论文:A brief review of image denoising algorithms and beyond
(收获不是很大,简单用翻译整理一下,之后方便回顾)
摘要
硬件和成像系统的最新进展使数码相机无处不在。 尽管在过去的几十年中,硬件的发展已稳步提高了图像的质量,但由于许多因素会影响图像采集过程和后续的后处理,因此不可避免地会导致图像质量下降。 旨在从降级的观察中重建高质量图像的图像去噪是低级计算机视觉领域的一个经典而又非常活跃的话题。 它代表了实际应用中的重要组成部分,例如数字摄影,医学图像分析,遥感,监视和数字娱乐。 同样,图像去噪构成了用于评估图像先验建模方法的理想测试平台。 在本文中,我们简要回顾了图像去噪的最新进展。 我们首先介绍用于图像去噪任务的现有建模方法的概述。 然后,我们回顾了基于稀疏表示的常规去噪算法,基于低秩的去噪算法以及最近提出的基于深度神经网络的方法。 最后,我们讨论了一些新兴的话题和有关图像降噪的未解决问题。
1. 图像去噪
1.1 问题陈述

图像去噪的目的是从嘈杂(退化)的观察中恢复高质量图像。 它是图像处理和计算机视觉中最经典和最基本的问题之一。 一方面,成像系统的普遍使用使图像恢复对于系统性能非常重要。另一方面,输出图像的质量在用户体验以及以下高级视觉任务(例如对象检测和识别)的成功与否中起着至关重要的作用。文献中广泛采用的用于去噪任务的简化的一般图像降级模型为:![]()
其中x代表未知的高质量图像(地面真实情况),y代表退化的观测结果,n代表加性噪声。 数十年来,大多数降噪研究都是针对加性高斯白噪声(AWGN)案例进行的。AWGN假设n为独立的均分高斯噪声,均值为零,标准方差值为σ。 也有一些工作[91、26、35、4、15、32],旨在解决泊松噪声消除或胡椒盐噪声消除任务。 但是,在这次审查中,我们主要关注AWGN清除任务的工作和建议的解决方案。
图像去噪的主要挑战在于,在降级过程中丢失了大量信息,使图像去噪成为病态严重的逆问题。 为了获得对潜像的良好估计,需要先验知识来提供补充信息。 因此,如何适当地对高质量图像的先验建模是图像恢复研究的关键问题。
1.2 用于图像去噪的自然图像先验建模
已经提出了各种各样的方法来提供用于估计去噪图像的补充信息。 根据使用的图像信息,方法可以分为内部(仅使用输入的有噪图像)[7、25、40]和外部(使用具有或没有噪声的外部图像)[98、54、75、93]去噪方法 。 一些工作表明,内部和外部信息的组合或融合可以带来更好的降噪性能[9,60,78,37]。
在这篇综述中,基于先验如何被利用来产生高质量的估计,我们将先前的先验建模方法分为两类:
1.隐式建模方法和
2.显式建模方法。
1.2.1 隐式方法
隐式方法的类别隐式采用高质量图像的先验,其中先验被嵌入到特定的还原操作中。 早期的大多数图像去噪算法都使用了这种隐式建模策略[80,66,85]。 基于高质量图像的假设,已设计启发式操作以直接从降级图像生成估计。 例如,基于平滑度假设,基于过滤的方法[80、84、19、59]已被广泛用于消除噪声图像中的噪声。 尽管没有对图像先验进行明确建模,但是在设计过滤器以估计干净图像时会考虑使用高质量图像的先验。 数十年来,这种隐式建模方案一直主导着图像去噪领域。为了产生分段的平滑图像信号,已经提出了扩散方法[66、85]来自适应地平滑图像内容。 通过假定自然图像的小波系数是稀疏的,已经开发了收缩方法来对小波域中的图像进行降噪[29,24]。 基于自然图像包含许多重复的局部模式的观察结果,非局部均值滤波方法已被建议先根据图像非局部自相似性(NSS)进行剖析(参见图2)。 尽管这些简单的启发式操作在产生高质量的修复结果方面能力有限,但这些研究极大地加深了研究人员对自然图像建模的理解。 许多有用的结论和原理仍然适用于现代图像恢复算法设计。
最近,由于机器学习的进步,研究人员提出学习图像降噪的操作。 已经开发了不同的方法来构建在噪声及其对应的清晰图像之间的复杂映射功能[93、74、22]。 由于通过这些方法学习的功能(例如神经网络)通常非常复杂,因此嵌入在这些功能中的先验条件很难进行分析。 结果,针对特定任务(去噪具有不同噪声类型的任务)训练的功能通常不适用于其他恢复任务。 可能需要针对不同的降级参数训练不同的模型。 尽管归纳能力有限,但这些有区别的学习方法所获得的极具竞争力的修复结果使此类方法成为一个活跃而有吸引力的研究主题。
1.2.2 显式方法
除了将先验隐式地嵌入到恢复操作中之外,另一类方法显式地表征图像先验并采用贝叶斯方法来产生高质量的重建结果。 有了退化模型p“ yjx”和特定的先验模型p“ x”,可以使用不同的估计器来估计潜像x。 一种流行的方法是最大后验(MAP)估计量:

考虑到观测值和先验被破坏的情况,我们将使用x寻求最可能的x估计。 与其他估计器相比,MAP估计器通常会导致一种更简单的推理算法,这使其成为用于图像恢复的最常用估计器。 然而,在很少测量的情况下,MAP估计仍然有局限性[81]。 另一种估算器是贝叶斯最小二乘(BLS)估算器:
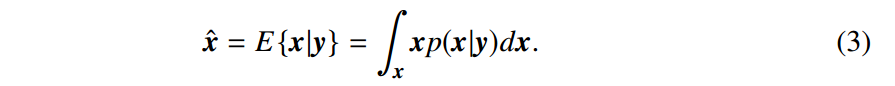
BLS将所有可能的干净图像x的后验概率p“ xjy”边缘化。 从理论上讲,它是根据均方误差的最佳估计,并且该估计器也称为最小均方误差(MMSE)估计器[81]。

广泛的模型,例如独立成分分析(ICA)[5],变分模型[72],字典学习方法[3]和马尔可夫随机场(MRF)[69、34],已被用来表征先验特征。 自然的形象。早期的研究倾向于使用分析数学工具和手动设计的功能形式来分析图像信号,以描述自然图像。 后来的方法倾向于利用训练数据和学习参数来更好地对高质量图像先验建模。 与隐式先验建模方法相比,这些显式先验通常具有更强的泛化能力,并且可以应用于不同的图像恢复应用程序。
这两类现有的建模方法都提供了几种经典的降噪算法。 在图像降噪研究的最开始,隐式方法就占据了主导地位。 已经设计了用于图像去噪的不同的滤波和扩散方法。 自二十年前以来,由于硬件的发展,大量计算资源的可用性以及优化算法的发展,已经提出了稀疏和低秩模型为显式去噪提供先验。 最近,通过基于深度神经网络(DNN)的去噪器获得了最新的去噪结果,该去噪器直接学习了噪点和干净图像之间的映射功能。 退化模型以及隐式图像先验都嵌入网络中。

在本文中,我们按时间顺序回顾了以前的算法。 由于一些经典的基于滤波,扩散和小波的算法已在先前的论文[8]和[61]中进行了全面回顾,因此我们将重点更多地放在最近提出的算法上。 具体而言,我们从基于稀疏的模型开始,然后介绍低秩方法和基于DNN的方法。 在图3中,我们提供了一些代表性降噪方法的时间表。
2 用于图像去噪的稀疏模型
从图像去噪研究的非常早期就已经研究了使用稀疏先验进行去噪的想法。 对图像统计的研究表明,带通滤波器对自然图像响应的边际分布表现出明显的非高斯性和较重的尾巴[33]。 基于上述观察,提出了缩小或优化方法来获得变换域中的稀疏系数。 在过去的几十年中,已经进行了许多尝试来找到更合适的变换域以及用于图像去噪的稀疏度测量。 根据实现代表系数的不同机制,Elad等人。 [31]将稀疏表示模型分为基于分析的方法和基于综合的方法。 在本节中,我们回顾了这两类作品。 此外,由于存在一些同时利用稀疏和非局部自相似先验的最新算法,因此,我们还介绍了这些方法,并展示了如何将稀疏和NSS先验结合起来以实现良好的降噪性能。
2.1 分析稀疏表示模型的图像去噪
分析表示方法使用线性算子以信号乘积表示信号:
其中x是信号矢量,而αa是其分析表示系数。 线性算子P通常被称为分析字典[71]。
一些早期的作品直接采用正交小波基作为字典,并进行收缩运算来稀疏系数。 然后,对稀疏系数进行逆变换以重建去噪估计。 为了获得更好的去噪性能,已经研究了多种小波基和收缩操作。 在[61]中可以找到对基于小波的方法的很好的回顾。
尽管已经从不同的角度设计了复杂的收缩操作,但是这种单步收缩操作不能实现非常好的降噪性能。 建议使用迭代算法以获得更好的结果。在MAP框架下,大多数分析稀疏表示模型都具有类似的形式:

其中![]() 是取决于退化模型的数据保真度项,
是取决于退化模型的数据保真度项,![]() 是将稀疏性强加在滤波器响应Px之前的正则化项。
是将稀疏性强加在滤波器响应Px之前的正则化项。
分析字典P和惩罚函数Ψ„·”在分析稀疏表示模型中起着非常重要的作用。 早期研究利用信号处理和统计工具来分析设计字典和惩罚函数。 基于分析的最著名方法之一是总变化(TV)方法[72],该方法使用Laplacian分布对图像梯度进行建模,从而导致估计图像梯度的标准偏差为'1。 除了电视及其扩展[17、16、14],研究人员还提出了用于分析稀疏表示的小波滤波器[55、10、27]。 在这些方法中,TV方法中的梯度算子被小波滤波器代替,以对图像局部结构进行建模。 除字典外,惩罚功能也得到了很好的研究。 已经引入了不同的统计模型来对自然系数的重尾分布进行建模,从而产生了各种鲁棒的惩罚函数,例如‘p范数[99],归一化稀疏度度量[50]等。
尽管这些分析方法极大地加深了我们对图像建模的理解,但它们被认为过于复杂,无法建模复杂的自然现象。 随着计算能力的提高,已经引入了机器学习方法来学习更好的先验知识。 从概率图像建模的角度来看,Zhu等人。 [97]提出了滤波器,随机场和最大熵(FRAME)框架,该框架表征了滤波器在潜像上的响应分布,从而对图像纹理进行建模。 对于图像降噪,专家领域(FoE)[69]是具有代表性的作品之一,可以学习用于预定义的潜在(惩罚)功能的滤波器(分析字典)。 受FoE启发[69],已经提出了许多方法来从条件随机场(CRF)[77]的角度学习更好的图像去噪滤波器。 已经选择了这些方法中采用的所有潜在函数以导致稀疏系数。 除了从概率的角度来看,还有其他一些建议可以从不同的框架学习分析词典。 Ravishankar等。 [68]提出了变换学习框架,其目的是学习更好的解析稀疏变换的图像恢复。 鲁宾斯坦等。 [71]提出了一种分析-KSVD算法,它借鉴了K-SVD算法[3]的思想,并从图像补丁中学习了分析字典。 所有上述方法都是以生成方式学习图像先验的,训练阶段仅涉及高质量的图像。 最近,歧视性学习方法也已被用来训练特定任务的先验知识[43,21]。通过使用图像对作为训练数据,这些判别性学习方法能够提供极具竞争力的恢复结果。 但是,学习通常是通过解决耗时的双层优化问题来实现的。
2.2 用于图像去噪的综合稀疏表示模型
与分析表示模型不同,合成稀疏表示模型将信号x表示为字典原子的线性组合:

其中![]() 是信号矢量x的合成系数,D是合成字典。 这样的分解模型可能具有不同的αs选择,并且需要进行正则化以提供定义明确的解决方案。 常用的准则是找到稀疏系数向量αs,该向量只能通过D中的几个原子来重构信号。在开创性的工作中[56],Mallat和Zhang提出了一种匹配追踪(MP)算法[56]以找到一个 NPhard稀疏分解问题的近似解。 后来提出了正交MP(OMP)[65]方法,以提高基于合成的建模的性能。 除了限制系数中的非零值(0范数)外,研究人员还建议利用其凸包络-1范数来规范合成系数。 与“ 0范数”相比,可以实现凸“ 1”问题的整体解。 可以使用传统的线性规划求解器或现代方法(例如最小角度回归[30]和近端算法[64] 来解决'1范式稀疏编码问题。
是信号矢量x的合成系数,D是合成字典。 这样的分解模型可能具有不同的αs选择,并且需要进行正则化以提供定义明确的解决方案。 常用的准则是找到稀疏系数向量αs,该向量只能通过D中的几个原子来重构信号。在开创性的工作中[56],Mallat和Zhang提出了一种匹配追踪(MP)算法[56]以找到一个 NPhard稀疏分解问题的近似解。 后来提出了正交MP(OMP)[65]方法,以提高基于合成的建模的性能。 除了限制系数中的非零值(0范数)外,研究人员还建议利用其凸包络-1范数来规范合成系数。 与“ 0范数”相比,可以实现凸“ 1”问题的整体解。 可以使用传统的线性规划求解器或现代方法(例如最小角度回归[30]和近端算法[64] 来解决'1范式稀疏编码问题。
在MAP框架下,基于合成的稀疏表示在图像恢复中的应用非常简单:

其中![]() 是保真度项,并且合成系数αs的正则化
是保真度项,并且合成系数αs的正则化![]() 提供了用于估计清晰图像x的先验信息。 在早期,采用的字典通常是在谐波分析[70]的框架下设计的,例如DCT,小波和Curvelet字典。 然而,这些字典远远不足以对自然图像的复杂结构进行建模,从而限制了图像恢复性能。 为了更好地建模图像中的局部结构,已引入字典学习方法以提高图像恢复性能[3]。 代表性的作品之一是K-SVD算法,Aharon等。 [3]提出从高质量图像中学习字典,并利用学习到的字典进行图像去噪。 配备了学到的字典后,综合稀疏表示框架已带来了最新的去噪结果。 除了对字典学习的研究外,研究人员还进行了许多尝试,以设计强大的正则化函数
提供了用于估计清晰图像x的先验信息。 在早期,采用的字典通常是在谐波分析[70]的框架下设计的,例如DCT,小波和Curvelet字典。 然而,这些字典远远不足以对自然图像的复杂结构进行建模,从而限制了图像恢复性能。 为了更好地建模图像中的局部结构,已引入字典学习方法以提高图像恢复性能[3]。 代表性的作品之一是K-SVD算法,Aharon等。 [3]提出从高质量图像中学习字典,并利用学习到的字典进行图像去噪。 配备了学到的字典后,综合稀疏表示框架已带来了最新的去噪结果。 除了对字典学习的研究外,研究人员还进行了许多尝试,以设计强大的正则化函数![]() ,以便为恢复提供更好的先验[13]。
,以便为恢复提供更好的先验[13]。
可以从不同的角度解释合成的稀疏表示模型。 Zoran等。 [98]和Yu等。 [90]提出利用高斯模型的混合来模拟自然图像补丁的先验。 Yu等。 [90]分析了高斯模型和组稀疏模型的混合之间的关系,并表明选择高斯分布可以被称为特殊的组稀疏约束。
2.3 NSS之前的稀疏模型
除了独立工作以捕获图像局部先验,稀疏模型还与其他自然图像先验相结合,以追求更好的降噪性能。 通过收集非局部相似补丁并在3D块上进行协作过滤,块匹配和3D过滤(BM3D)算法[25]实现了最新的降噪性能。 BM3D启发的后续工作取得了巨大成功,将稀疏的先验和NSS的先验相结合。 Mairal等。 [54]收集非本地相似补丁并解决组稀疏性问题以获得更好的去噪效果。 董等。 [28]提出了一种非局部集中式稀疏表示模型,其中,基于补丁组对表示系数的平均值进行了预估计。
3 低阶图像去噪模型
除了先对信号矢量采用稀疏性之外,还提出了低秩模型来利用相关矢量矩阵的稀疏性(即,低秩)。 低秩矩阵逼近(LRMA)旨在从退化的观测中恢复底层的低秩矩阵。 它在计算机视觉的各种应用中都取得了巨大的成功[11,12,73,39,96]。
低等级模型也已成功地应用于图像恢复问题[82、48、63、39]。 一些研究[92,48]将低等级作为全局先验,并将图像恢复直接视为LRMA问题。 但是,这种假设太强了,不能反映自然图像的特征。 结果,那些基于全局低优先级的方法只能在具有特殊内容的图像上执行良好,并且它们会使自然图像中的细节过分平滑。 对于去噪的任务,Hui等。 [48]首先在视频数据上应用了低秩模型。 在对向量进行矢量化后,从不同帧中的相同空间位置收集图像补丁,并以矩阵形式形成补丁组,[48]寻求低秩近似来生成降噪的补丁组。 为了处理低秩先验的单图像降噪问题,[82,39,88]利用了NSS先验。这些方法收集非局部自相似补丁,并进行低秩近似来估计相应的干净补丁。 为了从补丁组生成良好的低秩估计,Gu等人。 [41]提出了一个加权核规范最小化(WNNM)模型来自适应调整矩阵的奇异值。 WNNM模型实现了最先进的降噪性能。
受WNNM的启发,谢等。 [88]提出了一个加权的Schatten p-Norm最小化模型进行图像去噪。 谢等。 [87]将矩阵的二维低秩模型扩展到高维张量模型,提出了一种新的张量数据正则化器,并在多光谱图像去噪任务上实现了最新的性能。 徐等。 [89]提出了一种多通道WNNM模型来解决实际的彩色图像降噪问题,该模型使不同的彩色通道具有不同的噪声水平。
4 用于图像去噪的深度神经网络
在过去的几年中,深度神经网络(DNN)在各种计算机视觉任务上都取得了巨大的成功。 还提出了DNN来解决图像去噪问题。
用深度神经网络进行图像去噪的最早尝试之一是[47]。 在[47]中,Jain和Seung提出了一个小型卷积神经网络来处理图像去噪问题。 该网络只有4个隐藏层,每个层仅利用24个特征图。 网络通过FoE [69]方法获得可比的结果。 在[86]中,谢等人。 堆叠两个稀疏去噪自动编码器进行图像去噪。 将经过预训练的稀疏去噪自动编码器组合在一起,并采用LBFGS算法[53]以端到端的方式微调网络。 在[75]中,舒勒等人。 训练了多层感知器(MLP)进行图像降噪。 MLP是第一个通过基线BM3D方法获得可比的去噪性能的网络[25]。 MLP之后,Schmidt等人。 [74](CSF方法)和Chen等。 [20](TNRD方法)提出了基于优化的去噪模型的推理过程,并以端对端的方式训练去噪网络。 CSF和TNRD用最新的WNNM方法获得了可比的去噪性能。

自2012年以来,卷积神经网络在图像分类任务[51]上取得的巨大成功引起了对深度学习研究的兴趣。在神经网络训练算法,深度学习工具箱和硬件设备方面已经取得了巨大的进步。 这一进展促进了基于DNN的去噪算法的研究。 张等。 [93]堆叠卷积,批归一化[46]和ReLU [62]层来估计噪声输入和相应的干净图像之间的残差。 他们的DnCNN网络不仅在标准基准上实现了比稀疏和低秩模型更高的PSNR指数,而且比以前的基于优化的方法要快得多。 受到DnCNN成功的启发,Mao等人。 提出了一种非常深的残差编码解码(RED)框架来解决图像恢复问题,其中引入了跳过连接来训练非常深的网络。 最近,Tai等。 [76]提出了一种非常深的持久存储网络(MemNet)用于图像去噪。 已经采用递归单元和门单元来学习不同接受领域下的多层次表示。 RED方法[57]和MemNet [76]改善了DnCNN [93]的去噪性能,但对计算资源也有更高的要求。 在[38]中,Gu等人。 提出了快速降噪网络(FDnet)以在降噪性能和速度之间寻求更好的折衷。 通过合并更强大的激活功能,例如 在网络中的多仓可训练线性单元(MTLU)中,FDnet能够以较少的计算资源生成可比的去噪结果。

5 图像降噪:实际问题
在本节中,我们回顾了一些图像去噪研究的实用实验方案。 我们首先介绍常用的实验设置以及用于评估降噪算法的度量。 然后,通过一些有代表性的算法报告性能。
5.1 图像降噪的实验设置
以前的大多数算法都是根据综合数据进行评估的。 给定干净的图像,将具有不同σ的AWGN添加到图像中以合成噪声输入。然后,在执行去噪算法之后,可以使用不同的度量来评估去噪估计的质量,
直到最近,还没有一个公认的基准数据集来评估降噪算法。 大多数早期研究在一对图像上报告了它们的算法,例如,图1所示的Lena图像。一些常用的图像如图5所示。人们可以看到,大多数以前的算法都是为灰度图像去噪而设计的。 据我们所知,FoE [69]论文首先利用了来自伯克利分割数据集[58]的68张测试图像来评估去噪算法。 68图像数据集逐渐成为评估降噪算法的基准,最近提出的大多数算法都在Set 68数据集上报告了它们的性能。 除了测试图像,评估降噪算法的另一个重要实验设置是噪声。 尽管算法被设计为处理所有被AWGN损坏的图像,但是噪声实例仍会影响降噪性能。 为了公平比较,以前的算法在使用Matlab生成合成输入图像时将噪声种子设置为0。 设置相同的噪声种子可确保不同算法的输入噪声图像相同。
最近,已经准备了一些基准来评估现实世界中去噪任务的去噪算法性能[67,1]。 为现实世界中的去噪问题建立基准的主要挑战在于难以获得成对的噪点和清晰图像。 为了解决这个问题,已经采用了不同的平均方法和精心设计的后处理方法来评估来自多次拍摄的干净参考图像[67,1]。 其他基准测试则考虑了由噪声,模糊和下采样算子的组合所导致的清晰图像的恢复[79]。
5.2 去噪算法的测量
去噪算法的目标是从嘈杂的观察中恢复潜在的干净图像。 为了评估去噪算法,已采用不同的测量方法来比较去噪估计和地面真实高质量图像。最常用的测量是峰值信噪比(PSNR)指数。 通过均方误差(MSE)最容易定义PSNR。 给定地面真实图像G和去噪估计E,MSE定义为:

其中E„![]() 是位置(m,n)处的像素值; 图像E和G分别为n”,M和N为图像大小。 基于MSE,PSNR的定义为:
是位置(m,n)处的像素值; 图像E和G分别为n”,M和N为图像大小。 基于MSE,PSNR的定义为:

其中R是图像数据类型中的最大波动。 尽管大量工作指出,PSNR并不是衡量两个图像之间感知相似度的理想选择,但它仍然是比较两个图像的最常用指标。
除了MSR和PSNR,还提出了感知质量测量来评估降噪算法。 代表性测量之一是结构相似性(SSIM)指数[83]。 SSIM索引是在图像的各个窗口上计算的。 两个窗口x和y之间的度量为:

µx和µy分别是窗口x和y的平均值。 σx和σy是x和y的方差,而σxy是x和y的协方差。 ![]() 是用于稳定分母弱的两个变量,其中k1和k2默认设置为0.01和0.03,R是等式中定义的动态范围。
是用于稳定分母弱的两个变量,其中k1和k2默认设置为0.01和0.03,R是等式中定义的动态范围。
SSIM及其扩展[94]已广泛应用于不同的任务,以比较估计的和真实的图像。 对于图像去噪任务,在某些工作中也采用了特征结构相似度(FSIM)[94]。 最近,Zhang等人。 [95]提出了基于深度特征的学习知觉图像补丁相似度(LPIPS)度量。 然而,所有上述感知质量度量仅是基于来自人类受试者的等级获得的平均意见得分(MOS)的代理。 最近在感知图像超分辨率[6],图像增强[45]和学习图像压缩(CLIC在CVPR 2018上)方面的挑战依靠MOS进行排名。
5.3 代表性算法的去噪性能
在这一部分中,我们将通过Set 68数据集上的不同方法给出去噪结果,以供参考。 请注意,近年来,其他数据集也越来越流行,例如Set5,Set14,B100,Urban100或DIV2K数据集[2],这些数据集更常用于基准图像超分辨率算法。 这些数字是从最近发表的去噪纸中获得的[93]。 如表1所示,判别式学习方法TNRD [20]和DnCNN [93],通常比BM3D [25],EPLL [98]和WNNM [ 41]。 此外,基于深度神经网络的方法DnCNN获得了比其他模型更好的性能。
表2中显示了通过不同方法处理512×512图像的运行时间。数字也来自DnCNN论文,该论文采用了配备Intel®Core™i7-5820K 3.30GHz CPU和Nvidia的PC Titan X GPU可以测试不同的算法。 通常,由于基于判别学习的方法不需要在推理阶段解决优化问题,因此与基于优化的方法相比,它们在运行速度上取得了很大的进步。 此外,最近提出的一些算法非常适合在GPU上进行并行计算,通过使用GPU可以大大减少其运行时间。
在图6中可以找到通过不同方法进行去噪结果的一些直观示例。
6 新兴话题和开放性问题
尽管在标准基准上实现了基于DNN的去噪方法的良好性能,但是仍然存在一些开放问题,这些问题可能在基于DNN的去噪在实际系统中的应用中发挥非常重要的作用。 在过去的几年中,已经进行了一些尝试来改善去噪系统的性能,以便更好地适合实际应用。 在本节中,我们讨论图像去噪领域中的一些新兴主题和未解决的问题。
图像去噪的目标是提高噪声输入的质量。 去噪和潜在地面真值之间计算出的像素级逼真度度量(例如RMSE和PSNR)被广泛用于评估去噪结果。 但是,这些措施不能很好地适应人类的视觉系统,具有高PSNR指数的估计值可能并不总是意味着视觉上令人愉悦的降噪结果。 为了提高去噪图像的感知质量,常规方法提出在优化过程中增加额外的约束,从而在去噪结果中保留更多的纹理细节。 例如,Cho等。 [23]利用超拉普拉斯模型对图像梯度进行建模,并提出了一种内容感知先验,该方法在不同图像区域中设置了梯度分布的不同形状参数。 尽管[23]的最初想法是针对图像去噪任务提出的,但它启发了Zuo等人。 [100]提出了一种用于图像去噪的梯度直方图保存算法。Zuo等。 [100]利用AWGN的统计特性,并从其嘈杂的观测值中预先估计出干净图像的梯度直方图,然后添加一个梯度直方图约束以在降噪结果中保留更多纹理细节。 对于基于DNN的方法,去噪估计是直接从噪声输入中生成的,在目标上添加约束并不容易。 改善视觉质量的直接方法是使用更好的与人类感知相关的损失函数来训练去噪网络。 在图像超分辨率领域,已经提出了各种各样的损失来训练CNN以实现更好的视觉质量。 约翰逊等。 [49]建议使用目标图像和估计图像的VGG特征之间的'2距离来训练神经网络,并声称与图像域中的常规'2或'1距离相比,它有助于在视觉上产生更令人愉悦的结果。 启发式对抗网络(GAN)在图像先验建模中取得了巨大的成功[36]。 [52]在超分辨率网络的训练中增加了GAN损失,并且比RMSE损失获得了更好的视觉质量。 尽管上述损失是针对其他图像恢复任务提出的,但它们也可用于改善去噪网络的视觉质量[18]。 由于损失函数极大地影响着去噪网络的行为,因此找到一种很好的损失函数非常适合人类的视觉系统是一个非常有趣且有前途的研究课题。
除了寻求更好的损失函数外,另一个有趣的问题是以弱监督或无监督的方式训练去噪网络。 由于成像系统中的噪声模型非常复杂,因此要从高质量图像中合成真实的噪点图像是一个具有挑战性的问题。 我们可能无法获取包含真实噪声图像及其相应的高质量图像的配对训练图像来训练去噪网络。 当前的大多数降噪网络都遵循AWGN去除的实验设置,通过向干净图像添加噪声来合成噪声输入。 尽管这些网络在标准基准上获得了极高的竞争性能,但最近的研究[67]发现基于DNN的方法不如BM3D [25]和WNNM [41]等传统方法好,适用于16 Shuhang Gu和Radu Timofte处理。 真实的噪点图像。 为了解决这个问题,一个可能的方向是改善去噪神经网络的泛化性能,并使在合成数据上训练的神经网络能够在真实数据上表现良好。 郭等。 [42]提出了卷积盲去噪网络(CBDNet)。 CBDNet由噪声估计子网和降噪子网组成,并通过考虑信号相关的噪声和相机内处理流水线,使用更现实的噪声模型进行训练。 另一种有趣的方式是研究弱监督的训练策略,该策略不依赖于成对的训练数据来训练降噪网络。 以前,Ignatov等人。 文献[44]提出了一种WESPE方法,该方法可以训练仅包含两组图像的图像增强网络,即 低质量图像和高质量图像。 但是,目前在以弱监督的方式训练去噪网络方面仍然没有成功的工作。 如何从未配对的嘈杂和干净的图像中受益以进行降噪网络训练仍然是一个悬而未决的问题。
7 结论
在这篇简短的综述中,我们主要关注解决加性高斯白噪声情况的图像去噪文献,指出了该领域几十年来的巨大进步,并深入探讨了最新文献和相关内容。 深度学习方法的问世。 在回顾了当前的最新技术之后,我们超越了范围,确定了图像降噪社区应邀回答的几个挑战和开放方向。