢到影响使用的时候。
2. 当频繁插入或者联合查询时,速度变慢。
分表的实现需要业务结合实现和迁移,较为复杂。
四、分表和分库
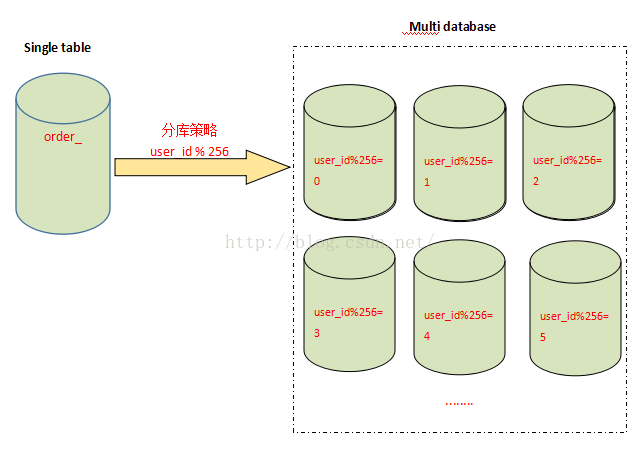
分表能够解决单表数据量过大带来的查询效率下降的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库master服务器无法承载写操作压力时,不管如何扩展slave服务器,此时都没有意义了。因此,我们必须换一种思路,对数据库进行拆分,从而提高数据库写入能力,这就是所谓的分库。
与分表策略相似,分库可以采用通过一个关键字取模的方式,来对数据访问进行路由,如下图所示
五、分库分表存在的问题
1 事务问题。
在执行分库之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
2 跨库跨表的join问题。
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
3 额外的数据管理负担和数据运算压力。
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,只需一个order by语句就可以搞定,但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
解决方案
1. 使用分布式事物机制