Centos Linux上安装hadoop为伪布式详细过程(小白必读)
一 准备工具(下载地址已附上)
本次安装所需要的工具:
1.Linux版本:VMware-Workstation Centos6
(以下蓝色字体为超链接,直接点击即可跳转)
2.hadoop版本2.7.1:提取码:sxy0
hadoop版本:hadoop-2.7.1 64位,Linux版本,文件大小200M左右
3.jdk版本1.8.0_11 提取码:g822
Java版本:jdk1.8.0_11,64位,Linux版本,文件大小150M左右
二 上传文件到Linux
关于这步中最核心的如何连接文件传输协议–Xshll6?
我已发布了有关博客文章,附上链接:
如何传文件到虚拟机上
三 配置前的准备工作
(建议大家可以自行去百度查找,安装vm-tools 工具,这样可以方便复制window上的文本复制粘贴到Linux上)
1.首先进入到root超级用户,方便操作
su root
2.关闭防火墙以及永远关闭
不知道本机的防火墙是否关闭的可以用命令 service iptables status 查看ip状态,如若没关闭,则使用命令
service iptables stop
chkconfig iptables off
第一个是暂时关闭防火墙,重启失效,第二个永久关闭防火墙,两者配合使用永久关闭
3.配置hadoop主机的用户配置,以及免密设置
修改方便记忆跟操作的主机名,我们需要设置主机名
执行:
vim /etc/sysconfig/network
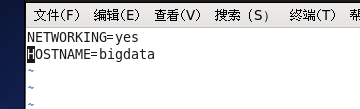
找到HOSTNAME改等号后面就可以改你想改的主机名称了
但是这种方式更改主机名需要重启才能永久生效,因为主机名属于内核参数
我们可以直接:
hostname bigdata
这样,我们先配置 /etc/sysconfig/network文件,然后在命令行输入命令,就可以达到不重启或重启都是主机名都是同一个的目的
查看主机名映射的ip地址
ifconfig

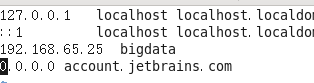
记住这里的ip地址:192.168.65.25,这个是主机名的ip映射地址,待会配置文件要用到 ( 具体的ip看你显示什么,如果没有显示可以参考最上面第二步上传文件到Linux链接)
默认的主机名是localhost,为了防止混淆,把192.168.65.25映射的localhost改成刚才的设置的主机名,我们可以修改 /etc/hosts 下的主机名,直接使用:
vim /ect/hosts
进入后添加刚才的IP地址,主机名,之间空一格,参考下面图片设置
成:bigdata
4.设置免密登录
因为伪分布式的主机节点登录需要自己输入当前用户密码登录,所以为了方便,我们需要设置免密
输入命令:
ssh-keygen
然后一直按回车

他会生成节点的公钥和私钥,生成的文件会自动放在/root/.ssh目录下
因为是伪分布式,所以我们不用复制这个密匙登录到其他机器
直接用:
拷贝那个自动生成的公钥跟密钥
ssh-copy-id root@bigdata

出现上面信息就完成了bigdata这个主机的免密登录了
5.解压jdk跟hadoop到指定目录(这个目录看自己设置的)
因为我的用户登录时haigui,所以我把他们都放在/home/haigui/下,方便待会设置环境变量
使用命令:
找到你上传的jdk跟hadoop压缩包的目录
tar -xf ./jdk-8u11-linux-x64.tar.gz /home/haigui
tar -xf ./hadoop-2.7.1_64bit.tar.gz /home/haigui
然后我为了方便,把这两个名字改成了hadoop,jdk,如图

6.配置java即jdk环境变量
把刚才解压的jdk配置他的环境变量
首先我们先编辑环境变量系统文件:
vim /etc/profile
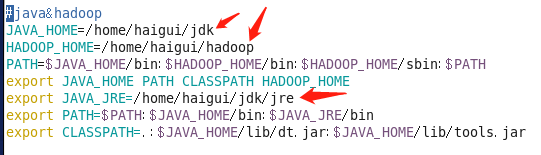
(因为我这里的文件路径为/home/haigui/下,只要有关于这路径的,大家都需要改成自己jdk跟hadoop实际的路径,有箭头标识的就要改)
因为我已经安装好了伪分布式hadoop,因此这里有了后面需要配置的hadoop环境变量,为了方便大家,大家可直接复制粘贴
#java&hadoop
JAVA_HOME=/home/haigui/jdk
HADOOP_HOME=/home/haigui/hadoop
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
export JAVA_JRE=/home/haigui/jdk/jre
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_JRE/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
配置完这个文件后,我们用:
source /etc/profile
使这个文件立即生效
7.使用命令,检查是否配置完毕
jdk:
java -version

hadoop:
hadoop versions
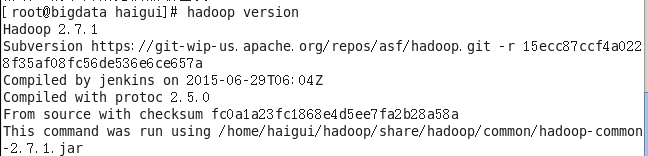
出现上面的信息,表示安装配置jdk跟hadoop成功啦!
接下来,配置hadoop核心配置文件啦.
四 配置核心文件(重点)
1.说明配置文件的一些注意事项
hadoop的核心配置文件都在 /home/haigui/hadoop/etc/hadoop/ 下,如果没有特别说明,所以下面所有配置文件都要进这个 /home/haigui/hadoop/etc/hadoop/ .(这个目录是自己设置hadoop目录)
bigdata 这个主机名,是你在上面自己设置的主机名
2.配置 hadoop-env.sh(在/hadoop/etc/hadoop/下,以下几步的文件都是)
编辑这个文件:
vim hadoop-env.sh
为了方便查找我们要改的信息,在命令行模式,输入 :se nu 显示行号
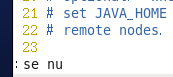
然后找到25行,跟33行改成所对应的jdk目录,跟hadoop目录(注意这里是hadoo目录后面还有/ect/hadoop),具体看下图。

保存并退出
然后执行:
source hadoop-env.sh
让配置文件立即生效
3.编辑 core-site.xml
首先在hadoop目录下:/home/haigui/hadoop/ ,创建一个新的“tmp”目录
编辑这个文件:
vim core-site.xml
注意下面的箭头标识的地方:
第一个箭头:
bigdata是你上面设置的主机名
第二个箭头:
写上这个“tmp”这个目录的路径
如图:

在文件最下面添加下面的(新的这个文件,应该是只有跟的,你需要做添加2个property节点,里面放配置文件)
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://bigdata:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/haigui/hadoop/tmp</value>
</property>
</configuration>
保存并退出
4.编辑 hdfs-site.xml
vim hdfs-site.xml
按照第二步的照着抄:

<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
保存并退出
5.编辑 mapred-site.xml
这个文件初始时是没有的,但是有一个模板文件,mapred-site.xml.template
所以需要拷贝一份,并重命名为mapred-site.xml,使用命令:
(需要进入到/home/haigui/hadoop/etc/hadoop
cp ./mapred-site.xml.template ./mapred-site.xml
然后编辑打开 mapred-site.xml
vim mapred-site.xml

直接复制:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
保存并退出
6.编辑 yarn-site.xml
编辑打开:
vim yarn-site.xml

箭头标识:
bigdata是你上面设置的主机名
直接复制:
<configuration>
<property>
<!--指定yarn的老大 resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>:
<value>bigdata</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
最后保存退出
7.编辑slaves文件
vim slaves
直接在最上面写上你上面自己设置的主机名。
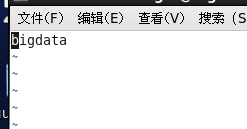
保存并退出
到这里,我们就配置完了hadoop核心文件了,基本上就配置好了,接下来是启动跟实例测试。
五 查看及启动
1.用命令 jps 查看在线的工作节点
jps

我们可以看到没有启动hadoop,是没有任何节点在线的
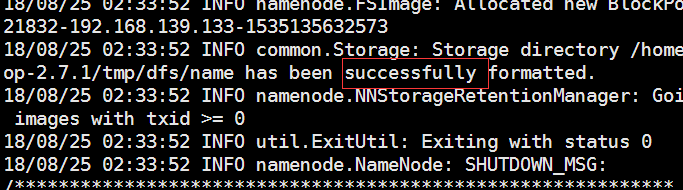
2.格式化namenode
在第一次安装hadoop的时候,需要对namenode进行格式化,以后请不要随便在去用这个命令格式化namenode
hadoop namenode -format
只要出现 successfully则表明格式化成功。
3. 启动hadoop
因为我们已经配置hadoop的环境变量了,所以不要在sbin 目录下启动,在任何目录下直接用这个命令都能启动hadoop
直接使用这个命令
start-dfs.sh
(这个命令是启动hdfs的,还有一个命令对应的是启动yarn:start-yarn.sh),假如想完全启动hadoop,可以直接输入:start-start.sh,启动hdfs跟yarn)
以后出现:WARN util.NativeCodeLoader:…警告的信息的不用管它,直接忽略就行了

然后在jps查看:
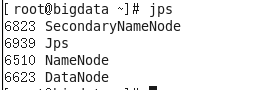
出现上面这些说明hadoop伪分布式配置好了。
4…打开浏览器输入 http://bigdata:50070
查看能成功打开 namenode状态信息

网页并且能打开
六 实例测试
既然已经装好了hadoop了,那么我们来试试官方给出的wordcount实例操作一下,感受hadoop的强大吧。
1.创建一个本地文件1.txt:
目录我选择为:/home/haigui/1.txt
输入命令:
vim 1.txt
输入下面内容:

i like hadoop
and i like study
i like java
i like jdk
i like java jdk hadoop
保存并退出
2.上传到hdfs文件系统上
我的1.txt是在/home/haigui/下

首先先在hdfs的根目录下创建一个input目录,使用命令:
hdfs dfs -mkdir /input

然后上传到hdfs上:(确保你当前的路径在/home/haigui下)
hdfs dfs -put ./1.txt /input

然后查看是否成功上传:
hdfs dfs -ls /input

看到这里说明成功上传了。
3.使用命令让hadoop工作
在上面的启动hadoop中,我们只启动hdfs,没有启动yarn,因此我们先使用命令启动yarn:
start-yarn.sh

然后直接使用命令:
hadoop jar ./hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input /output

我们看到hadoop已经跑起来了,最后的successful代表工作成功!
4.查看输出结果
hadoop工作成功后会自己在指定路径/output 生成两个文件
我们看一下
hdfs dfs -ls /output

第一个文件/output/_SUCCESS:是表示工作成功的文件,没有具体的文本,这个我们忽略
第二个文件/output/part-r-00000:才是我们真正的输出文件
查看一下结果:
hdfs dfs -cat /output/part-r-00000
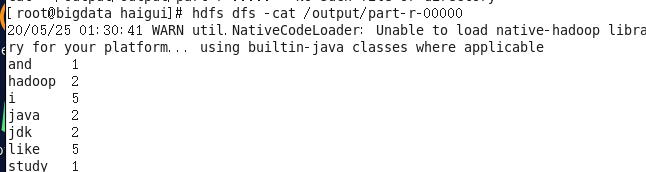
最后得出了每个单词出现的次数
5.介绍该实例
上面那个命令 中下面的路径:
./hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar
其实是hadoop里面的官方实例的路径,如图:

wordcount 是说使用这个命令去统计danc
/input 是hadoop工作输入的路径
/output是hadoop工作输出的路径(这个路径不能率先存在)