测试题:参考博文
作业1:建立你的循环神经网络
RNN 模型对序列问题(如NLP)非常有效,因为它有记忆,能记住一些信息,并传递至后面的时间步当中
- 导入一些包
import numpy as np
from rnn_utils import *
1. RNN 前向传播
这是一个基本的RNN模型,其输入输出等长
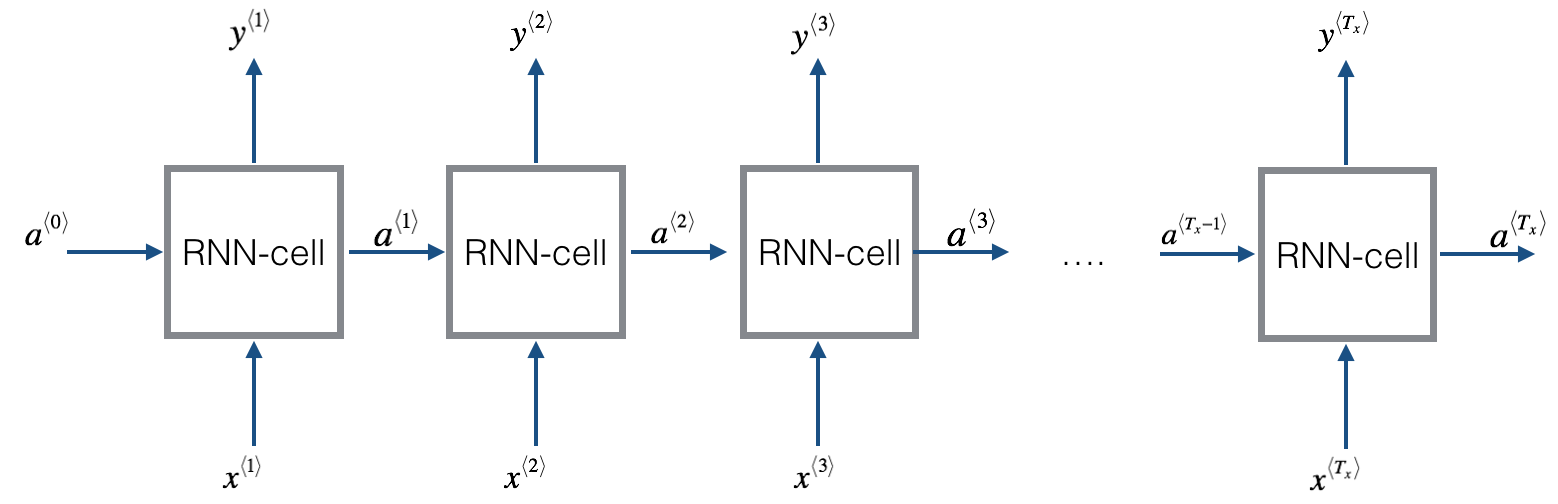
1.1 RNN 单元
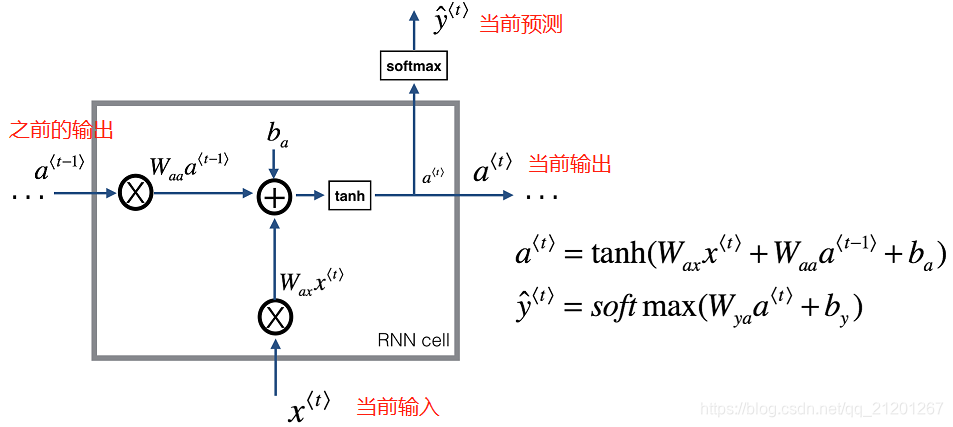
# GRADED FUNCTION: rnn_cell_forward
def rnn_cell_forward(xt, a_prev, parameters):
"""
Implements a single forward step of the RNN-cell as described in Figure (2)
Arguments:
xt -- your input data at timestep "t", numpy array of shape (n_x, m).
a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m)
parameters -- python dictionary containing:
Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
ba -- Bias, numpy array of shape (n_a, 1)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
Returns:
a_next -- next hidden state, of shape (n_a, m)
yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m)
cache -- tuple of values needed for the backward pass, contains (a_next, a_prev, xt, parameters)
"""
# Retrieve parameters from "parameters"
Wax = parameters["Wax"]
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
### START CODE HERE ### (≈2 lines)
# compute next activation state using the formula given above
# 按公式写即可
a_next = np.tanh(np.dot(Wax, xt)+np.dot(Waa, a_prev)+ba)
# compute output of the current cell using the formula given above
yt_pred = softmax(np.dot(Wya, a_next)+by)
### END CODE HERE ###
# store values you need for backward propagation in cache
cache = (a_next, a_prev, xt, parameters)
return a_next, yt_pred, cache
1.2 RNN 前向传播
把上面的单元重复n次,前一个输出,作为下一个单元的输入
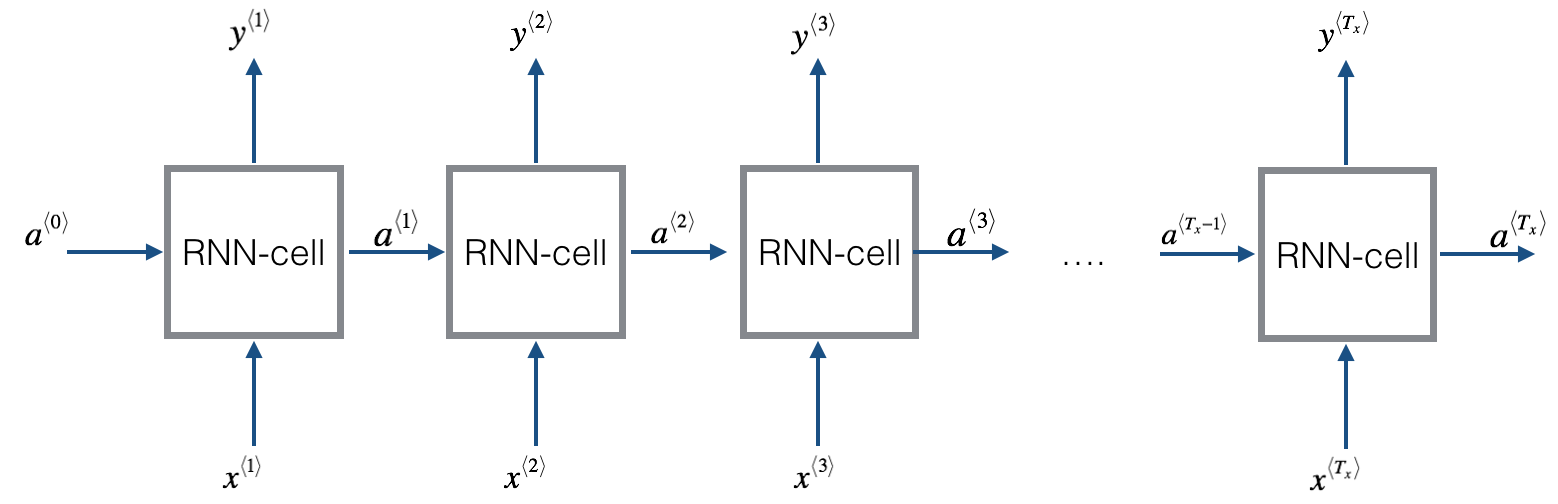
# GRADED FUNCTION: rnn_forward
def rnn_forward(x, a0, parameters):
"""
Implement the forward propagation of the recurrent neural network described in Figure (3).
Arguments:
x -- Input data for every time-step, of shape (n_x, m, T_x).
a0 -- Initial hidden state, of shape (n_a, m)
parameters -- python dictionary containing:
Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
ba -- Bias numpy array of shape (n_a, 1)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
Returns:
a -- Hidden states for every time-step, numpy array of shape (n_a, m, T_x)
y_pred -- Predictions for every time-step, numpy array of shape (n_y, m, T_x)
caches -- tuple of values needed for the backward pass, contains (list of caches, x)
"""
# Initialize "caches" which will contain the list of all caches
caches = []
# Retrieve dimensions from shapes of x and Wy
n_x, m, T_x = x.shape
n_y, n_a = parameters["Wya"].shape
### START CODE HERE ###
# initialize "a" and "y" with zeros (≈2 lines)
a = np.zeros((n_a, m, T_x))
y_pred = np.zeros((n_y, m, T_x))
# Initialize a_next (≈1 line)
a_next = a0
# loop over all time-steps
for t in range(T_x):
# Update next hidden state, compute the prediction, get the cache (≈1 line)
a_next, yt_pred, cache = rnn_cell_forward(x[:,:,t], a_next, parameters)
# Save the value of the new "next" hidden state in a (≈1 line)
a[:,:,t] = a_next
# Save the value of the prediction in y (≈1 line)
y_pred[:,:,t] = yt_pred
# Append "cache" to "caches" (≈1 line)
caches.append(cache)
### END CODE HERE ###
# store values needed for backward propagation in cache
caches = (caches, x)
return a, y_pred, caches
上面的模型存在梯度消失的问题,预测值是根据局部信息来预测的
下面我们建立更复杂的 LSTM 模型,它可以更好的解决梯度消失问题,它可以记住一些信息,并在后序很多步中保留
2. LSTM 网络
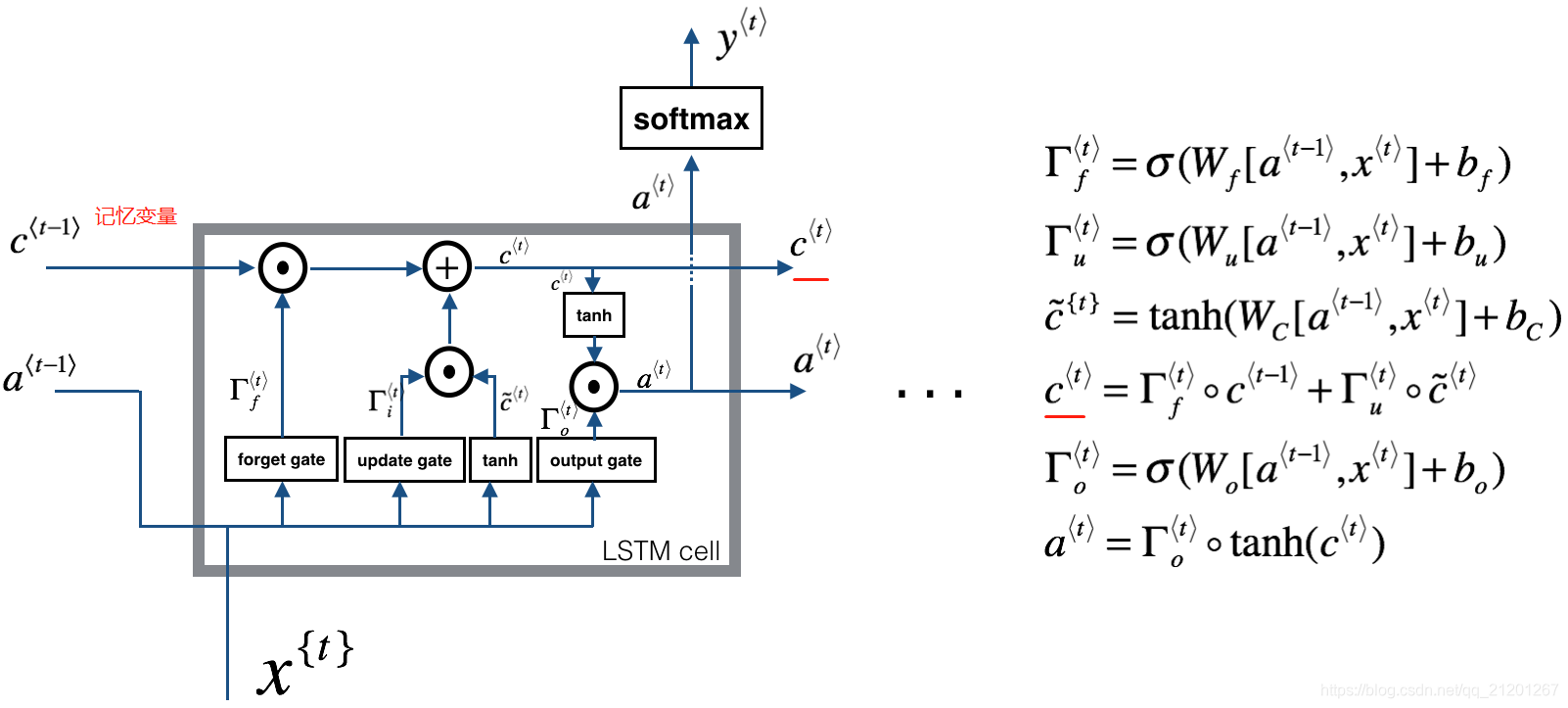
- forget 门, Γ f < t > ∈ ( 0 , 1 ) \Gamma_f^{<t>} \in (0,1) Γf<t>∈(0,1),等于0,就是忘记该信息
Γ f ⟨ t ⟩ = σ ( W f [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b f ) \Gamma_f^{\langle t \rangle} = \sigma(W_f[a^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_f) Γf⟨t⟩=σ(Wf[a⟨t−1⟩,x⟨t⟩]+bf) - update 门,是否更新当前的信息至记忆
Γ u ⟨ t ⟩ = σ ( W u [ a ⟨ t − 1 ⟩ , x { t } ] + b u ) \Gamma_u^{\langle t \rangle} = \sigma(W_u[a^{\langle t-1 \rangle}, x^{\{t\}}] + b_u) Γu⟨t⟩=σ(Wu[a⟨t−1⟩,x{ t}]+bu) - 更新单元
c ~ ⟨ t ⟩ = tanh ( W c [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b c ) \tilde{c}^{\langle t \rangle} = \tanh(W_c[a^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_c) c~⟨t⟩=tanh(Wc[a⟨t−1⟩,x⟨t⟩]+bc)
c ⟨ t ⟩ = Γ f ⟨ t ⟩ ∗ c ⟨ t − 1 ⟩ + Γ u ⟨ t ⟩ ∗ c ~ ⟨ t ⟩ c^{\langle t \rangle} = \Gamma_f^{\langle t \rangle}* c^{\langle t-1 \rangle} + \Gamma_u^{\langle t \rangle} *\tilde{c}^{\langle t \rangle} c⟨t⟩=Γf⟨t⟩∗c⟨t−1⟩+Γu⟨t⟩∗c~⟨t⟩
- output 门
Γ o ⟨ t ⟩ = σ ( W o [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b o ) \Gamma_o^{\langle t \rangle}= \sigma(W_o[a^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_o) Γo⟨t⟩=σ(Wo[a⟨t−1⟩,x⟨t⟩]+bo)
a ⟨ t ⟩ = Γ o ⟨ t ⟩ ∗ tanh ( c ⟨ t ⟩ ) a^{\langle t \rangle} = \Gamma_o^{\langle t \rangle}* \tanh(c^{\langle t \rangle}) a⟨t⟩=Γo⟨t⟩∗tanh(c⟨t⟩)
2.1 LSTM 单元
# GRADED FUNCTION: lstm_cell_forward
def lstm_cell_forward(xt, a_prev, c_prev, parameters):
"""
Implement a single forward step of the LSTM-cell as described in Figure (4)
Arguments:
xt -- your input data at timestep "t", numpy array of shape (n_x, m).
a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m)
c_prev -- Memory state at timestep "t-1", numpy array of shape (n_a, m)
parameters -- python dictionary containing:
Wf -- Weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
bf -- Bias of the forget gate, numpy array of shape (n_a, 1)
Wi -- Weight matrix of the save gate, numpy array of shape (n_a, n_a + n_x)
bi -- Bias of the save gate, numpy array of shape (n_a, 1)
Wc -- Weight matrix of the first "tanh", numpy array of shape (n_a, n_a + n_x)
bc -- Bias of the first "tanh", numpy array of shape (n_a, 1)
Wo -- Weight matrix of the focus gate, numpy array of shape (n_a, n_a + n_x)
bo -- Bias of the focus gate, numpy array of shape (n_a, 1)
Wy -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
Returns:
a_next -- next hidden state, of shape (n_a, m)
c_next -- next memory state, of shape (n_a, m)
yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m)
cache -- tuple of values needed for the backward pass, contains (a_next, c_next, a_prev, c_prev, xt, parameters)
Note: ft/it/ot stand for the forget/update/output gates, cct stands for the candidate value (c tilda),
c stands for the memory value
"""
# Retrieve parameters from "parameters"
Wf = parameters["Wf"]
bf = parameters["bf"]
Wi = parameters["Wi"]
bi = parameters["bi"]
Wc = parameters["Wc"]
bc = parameters["bc"]
Wo = parameters["Wo"]
bo = parameters["bo"]
Wy = parameters["Wy"]
by = parameters["by"]
# Retrieve dimensions from shapes of xt and Wy
n_x, m = xt.shape
n_y, n_a = Wy.shape
### START CODE HERE ###
# Concatenate a_prev and xt (≈3 lines)
concat = np.concatenate((a_prev, xt), axis=0)
concat[: n_a, :] = a_prev
concat[n_a :, :] = xt
# Compute values for ft, it, cct, c_next, ot, a_next using the formulas given figure (4) (≈6 lines)
ft = sigmoid(np.dot(Wf, concat)+bf) # forget 门
it = sigmoid(np.dot(Wi, concat)+bi) # update 门
cct = np.tanh(np.dot(Wc, concat)+bc)
c_next = ft*c_prev + it*cct
ot = sigmoid(np.dot(Wo, concat)+bo) # output 门
a_next = ot*np.tanh(c_next)
# Compute prediction of the LSTM cell (≈1 line)
yt_pred = softmax(np.dot(Wy, a_next)+by)
### END CODE HERE ###
# store values needed for backward propagation in cache
cache = (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters)
return a_next, c_next, yt_pred, cache
2.2 LSTM 前向传播
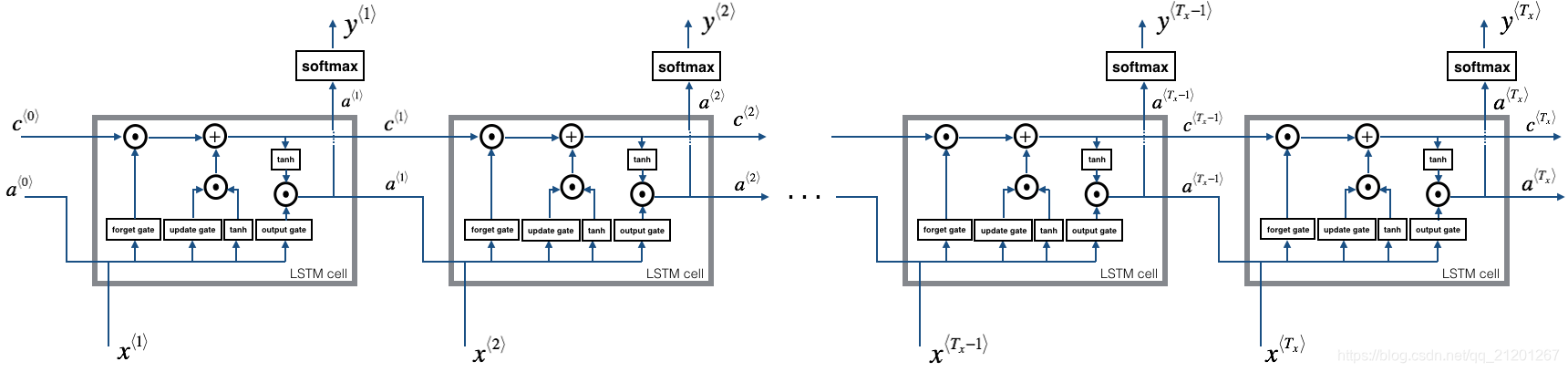
# GRADED FUNCTION: lstm_forward
def lstm_forward(x, a0, parameters):
"""
Implement the forward propagation of the recurrent neural network using an LSTM-cell described in Figure (3).
Arguments:
x -- Input data for every time-step, of shape (n_x, m, T_x).
a0 -- Initial hidden state, of shape (n_a, m)
parameters -- python dictionary containing:
Wf -- Weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
bf -- Bias of the forget gate, numpy array of shape (n_a, 1)
Wi -- Weight matrix of the save gate, numpy array of shape (n_a, n_a + n_x)
bi -- Bias of the save gate, numpy array of shape (n_a, 1)
Wc -- Weight matrix of the first "tanh", numpy array of shape (n_a, n_a + n_x)
bc -- Bias of the first "tanh", numpy array of shape (n_a, 1)
Wo -- Weight matrix of the focus gate, numpy array of shape (n_a, n_a + n_x)
bo -- Bias of the focus gate, numpy array of shape (n_a, 1)
Wy -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
Returns:
a -- Hidden states for every time-step, numpy array of shape (n_a, m, T_x)
y -- Predictions for every time-step, numpy array of shape (n_y, m, T_x)
caches -- tuple of values needed for the backward pass, contains (list of all the caches, x)
"""
# Initialize "caches", which will track the list of all the caches
caches = []
### START CODE HERE ###
# Retrieve dimensions from shapes of xt and Wy (≈2 lines)
n_x, m, T_x = x.shape
n_y, n_a = parameters['Wy'].shape
# initialize "a", "c" and "y" with zeros (≈3 lines)
a = np.zeros((n_a, m, T_x))
c = np.zeros((n_a, m, T_x))
y = np.zeros((n_y, m, T_x))
# Initialize a_next and c_next (≈2 lines)
a_next = a0
c_next = np.zeros((n_a, m))
# loop over all time-steps
for t in range(T_x):
# Update next hidden state, next memory state, compute the prediction, get the cache (≈1 line)
a_next, c_next, yt, cache = lstm_cell_forward(x[:,:,t], a_next, c_next, parameters)
# Save the value of the new "next" hidden state in a (≈1 line)
a[:,:,t] = a_next
# Save the value of the prediction in y (≈1 line)
y[:,:,t] = yt
# Save the value of the next cell state (≈1 line)
c[:,:,t] = c_next
# Append the cache into caches (≈1 line)
caches.append(cache)
### END CODE HERE ###
# store values needed for backward propagation in cache
caches = (caches, x)
return a, y, c, caches
3. RNN 反向传播
深度学习框架一般都会帮你自动实现反向传播,下面我们来简要看看
3.1 基础 RNN 反向传播
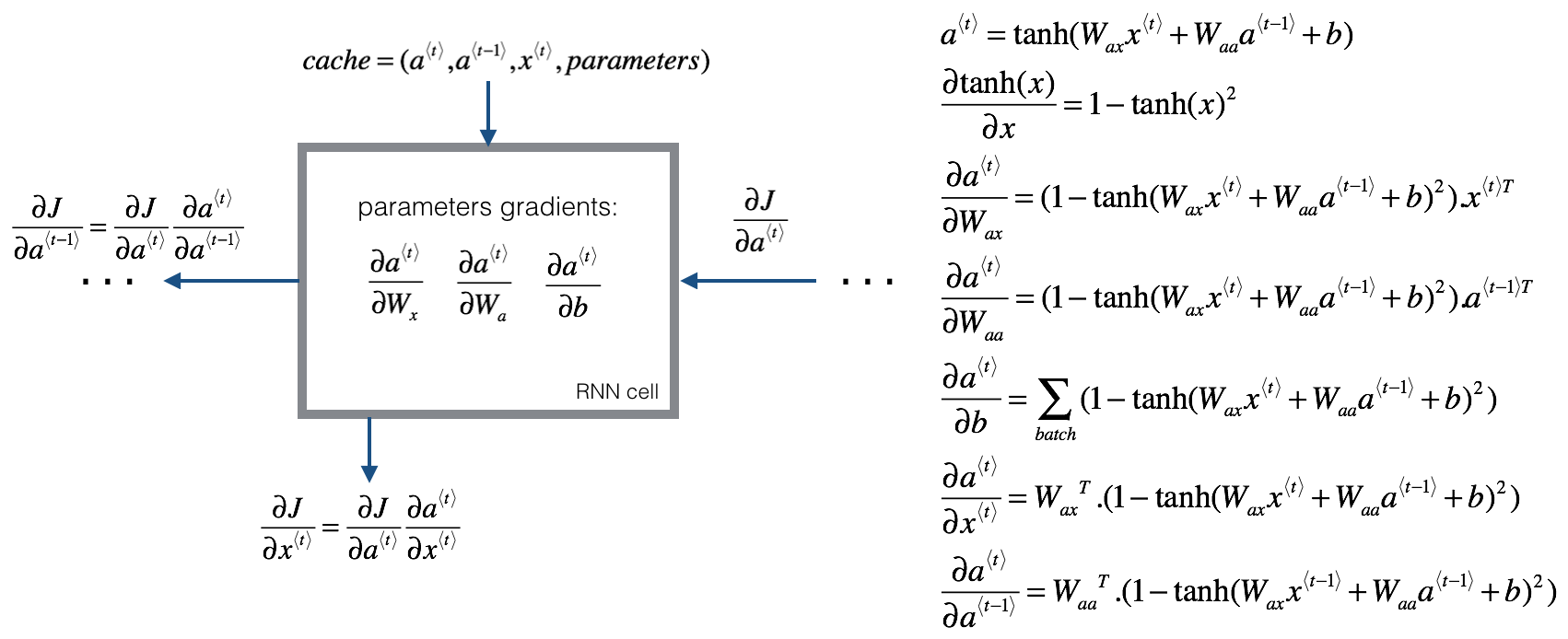
def rnn_cell_backward(da_next, cache):
"""
Implements the backward pass for the RNN-cell (single time-step).
Arguments:
da_next -- Gradient of loss with respect to next hidden state
cache -- python dictionary containing useful values (output of rnn_step_forward())
Returns:
gradients -- python dictionary containing:
dx -- Gradients of input data, of shape (n_x, m)
da_prev -- Gradients of previous hidden state, of shape (n_a, m)
dWax -- Gradients of input-to-hidden weights, of shape (n_a, n_x)
dWaa -- Gradients of hidden-to-hidden weights, of shape (n_a, n_a)
dba -- Gradients of bias vector, of shape (n_a, 1)
"""
# Retrieve values from cache
(a_next, a_prev, xt, parameters) = cache
# Retrieve values from parameters
Wax = parameters["Wax"]
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
### START CODE HERE ###
# compute the gradient of tanh with respect to a_next (≈1 line)
dtanh = (1-a_next**2)*da_next
# compute the gradient of the loss with respect to Wax (≈2 lines)
dxt = np.dot(Wax.T, dtanh)
dWax = np.dot(dtanh, xt.T)
# compute the gradient with respect to Waa (≈2 lines)
da_prev = np.dot(Waa.T, dtanh)
dWaa = np.dot(dtanh, a_prev.T)
# compute the gradient with respect to b (≈1 line)
dba = np.sum(dtanh, axis=1, keepdims=True)
### END CODE HERE ###
# Store the gradients in a python dictionary
gradients = {
"dxt": dxt, "da_prev": da_prev, "dWax": dWax, "dWaa": dWaa, "dba": dba}
return gradients
- 在整个 RNN 网络上实现反向传播
def rnn_backward(da, caches):
"""
Implement the backward pass for a RNN over an entire sequence of input data.
Arguments:
da -- Upstream gradients of all hidden states, of shape (n_a, m, T_x)
caches -- tuple containing information from the forward pass (rnn_forward)
Returns:
gradients -- python dictionary containing:
dx -- Gradient w.r.t. the input data, numpy-array of shape (n_x, m, T_x)
da0 -- Gradient w.r.t the initial hidden state, numpy-array of shape (n_a, m)
dWax -- Gradient w.r.t the input's weight matrix, numpy-array of shape (n_a, n_x)
dWaa -- Gradient w.r.t the hidden state's weight matrix, numpy-arrayof shape (n_a, n_a)
dba -- Gradient w.r.t the bias, of shape (n_a, 1)
"""
### START CODE HERE ###
# Retrieve values from the first cache (t=1) of caches (≈2 lines)
(caches, x) = caches
(a1, a0, x1, parameters) = caches[0]
# Retrieve dimensions from da's and x1's shapes (≈2 lines)
n_a, m, T_x = da.shape
n_x, m = x1.shape
# initialize the gradients with the right sizes (≈6 lines)
dx = np.zeros((n_x, m, T_x))
dWax = np.zeros((n_a, n_x))
dWaa = np.zeros((n_a, n_a))
dba = np.zeros((n_a, 1))
da0 = np.zeros((n_a, m))
da_prevt = np.zeros((n_a, m))
# Loop through all the time steps
for t in reversed(range(T_x)):
# Compute gradients at time step t. Choose wisely the "da_next" and the "cache" to use in the backward propagation step. (≈1 line)
gradients = rnn_cell_backward(da[:,:,t]+da_prevt, caches[t])
# Retrieve derivatives from gradients (≈ 1 line)
dxt, da_prevt, dWaxt, dWaat, dbat = gradients['dxt'],gradients['da_prev'],gradients['dWax'],gradients['dWaa'],gradients['dba']
# Increment global derivatives w.r.t parameters by adding their derivative at time-step t (≈4 lines)
dx[:, :, t] = dxt
dWax = dWax + dWaxt
dWaa = dWaa + dWaat
dba = dba + dbat
# Set da0 to the gradient of a which has been backpropagated through all time-steps (≈1 line)
da0 = da_prevt
### END CODE HERE ###
# Store the gradients in a python dictionary
gradients = {
"dx": dx, "da0": da0, "dWax": dWax, "dWaa": dWaa,"dba": dba}
return gradients
3.2 LSTM 反向传播
- gate 导数:
d Γ o ⟨ t ⟩ = d a n e x t ∗ tanh ( c n e x t ) ∗ Γ o ⟨ t ⟩ ∗ ( 1 − Γ o ⟨ t ⟩ ) d \Gamma_o^{\langle t \rangle} = da_{next}*\tanh(c_{next}) * \Gamma_o^{\langle t \rangle}*(1-\Gamma_o^{\langle t \rangle}) dΓo⟨t⟩=danext∗tanh(cnext)∗Γo⟨t⟩∗(1−Γo⟨t⟩)
d c ~ ⟨ t ⟩ = d c n e x t ∗ Γ i ⟨ t ⟩ + Γ o ⟨ t ⟩ ( 1 − tanh ( c n e x t ) 2 ) ∗ i t ∗ d a n e x t ∗ c ~ ⟨ t ⟩ ∗ ( 1 − tanh ( c ~ ) 2 ) d\tilde c^{\langle t \rangle} = dc_{next}*\Gamma_i^{\langle t \rangle}+ \Gamma_o^{\langle t \rangle} (1-\tanh(c_{next})^2) * i_t * da_{next} * \tilde c^{\langle t \rangle} * (1-\tanh(\tilde c)^2) dc~⟨t⟩=dcnext∗Γi⟨t⟩+Γo⟨t⟩(1−tanh(cnext)2)∗it∗danext∗c~⟨t⟩∗(1−tanh(c~)2)
d Γ u ⟨ t ⟩ = d c n e x t ∗ c ~ ⟨ t ⟩ + Γ o ⟨ t ⟩ ( 1 − tanh ( c n e x t ) 2 ) ∗ c ~ ⟨ t ⟩ ∗ d a n e x t ∗ Γ u ⟨ t ⟩ ∗ ( 1 − Γ u ⟨ t ⟩ ) d\Gamma_u^{\langle t \rangle} = dc_{next}*\tilde c^{\langle t \rangle} + \Gamma_o^{\langle t \rangle} (1-\tanh(c_{next})^2) * \tilde c^{\langle t \rangle} * da_{next}*\Gamma_u^{\langle t \rangle}*(1-\Gamma_u^{\langle t \rangle}) dΓu⟨t⟩=dcnext∗c~⟨t⟩+Γo⟨t⟩(1−tanh(cnext)2)∗c~⟨t⟩∗danext∗Γu⟨t⟩∗(1−Γu⟨t⟩)
d Γ f ⟨ t ⟩ = d c n e x t ∗ c ~ p r e v + Γ o ⟨ t ⟩ ( 1 − tanh ( c n e x t ) 2 ) ∗ c p r e v ∗ d a n e x t ∗ Γ f ⟨ t ⟩ ∗ ( 1 − Γ f ⟨ t ⟩ ) d\Gamma_f^{\langle t \rangle} = dc_{next}*\tilde c_{prev} + \Gamma_o^{\langle t \rangle} (1-\tanh(c_{next})^2) * c_{prev} * da_{next}*\Gamma_f^{\langle t \rangle}*(1-\Gamma_f^{\langle t \rangle}) dΓf⟨t⟩=dcnext∗c~prev+Γo⟨t⟩(1−tanh(cnext)2)∗cprev∗danext∗Γf⟨t⟩∗(1−Γf⟨t⟩)
- parameter 导数
d W f = d Γ f ⟨ t ⟩ ∗ ( a p r e v x t ) T dW_f = d\Gamma_f^{\langle t \rangle} * \begin{pmatrix} a_{prev} \\ x_t\end{pmatrix}^T dWf=dΓf⟨t⟩∗(aprevxt)T
d W u = d Γ u ⟨ t ⟩ ∗ ( a p r e v x t ) T dW_u = d\Gamma_u^{\langle t \rangle} * \begin{pmatrix} a_{prev} \\ x_t\end{pmatrix}^T dWu=dΓu⟨t⟩∗(aprevxt)T
d W c = d c ~ ⟨ t ⟩ ∗ ( a p r e v x t ) T dW_c = d\tilde c^{\langle t \rangle} * \begin{pmatrix} a_{prev} \\ x_t\end{pmatrix}^T dWc=dc~⟨t⟩∗(aprevxt)T
d W o = d Γ o ⟨ t ⟩ ∗ ( a p r e v x t ) T dW_o = d\Gamma_o^{\langle t \rangle} * \begin{pmatrix} a_{prev} \\ x_t\end{pmatrix}^T dWo=dΓo⟨t⟩∗(aprevxt)T
为了计算 d b f , d b u , d b c , d b o db_f, db_u, db_c, db_o dbf,dbu,dbc,dbo ,在 d Γ f ⟨ t ⟩ , d Γ u ⟨ t ⟩ , d c ~ ⟨ t ⟩ , d Γ o ⟨ t ⟩ d\Gamma_f^{\langle t \rangle}, d\Gamma_u^{\langle t \rangle}, d\tilde c^{\langle t \rangle}, d\Gamma_o^{\langle t \rangle} dΓf⟨t⟩,dΓu⟨t⟩,dc~⟨t⟩,dΓo⟨t⟩ 水平轴 (axis= 1)上求和 ,注意keep_dims = True
d a p r e v = W f T ∗ d Γ f ⟨ t ⟩ + W u T ∗ d Γ u ⟨ t ⟩ + W c T ∗ d c ~ ⟨ t ⟩ + W o T ∗ d Γ o ⟨ t ⟩ da_{prev} = W_f^T*d\Gamma_f^{\langle t \rangle} + W_u^T * d\Gamma_u^{\langle t \rangle}+ W_c^T * d\tilde c^{\langle t \rangle} + W_o^T * d\Gamma_o^{\langle t \rangle} daprev=WfT∗dΓf⟨t⟩+WuT∗dΓu⟨t⟩+WcT∗dc~⟨t⟩+WoT∗dΓo⟨t⟩
d c p r e v = d c n e x t Γ f ⟨ t ⟩ + Γ o ⟨ t ⟩ ∗ ( 1 − tanh ( c n e x t ) 2 ) ∗ Γ f ⟨ t ⟩ ∗ d a n e x t dc_{prev} = dc_{next}\Gamma_f^{\langle t \rangle} + \Gamma_o^{\langle t \rangle} * (1- \tanh(c_{next})^2)*\Gamma_f^{\langle t \rangle}*da_{next} dcprev=dcnextΓf⟨t⟩+Γo⟨t⟩∗(1−tanh(cnext)2)∗Γf⟨t⟩∗danext
d x ⟨ t ⟩ = W f T ∗ d Γ f ⟨ t ⟩ + W u T ∗ d Γ u ⟨ t ⟩ + W c T ∗ d c ~ t + W o T ∗ d Γ o ⟨ t ⟩ dx^{\langle t \rangle} = W_f^T*d\Gamma_f^{\langle t \rangle} + W_u^T * d\Gamma_u^{\langle t \rangle}+ W_c^T * d\tilde c_t + W_o^T * d\Gamma_o^{\langle t \rangle} dx⟨t⟩=WfT∗dΓf⟨t⟩+WuT∗dΓu⟨t⟩+WcT∗dc~t+WoT∗dΓo⟨t⟩
注:感觉上面的公式跟正确答案的代码有点对不上。
def lstm_cell_backward(da_next, dc_next, cache):
"""
Implement the backward pass for the LSTM-cell (single time-step).
Arguments:
da_next -- Gradients of next hidden state, of shape (n_a, m)
dc_next -- Gradients of next cell state, of shape (n_a, m)
cache -- cache storing information from the forward pass
Returns:
gradients -- python dictionary containing:
dxt -- Gradient of input data at time-step t, of shape (n_x, m)
da_prev -- Gradient w.r.t. the previous hidden state, numpy array of shape (n_a, m)
dc_prev -- Gradient w.r.t. the previous memory state, of shape (n_a, m, T_x)
dWf -- Gradient w.r.t. the weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
dWi -- Gradient w.r.t. the weight matrix of the input gate, numpy array of shape (n_a, n_a + n_x)
dWc -- Gradient w.r.t. the weight matrix of the memory gate, numpy array of shape (n_a, n_a + n_x)
dWo -- Gradient w.r.t. the weight matrix of the save gate, numpy array of shape (n_a, n_a + n_x)
dbf -- Gradient w.r.t. biases of the forget gate, of shape (n_a, 1)
dbi -- Gradient w.r.t. biases of the update gate, of shape (n_a, 1)
dbc -- Gradient w.r.t. biases of the memory gate, of shape (n_a, 1)
dbo -- Gradient w.r.t. biases of the save gate, of shape (n_a, 1)
"""
# Retrieve information from "cache"
(a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters) = cache
### START CODE HERE ###
# Retrieve dimensions from xt's and a_next's shape (≈2 lines)
n_x, m = xt.shape
n_a, m = a_next.shape
# Compute gates related derivatives, you can find their values can be found by looking carefully at equations (7) to (10) (≈4 lines)
dot = da_next*np.tanh(c_next)*ot*(1-ot)
dcct = (dc_next*it+ot*(1-np.tanh(c_next)**2)*it*da_next)*(1-cct**2)
dit = (dc_next*cct+ot*(1-np.tanh(c_next)**2)*cct*da_next)*it*(1-it)
dft = (dc_next*c_prev+ot*(1-np.tanh(c_next)**2)*c_prev*da_next)*ft*(1-ft)
# Compute parameters related derivatives. Use equations (11)-(14) (≈8 lines)
concat = np.concatenate((a_prev, xt), axis=0)
dWf = np.dot(dft,concat.T)
dWi = np.dot(dit,concat.T)
dWc = np.dot(dcct,concat.T)
dWo = np.dot(dot,concat.T)
dbf = np.sum(dft, axis=1, keepdims=True)
dbi = np.sum(dit, axis=1, keepdims=True)
dbc = np.sum(dcct, axis=1, keepdims=True)
dbo = np.sum(dot, axis=1, keepdims=True)
# Compute derivatives w.r.t previous hidden state, previous memory state and input. Use equations (15)-(17). (≈3 lines)
da_prev = np.dot(parameters['Wf'][:, :n_a].T, dft)+np.dot(parameters['Wi'][:, :n_a].T, dit)+np.dot(parameters['Wc'][:, :n_a].T,dcct)+np.dot(parameters['Wo'][:, :n_a].T,dot)
dc_prev = dc_next*ft+ot*(1-np.tanh(c_next)**2)*ft*da_next
dxt = np.dot(parameters['Wf'][:, n_a:].T,dft)+np.dot(parameters['Wi'][:, n_a:].T,dit)+np.dot(parameters['Wc'][:, n_a:].T,dcct)+np.dot(parameters['Wo'][:, n_a:].T,dot)
### END CODE HERE ###
# Save gradients in dictionary
gradients = {
"dxt": dxt, "da_prev": da_prev, "dc_prev": dc_prev, "dWf": dWf,"dbf": dbf, "dWi": dWi,"dbi": dbi,
"dWc": dWc,"dbc": dbc, "dWo": dWo,"dbo": dbo}
return gradients
3.3 LSTM RNN网络反向传播
def lstm_backward(da, caches):
"""
Implement the backward pass for the RNN with LSTM-cell (over a whole sequence).
Arguments:
da -- Gradients w.r.t the hidden states, numpy-array of shape (n_a, m, T_x)
dc -- Gradients w.r.t the memory states, numpy-array of shape (n_a, m, T_x)
caches -- cache storing information from the forward pass (lstm_forward)
Returns:
gradients -- python dictionary containing:
dx -- Gradient of inputs, of shape (n_x, m, T_x)
da0 -- Gradient w.r.t. the previous hidden state, numpy array of shape (n_a, m)
dWf -- Gradient w.r.t. the weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
dWi -- Gradient w.r.t. the weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x)
dWc -- Gradient w.r.t. the weight matrix of the memory gate, numpy array of shape (n_a, n_a + n_x)
dWo -- Gradient w.r.t. the weight matrix of the save gate, numpy array of shape (n_a, n_a + n_x)
dbf -- Gradient w.r.t. biases of the forget gate, of shape (n_a, 1)
dbi -- Gradient w.r.t. biases of the update gate, of shape (n_a, 1)
dbc -- Gradient w.r.t. biases of the memory gate, of shape (n_a, 1)
dbo -- Gradient w.r.t. biases of the save gate, of shape (n_a, 1)
"""
# Retrieve values from the first cache (t=1) of caches.
(caches, x) = caches
(a1, c1, a0, c0, f1, i1, cc1, o1, x1, parameters) = caches[0]
### START CODE HERE ###
# Retrieve dimensions from da's and x1's shapes (≈2 lines)
n_a, m, T_x = da.shape
n_x, m = x1.shape
# initialize the gradients with the right sizes (≈12 lines)
dx = np.zeros([n_x, m, T_x])
da0 = np.zeros([n_a, m])
da_prevt = np.zeros([n_a, 1])
dc_prevt = np.zeros([n_a, 1])
dWf = np.zeros([n_a, n_a + n_x])
dWi = np.zeros([n_a, n_a + n_x])
dWc = np.zeros([n_a, n_a + n_x])
dWo = np.zeros([n_a, n_a + n_x])
dbf = np.zeros([n_a, 1])
dbi = np.zeros([n_a, 1])
dbc = np.zeros([n_a, 1])
dbo = np.zeros([n_a, 1])
# loop back over the whole sequence
for t in reversed(range(T_x)):
# Compute all gradients using lstm_cell_backward
gradients = lstm_cell_backward(da[:,:,t], dc_prevt, caches[t])
# da_prevt, dc_prevt = gradients['da_prev'], gradients["dc_prev"]
# Store or add the gradient to the parameters' previous step's gradient
dx[:,:,t] = gradients['dxt']
dWf = dWf+gradients['dWf']
dWi = dWi+gradients['dWi']
dWc = dWc+gradients['dWc']
dWo = dWo+gradients['dWo']
dbf = dbf+gradients['dbf']
dbi = dbi+gradients['dbi']
dbc = dbc+gradients['dbc']
dbo = dbo+gradients['dbo']
# Set the first activation's gradient to the backpropagated gradient da_prev.
da0 = gradients['da_prev']
### END CODE HERE ###
# Store the gradients in a python dictionary
gradients = {
"dx": dx, "da0": da0, "dWf": dWf,"dbf": dbf, "dWi": dWi,"dbi": dbi,
"dWc": dWc,"dbc": dbc, "dWo": dWo,"dbo": dbo}
return gradients
作业2:字符级语言模型:恐龙岛
恐龙回归了,你要给恐龙命名,你的助手收集了他们能找到的所有恐龙名称的列表,并将它们编译到这个数据集中。
要创建新的恐龙名称,您将构建一个字符级语言模型来生成新名称。您的算法将学习不同的名称模式,并随机生成新的名称。
通过完成这项作业,你将学到:
- 如何存储文本数据以使用RNN进行处理
- 如何合成数据,通过在每个时间步采样预测并将其传递给下一个RNN单元
- 如何建立字符级文本生成RNN网络
- 为什么梯度修剪很重要
加载一些包
import numpy as np
from utils import *
import random
from random import shuffle
1. 问题陈述
1.1 数据集和预处理

data = open('dinos.txt', 'r').read()
data= data.lower()
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
print('There are %d total characters and %d unique characters in your data.' % (data_size, vocab_size))
输出:
There are 19909 total characters and 27 unique characters in your data.
所有恐龙的名字有 26个唯一的字母,还有\n
- 建立
字符:数字哈希映射关系
char_to_ix = {
ch:i for i,ch in enumerate(sorted(chars)) }
ix_to_char = {
i:ch for i,ch in enumerate(sorted(chars)) }
print(ix_to_char)
print(char_to_ix)
输出:
{
0: '\n', 1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e', 6: 'f', 7: 'g', 8: 'h', 9: 'i', 10: 'j', 11: 'k', 12: 'l', 13: 'm', 14: 'n', 15: 'o', 16: 'p', 17: 'q', 18: 'r', 19: 's', 20: 't', 21: 'u', 22: 'v', 23: 'w', 24: 'x', 25: 'y', 26: 'z'}
{
'\n': 0, 'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12, 'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17, 'r': 18, 's': 19, 't': 20, 'u': 21, 'v': 22, 'w': 23, 'x': 24, 'y': 25, 'z': 26}
1.2 模型预览
模型结构:
- 初始化参数
- 运行优化循环
1.前向传播计算损失
2.反向传播计算对应的梯度
3.梯度修剪,防止梯度爆炸
4.使用梯度更新参数 - 返回学习到的参数
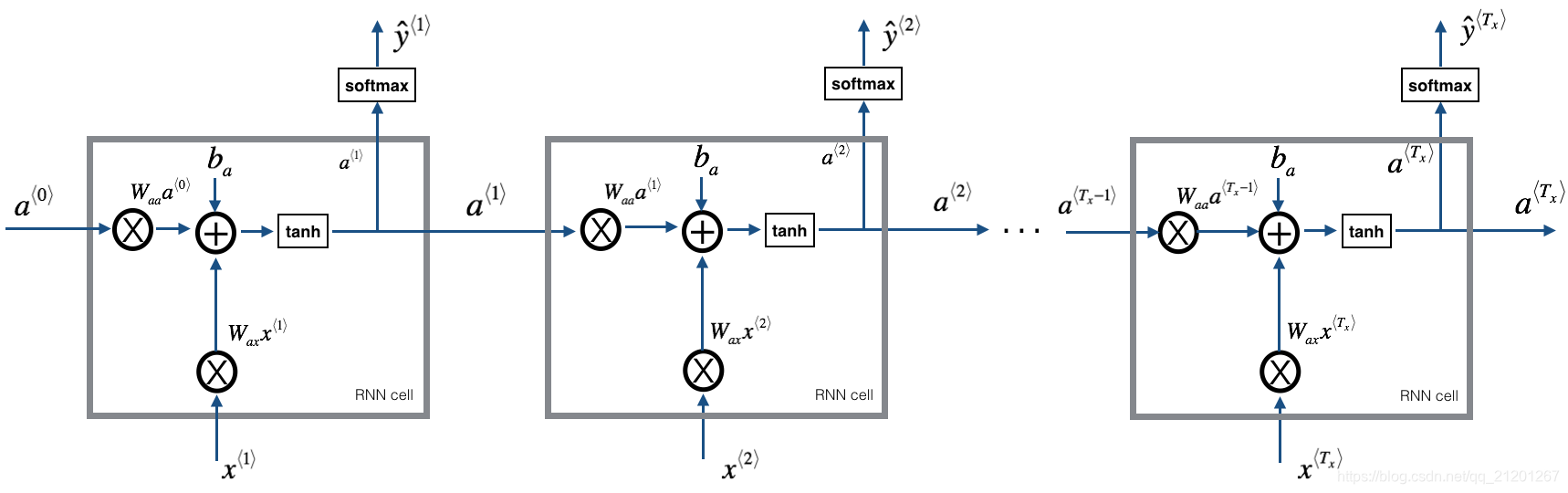
2. 构建模块
模块1:梯度修剪,防止梯度爆炸
模块2:采样,生成字符
2.1 在优化循环中进行梯度修剪
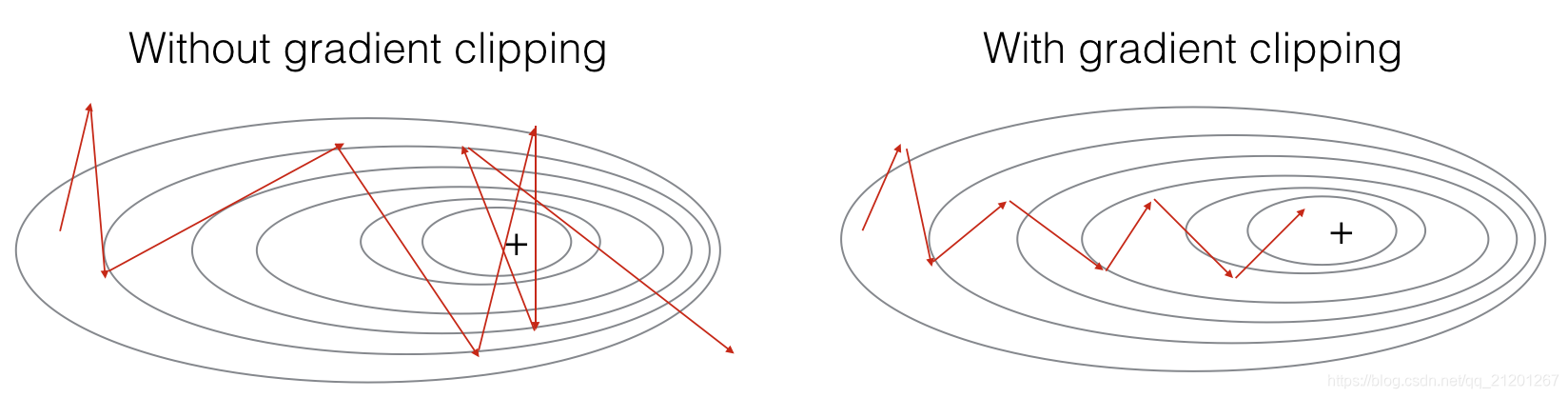
在更新参数之前,先对梯度进行修剪,限制在一定的大小范围内,对不在范围内的取最近的区间端点值
numpy.clip(a, a_min, a_max, out=None)https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.clip.html
### GRADED FUNCTION: clip
def clip(gradients, maxValue):
'''
Clips the gradients' values between minimum and maximum.
Arguments:
gradients -- a dictionary containing the gradients "dWaa", "dWax", "dWya", "db", "dby"
maxValue -- everything above this number is set to this number, and everything less than -maxValue is set to -maxValue
Returns:
gradients -- a dictionary with the clipped gradients.
'''
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
### START CODE HERE ###
# clip to mitigate exploding gradients, loop over [dWax, dWaa, dWya, db, dby]. (≈2 lines)
for gradient in [dWax, dWaa, dWya, db, dby]:
np.clip(gradient, -maxValue, maxValue, out=gradient)
### END CODE HERE ###
gradients = {
"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby}
return gradients
2.2 采样
假设你的模型已经训练好了,你要生成新的文本(字符)
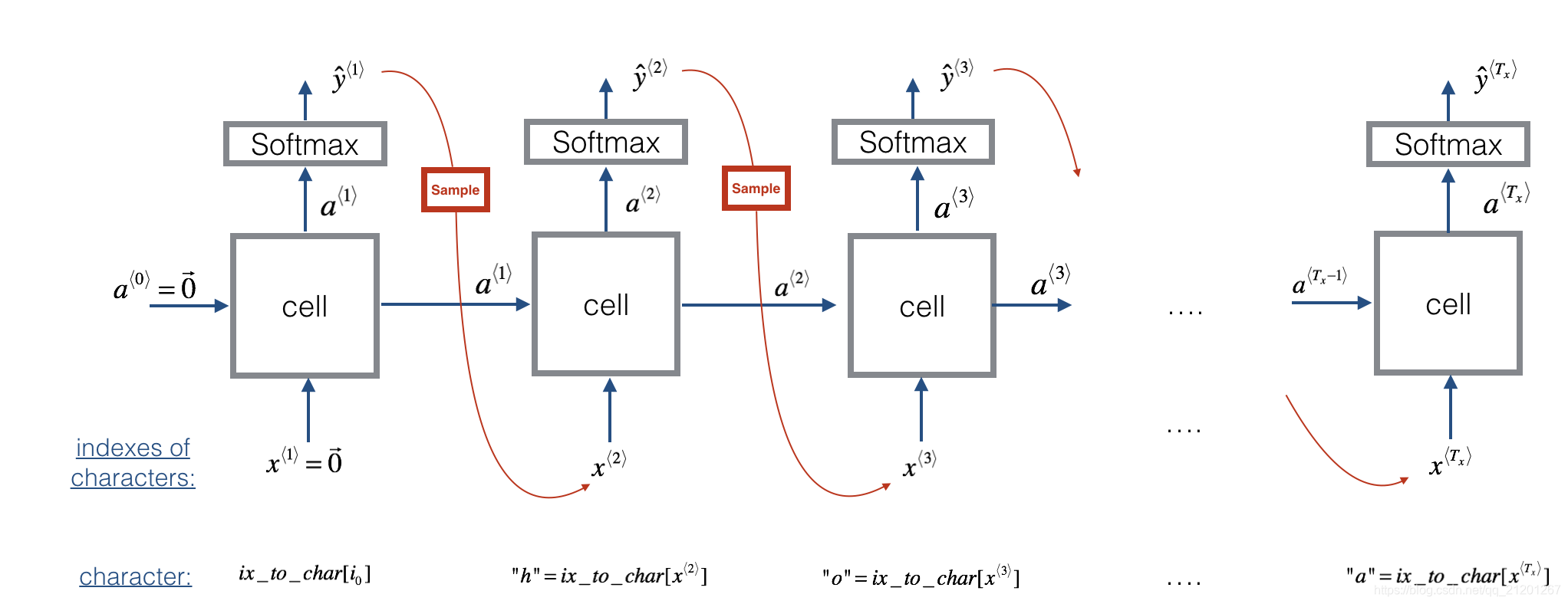
步骤:
-
给模型一个虚拟的输入 x ⟨ 1 ⟩ = 0 ⃗ x^{\langle 1 \rangle} = \vec{0} x⟨1⟩=0, a ⟨ 0 ⟩ = 0 ⃗ a^{\langle 0 \rangle} = \vec{0} a⟨0⟩=0
-
运行一次前向传播,得到 a ⟨ 1 ⟩ a^{\langle 1 \rangle} a⟨1⟩ 和 y ^ ⟨ 1 ⟩ \hat{y}^{\langle 1 \rangle} y^⟨1⟩
a ⟨ t + 1 ⟩ = tanh ( W a x x ⟨ t ⟩ + W a a a ⟨ t ⟩ + b ) a^{\langle t+1 \rangle} = \tanh(W_{ax} x^{\langle t \rangle } + W_{aa} a^{\langle t \rangle } + b) a⟨t+1⟩=tanh(Waxx⟨t⟩+Waaa⟨t⟩+b)
z ⟨ t + 1 ⟩ = W y a a ⟨ t + 1 ⟩ + b y z^{\langle t + 1 \rangle } = W_{ya} a^{\langle t + 1 \rangle } + b_y z⟨t+1⟩=Wyaa⟨t+1⟩+by
y ^ ⟨ t + 1 ⟩ = s o f t m a x ( z ⟨ t + 1 ⟩ ) \hat{y}^{\langle t+1 \rangle } = softmax(z^{\langle t + 1 \rangle }) y^⟨t+1⟩=softmax(z⟨t+1⟩)
- 根据 y ^ ⟨ t + 1 ⟩ \hat{y}^{\langle t+1 \rangle } y^⟨t+1⟩ 的概率分布选择一个字符,可以使用
np.random.choice
一个例子:
np.random.seed(0)
p = np.array([0.1, 0.0, 0.7, 0.2])
index = np.random.choice([0, 1, 2, 3], p = p.ravel())
- 使用 ont-hot 编码后的 x ⟨ t + 1 ⟩ x^{\langle t + 1 \rangle } x⟨t+1⟩ 写入 x x x ,前向传播 x ⟨ t + 1 ⟩ x^{\langle t + 1 \rangle } x⟨t+1⟩ 直到遇见
\n(EOS 结束标志)
# GRADED FUNCTION: sample
def sample(parameters, char_to_ix, seed):
"""
Sample a sequence of characters according to a sequence of probability distributions output of the RNN
Arguments:
parameters -- python dictionary containing the parameters Waa, Wax, Wya, by, and b.
char_to_ix -- python dictionary mapping each character to an index.
seed -- used for grading purposes. Do not worry about it.
Returns:
indices -- a list of length n containing the indices of the sampled characters.
"""
# Retrieve parameters and relevant shapes from "parameters" dictionary
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
vocab_size = by.shape[0]
n_a = Waa.shape[1]
### START CODE HERE ###
# Step 1: Create the one-hot vector x for the first character (initializing the sequence generation). (≈1 line)
x = np.zeros((vocab_size, 1))
# Step 1': Initialize a_prev as zeros (≈1 line)
a_prev = np.zeros((n_a, 1))
# Create an empty list of indices, this is the list which will contain the list of indices of the characters to generate (≈1 line)
indices = []
# Idx is a flag to detect a newline character, we initialize it to -1
idx = -1
# Loop over time-steps t. At each time-step, sample a character from a probability distribution and append
# its index to "indices". We'll stop if we reach 50 characters (which should be very unlikely with a well
# trained model), which helps debugging and prevents entering an infinite loop.
counter = 0
newline_character = char_to_ix['\n']
while (idx != newline_character and counter != 50):
# Step 2: Forward propagate x using the equations (1), (2) and (3)
a = np.tanh(np.dot(Wax, x)+np.dot(Waa, a_prev)+b)
z = np.dot(Wya, a)+by
y = softmax(z)
# for grading purposes
np.random.seed(counter+seed)
# Step 3: Sample the index of a character within the vocabulary from the probability distribution y
idx = np.random.choice(list(range(vocab_size)), p = y.ravel())
# Append the index to "indices"
indices.append(idx)
# Step 4: Overwrite the input character as the one corresponding to the sampled index.
x = np.zeros((vocab_size, 1))
x[idx] = 1
# Update "a_prev" to be "a"
a_prev = a
# for grading purposes
seed += 1
counter +=1
### END CODE HERE ###
if (counter == 50):
indices.append(char_to_ix['\n'])
return indices
3. 建立语言模型
3.1 梯度下降
已经写好的函数:
def rnn_forward(X, Y, a_prev, parameters):
""" Performs the forward propagation through the RNN and computes the cross-entropy loss.
It returns the loss' value as well as a "cache" storing values to be used in the backpropagation."""
....
return loss, cache
def rnn_backward(X, Y, parameters, cache):
""" Performs the backward propagation through time to compute the gradients of the loss with respect
to the parameters. It returns also all the hidden states."""
...
return gradients, a
def update_parameters(parameters, gradients, learning_rate):
""" Updates parameters using the Gradient Descent Update Rule."""
...
return parameters
- 优化过程如下:
# GRADED FUNCTION: optimize
def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
"""
Execute one step of the optimization to train the model.
Arguments:
X -- list of integers, where each integer is a number that maps to a character in the vocabulary.
Y -- list of integers, exactly the same as X but shifted one index to the left.
a_prev -- previous hidden state.
parameters -- python dictionary containing:
Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
b -- Bias, numpy array of shape (n_a, 1)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
learning_rate -- learning rate for the model.
Returns:
loss -- value of the loss function (cross-entropy)
gradients -- python dictionary containing:
dWax -- Gradients of input-to-hidden weights, of shape (n_a, n_x)
dWaa -- Gradients of hidden-to-hidden weights, of shape (n_a, n_a)
dWya -- Gradients of hidden-to-output weights, of shape (n_y, n_a)
db -- Gradients of bias vector, of shape (n_a, 1)
dby -- Gradients of output bias vector, of shape (n_y, 1)
a[len(X)-1] -- the last hidden state, of shape (n_a, 1)
"""
### START CODE HERE ###
# Forward propagate through time (≈1 line)
loss, cache = rnn_forward(X,Y,a_prev,parameters)
# Backpropagate through time (≈1 line)
gradients, a = rnn_backward(X,Y,parameters,cache)
# Clip your gradients between -5 (min) and 5 (max) (≈1 line)
gradients = clip(gradients, maxValue=5)
# Update parameters (≈1 line)
parameters = update_parameters(parameters, gradients, learning_rate)
### END CODE HERE ###
return loss, gradients, a[len(X)-1]
3.2 训练模型
给定恐龙名称的数据集,使用数据集的每一行(一个名称)作为一个训练样本。
每100步随机梯度下降,抽样10个随机选择的名字,看看算法是如何做的,记住随机打乱数据集
当样本包含一个恐龙的名字时,创建训练样本 ( X , Y ) (X,Y) (X,Y) :
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
Y 跟 X 一样,但是往左偏移了 1 位,最后加了一个结束符\n
# GRADED FUNCTION: model
def model(data, ix_to_char, char_to_ix, num_iterations = 35000, n_a = 50, dino_names = 7, vocab_size = 27):
"""
Trains the model and generates dinosaur names.
Arguments:
data -- text corpus
ix_to_char -- dictionary that maps the index to a character
char_to_ix -- dictionary that maps a character to an index
num_iterations -- number of iterations to train the model for
n_a -- number of units of the RNN cell
dino_names -- number of dinosaur names you want to sample at each iteration.
vocab_size -- number of unique characters found in the text, size of the vocabulary
Returns:
parameters -- learned parameters
"""
# Retrieve n_x and n_y from vocab_size
n_x, n_y = vocab_size, vocab_size
# Initialize parameters
parameters = initialize_parameters(n_a, n_x, n_y)
# Initialize loss (this is required because we want to smooth our loss, don't worry about it)
loss = get_initial_loss(vocab_size, dino_names)
# Build list of all dinosaur names (training examples).
with open("dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples]
# Shuffle list of all dinosaur names
shuffle(examples)
# Initialize the hidden state of your LSTM
a_prev = np.zeros((n_a, 1))
# Optimization loop
for j in range(num_iterations):
### START CODE HERE ###
# Use the hint above to define one training example (X,Y) (≈ 2 lines)
index = j%len(examples)
X = [None]+[char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix['\n']]
# Perform one optimization step: Forward-prop -> Backward-prop -> Clip -> Update parameters
# Choose a learning rate of 0.01
curr_loss, gradients, a_prev = optimize(X,Y,a_prev,parameters,learning_rate=0.01)
### END CODE HERE ###
# Use a latency trick to keep the loss smooth. It happens here to accelerate the training.
loss = smooth(loss, curr_loss)
# Every 2000 Iteration, generate "n" characters thanks to sample() to check if the model is learning properly
if j % 2000 == 0:
print('Iteration: %d, Loss: %f' % (j, loss) + '\n')
# The number of dinosaur names to print
seed = 0
for name in range(dino_names):
# Sample indices and print them
sampled_indices = sample(parameters, char_to_ix, seed)
print_sample(sampled_indices, ix_to_char)
seed += 1 # To get the same result for grading purposed, increment the seed by one.
print('\n')
return parameters
- 运行模型
parameters = model(data, ix_to_char, char_to_ix)
您应该观察模型在第一次迭代中输出随机字符。
在几千次迭代之后,模型应该学会生成看起来合理的名称。
- 后续生成的大部分带有
osaurus后缀(拉丁词根,蜥蜴类的)
Iteration: 0, Loss: 23.093929
Nkzxwtdmfqoeyhsqwasjjjvu
Kneb
Kzxwtdmfqoeyhsqwasjjjvu
Neb
Zxwtdmfqoeyhsqwasjjjvu
Eb
Xwtdmfqoeyhsqwasjjjvu
Iteration: 2000, Loss: 27.865115
Livtos
Hnba
Iwtos
Lca
Xuscandorawhus
Ba
Tos
Iteration: 4000, Loss: 25.632137
Livosaqrasaurus
Imacaipqia
Iwtosaurus
Lebagosan
Xusiangopdtipos
Acaipon
Torangosaurus
Iteration: 6000, Loss: 24.694657
Mhytosaurus
Imacaesaurus
Iustolmascatarosaurus
Macagptoia
Wustandosaurus
Baaerpe
Stoimatonyirosaurus
Iteration: 8000, Loss: 24.138770
Nhyusicheoravfpsadrenitochustelanfetalkang
Klecalosaurus
Lyusodomophxgshuaomimus
Ngaagosaurus
Xutognatoptkoroclingos
Eeahosaurus
Troenatoptloroclingos
Iteration: 10000, Loss: 23.604738
Ngyusichaosaurus
Inecamosaurus
Kytrodoninaweosanqosaurosaurus
Ncaadosaurus
Xustangosaurus
Caadosaurus
Trocheosaurus
Iteration: 12000, Loss: 23.576294
Mivustandosaurus
Inceaeus
Jyustandorix
Macacitadantithinviceyalosaurus
Xustanesaurus
Cabarsan
Trrangosaurus
Iteration: 14000, Loss: 23.446216
Ngyrosaurus
Kiecanosaurus
Lyuroknesaurus
Nebairopadrus
Xusrangpreusaurus
Daahosaurus
Torangosaurus
Iteration: 16000, Loss: 23.113554
Mewtosaurus
Inedahosaurus
Iwtroceplocuriosaurus
Macamosaurus
Xustangriasaurus
Cabarpelarops
Troceratosaurus
Iteration: 18000, Loss: 23.254092
Mevutoneosaurus
Inecaltona
Kyutollessaurus
Macaisteialus
Xustarchulultitan
Caaerta
Trodicticurotoknathus
Iteration: 20000, Loss: 23.110590
Onwutonganmaurosaurus
Lkehalosaurus
Lyutolidon
Omaakrong
Xwuterasaurus
Daakosaurus
Trokianlaus
Iteration: 22000, Loss: 22.879895
Lixsopelisaurus
Indaaerosaurus
Iwuskanesaurus
Lecacosaurus
Yuusangosaurus
Ccacosaurus
Trochenoguchosaurus
Iteration: 24000, Loss: 22.836100
Miwtosaurus
Kidiabrong
Lyuspangtomuqusgarihisialopupia
Macalosaurus
Ywurophosaurus
Edalosaurus
Tyrhimosaurus
Iteration: 26000, Loss: 22.734218
Levotolia
Ilaca
Kyusolegosaurus
Lacacisaurus
Wstrasaurus
Caaeosaurus
Surapignaveratapaldys
Iteration: 28000, Loss: 22.750129
Piwustaorathus
Ligabiskia
Lyvusaurus
Pecalosaurus
Xutolomisaurus
Egaiskia
Trocibisaurus
Iteration: 30000, Loss: 22.524480
Lixusaurus
Hicaaeros
Ivrpolopopaudus
Lebairus
Xuromelosaurus
Baaishaecitaurus
Surciinidus
Iteration: 32000, Loss: 22.514697
Mgxusoconltfus
Kiceadosaurus
Lyusteodon
Ngaberopa
Wusteodon
Cabbqukaclus
Surangosaurus
Iteration: 34000, Loss: 22.639142
Llytrodon
Ingaaeropechus
Ivstonnatopulorocophisairus
Lecagosaurus
Xusudolosaurus
Caadosaurus
Surangosaurus
结论:
- 可以看到,算法已经开始产生可信的恐龙名字接近训练结束
- 起初,它是生成随机字符,但到最后你可以看到恐龙的名字有很酷的结尾
- 模型也了解到恐龙的名字往往以
saurus(蜥蜴)、don、aura、tor等结尾
4. 创作莎士比亚诗歌
你可以使用莎士比亚诗集,而不是从恐龙名字的数据集中学习。使用 LSTM 单元,你可以学习更长的依赖关系跨越很多字符
from __future__ import print_function
from keras.callbacks import LambdaCallback
from keras.models import Model, load_model, Sequential
from keras.layers import Dense, Activation, Dropout, Input, Masking
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from shakespeare_utils import *
import sys
import io
模型已经是训练好的,把这个模型再训练一个时代。当它完成时,可以运行generate_output,它将提示您输入(<40个字符)。这首诗将从你的句子开始,模型将为你完成这首诗的剩余部分!
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
model.fit(x, y, batch_size=128, epochs=1, callbacks=[print_callback])
# Run this cell to try with different inputs without having to re-train the model
generate_output()
输出:
Write the beginning of your poem, the Shakespeare machine will complete it. Your input is:
我输入love is forever

我输入love is forever (加一个空格)

Keras Team’s text generation https://github.com/keras-team/keras/blob/master/examples/lstm_text_generation.py
作业3:用LSTM网络即兴演奏爵士乐独奏
注意:pip install music21 安装这个包
from __future__ import print_function
import IPython
import sys
from music21 import *
import numpy as np
from grammar import *
from qa import *
from preprocess import *
from music_utils import *
from data_utils import *
from keras.models import load_model, Model
from keras.layers import Dense, Activation, Dropout, Input, LSTM, Reshape, Lambda, RepeatVector
from keras.initializers import glorot_uniform
from keras.utils import to_categorical
from keras.optimizers import Adam
from keras import backend as K
1. 问题陈述
你要给朋友过生日,你想创作一段音乐,但是你不懂音乐,你要使用 LSTM RNN 生成音乐
1.1 数据集
- 听一下这段音乐
IPython.display.Audio('./data/30s_seq.mp3')

我们的音乐生成系统将使用 78 个独特的值(声调)。运行以下代码来加载原始音乐数据并将其预处理为数字
X, Y, n_values, indices_values = load_music_utils()
print('shape of X:', X.shape)
print('number of training examples:', X.shape[0])
print('Tx (length of sequence):', X.shape[1])
print('total # of unique values:', n_values)
print('Shape of Y:', Y.shape)
输出:
shape of X: (60, 30, 78)
number of training examples: 60
Tx (length of sequence): 30
total # of unique values: 78
Shape of Y: (30, 60, 78)
- X:维度 ( m , T x , 78 ) (m, T_x,78) (m,Tx,78) m 个样本,每个样本有30个音乐值,每个值用 78 维的 one-hot 编码表示
- Y:跟 X 一样,向左移动了一步,维度重塑为 ( T y , m , 78 ) (T_y, m, 78) (Ty,m,78) , T y = T x T_y=T_x Ty=Tx,方便给 LSTM 喂数据
n_values:数据集里独立的编码个数:78indices_values:编码字典映射序号,0-77
1.2 模型预览
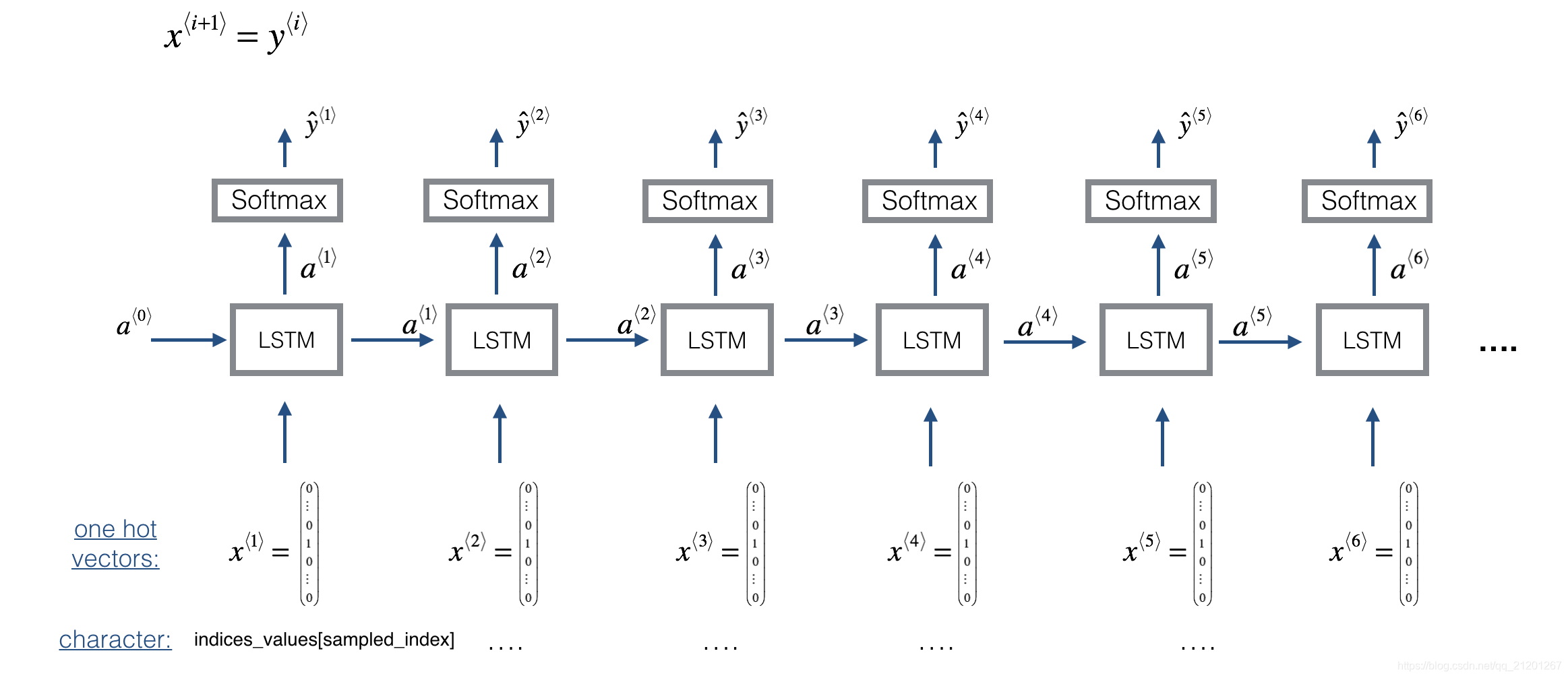
使用 64 维隐藏状态的 LSTM
n_a = 64
LSTM 参考 https://keras.io/zh/layers/recurrent/#lstm

Dense 参考 https://keras.io/zh/layers/core/#dense

reshapor = Reshape((1, 78)) # Used in Step 2.B of djmodel(), below
LSTM_cell = LSTM(n_a, return_state = True) # Used in Step 2.C
densor = Dense(n_values, activation='softmax') # Used in Step 2.D
实现djmodel()步骤:
- 创建空的 list
output存储每个时间步的 LSTM 单元 - for 循环 t ∈ [ 1 , T x ] t \in [1,T_x] t∈[1,Tx]
A. 从X里选择第 i 个时间步向量,x = Lambda(lambda x: x[:,t,:])(X)
B. reshape x 为(1,78)使用layer对象reshapor = Reshape((1, 78))
C. 运行 x 经过 一步LSTM单元,记住用前一步的隐藏层状态 a 和 cell 状态 c 初始化 LSTM单元:a, _, c = LSTM_cell(input_x, initial_state=[previous hidden state, previous cell state])
D. 使用 dense + softmax 得到激活输出
E. 记录预测值到outputs
# GRADED FUNCTION: djmodel
def djmodel(Tx, n_a, n_values):
"""
Implement the model
Arguments:
Tx -- length of the sequence in a corpus
n_a -- the number of activations used in our model
n_values -- number of unique values in the music data
Returns:
model -- a keras model with the
"""
# Define the input of your model with a shape
X = Input(shape=(Tx, n_values))
# Define s0, initial hidden state for the decoder LSTM
a0 = Input(shape=(n_a,), name='a0')
c0 = Input(shape=(n_a,), name='c0')
a = a0
c = c0
### START CODE HERE ###
# Step 1: Create empty list to append the outputs while you iterate (≈1 line)
outputs = []
# Step 2: Loop
for t in range(Tx):
# Step 2.A: select the "t"th time step vector from X.
x = Lambda(lambda x: x[:,t,:])(X)
# Step 2.B: Use reshapor to reshape x to be (1, n_values) (≈1 line)
x = reshapor(x)
# Step 2.C: Perform one step of the LSTM_cell
a, _, c = LSTM_cell(x, initial_state=[a, c])
# Step 2.D: Apply densor to the hidden state output of LSTM_Cell
out = densor(a)
# Step 2.E: add the output to "outputs"
outputs.append(out)
# Step 3: Create model instance
model = Model(inputs=[X, a0, c0], outputs=outputs)
### END CODE HERE ###
return model
这段测试,一直报错,过不去,也找不到原因。。。
model = djmodel(Tx = 30 , n_a = 64, n_values = 78)
报错:
LinAlgError Traceback (most recent call last)
<ipython-input-7-57eb2d19469c> in <module>
----> 1 model = djmodel(Tx = 30 , n_a = 64, n_values = 78)
<ipython-input-6-7a17ca9b5b35> in djmodel(Tx, n_a, n_values)
35 x = reshapor(x)
36 # Step 2.C: Perform one step of the LSTM_cell
---> 37 a, _, c = LSTM_cell(x, initial_state=[a, c])
38 # Step 2.D: Apply densor to the hidden state output of LSTM_Cell
39 out = densor(a)
c:\program files\python37\lib\site-packages\keras\layers\recurrent.py in __call__(self, inputs, initial_state, constants, **kwargs)
582 if 'constants' in kwargs:
583 kwargs.pop('constants')
--> 584 output = super(RNN, self).__call__(full_input, **kwargs)
585 self.input_spec = original_input_spec
586 return output
c:\program files\python37\lib\site-packages\keras\engine\base_layer.py in __call__(self, inputs, **kwargs)
461 'You can build it manually via: '
462 '`layer.build(batch_input_shape)`')
--> 463 self.build(unpack_singleton(input_shapes))
464 self.built = True
465
c:\program files\python37\lib\site-packages\keras\layers\recurrent.py in build(self, input_shape)
500 self.cell.build([step_input_shape] + constants_shape)
501 else:
--> 502 self.cell.build(step_input_shape)
503
504 # set or validate state_spec
c:\program files\python37\lib\site-packages\keras\layers\recurrent.py in build(self, input_shape)
1923 initializer=self.recurrent_initializer,
1924 regularizer=self.recurrent_regularizer,
-> 1925 constraint=self.recurrent_constraint)
1926
1927 if self.use_bias:
c:\program files\python37\lib\site-packages\keras\engine\base_layer.py in add_weight(self, name, shape, dtype, initializer, regularizer, trainable, constraint)
277 if dtype is None:
278 dtype = self.dtype
--> 279 weight = K.variable(initializer(shape, dtype=dtype),
280 dtype=dtype,
281 name=name,
c:\program files\python37\lib\site-packages\keras\initializers.py in __call__(self, shape, dtype)
266 self.seed += 1
267 a = rng.normal(0.0, 1.0, flat_shape)
--> 268 u, _, v = np.linalg.svd(a, full_matrices=False)
269 # Pick the one with the correct shape.
270 q = u if u.shape == flat_shape else v
<__array_function__ internals> in svd(*args, **kwargs)
c:\program files\python37\lib\site-packages\numpy\linalg\linalg.py in svd(a, full_matrices, compute_uv, hermitian)
1624
1625 signature = 'D->DdD' if isComplexType(t) else 'd->ddd'
-> 1626 u, s, vh = gufunc(a, signature=signature, extobj=extobj)
1627 u = u.astype(result_t, copy=False)
1628 s = s.astype(_realType(result_t), copy=False)
c:\program files\python37\lib\site-packages\numpy\linalg\linalg.py in _raise_linalgerror_svd_nonconvergence(err, flag)
104
105 def _raise_linalgerror_svd_nonconvergence(err, flag):
--> 106 raise LinAlgError("SVD did not converge")
107
108 def _raise_linalgerror_lstsq(err, flag):
LinAlgError: SVD did not converge
这个生成音乐先不做了,继续学习。如果有相同错误的小伙伴解决了,记得在下面留言告知方法,多谢了!
我的CSDN博客地址 https://michael.blog.csdn.net/
长按或扫码关注我的公众号(Michael阿明),一起加油、一起学习进步!
