风电机组异常数据识别与清洗-baseline
比赛类型:数据挖掘
比赛数据:表格题(csv)
学习方式:无监督
主办方:国家电力投资集团有限公司科技与创新部
比赛链接
比赛任务:依据提供的8台风力电机1年的10min间隔SCADA运行数据,包括时间戳信息、风速信息和功率信息等,利用机器学习相关技术,建立鲁棒的风电机组异常数据检测模型,用于识别并剔除潜在的异常数据,提高数据质量。
此任务未给出异常数据标签,视为聚类任务,为引导选手向赛题需求对接,现简单阐述异常数据定义。异常数据是由风机运行过程与设计运行工况出现较大偏离时产生,如风速仪测风异常导致采集的功率散点明显偏离设计风功率。
任务概述:根据给出数据 ,12台风力电机 的 【‘风机编号’,‘时间戳’,‘风速’,‘功率’,‘风轮转速’】表格数据进行异常数据的检测,通过无监督的方式(学习方式不限)判断为异常数据进行打标签1,否则为0。
比赛难点:首先,学习方式是无监督的方法,不是简单的二分类表格题,使得一些如xgb树、CNN网络等之类的成熟模型将无法使用,除非通过半监督的方式进行人为打标,但这样风险过大,易过拟合。
其次,可用的方式多种多样,可以通过一定的风电机组发动机实际物理模型进行数学意义上的异常分析,或通过图像法来人为选定异常值,当然,我们也可以按照比赛要求使用经典的无监督模型进行聚类分析。
最后,数据的特征太少了,每一个电机只有【‘时间戳’,‘风速’,‘功率’,‘风轮转速’】四种特征,对于表格题来说,仅仅四种特征无论什么模型效果都会很一般,故特征工程是一定要做的。
注:本baseline仅供共同学习使用
风电机组异常数据识别与清洗 目录
前言
在本篇您将学到:
● 数据分析的基本流程
● 四种经典无监督模型的异常检测
● 本比赛的基本流程
I 数据分析
1.1 数据读取
一共有两个数据集,dataset.csv 以行的方式存放了12台风机的数据,submission.csv 以行的方式存放了风机编号、时间戳和标签label,一共有三列,其中标签label就是我们要建模“预测”提交的。
注意,本数据集不再划分训练集、验证集和测试集,因为训练集和测试集的主键相同(即ID均相同),且学习方式是无监督。如果你考虑使用半监督学习的方式,可以进行数据集的划分,但这样是有一定风险的,因为你要自己打标,这个标签不一定准,且有可能过拟合A榜而导致最终B榜分数有问题,以及实际应用中这种方式将不再实用。
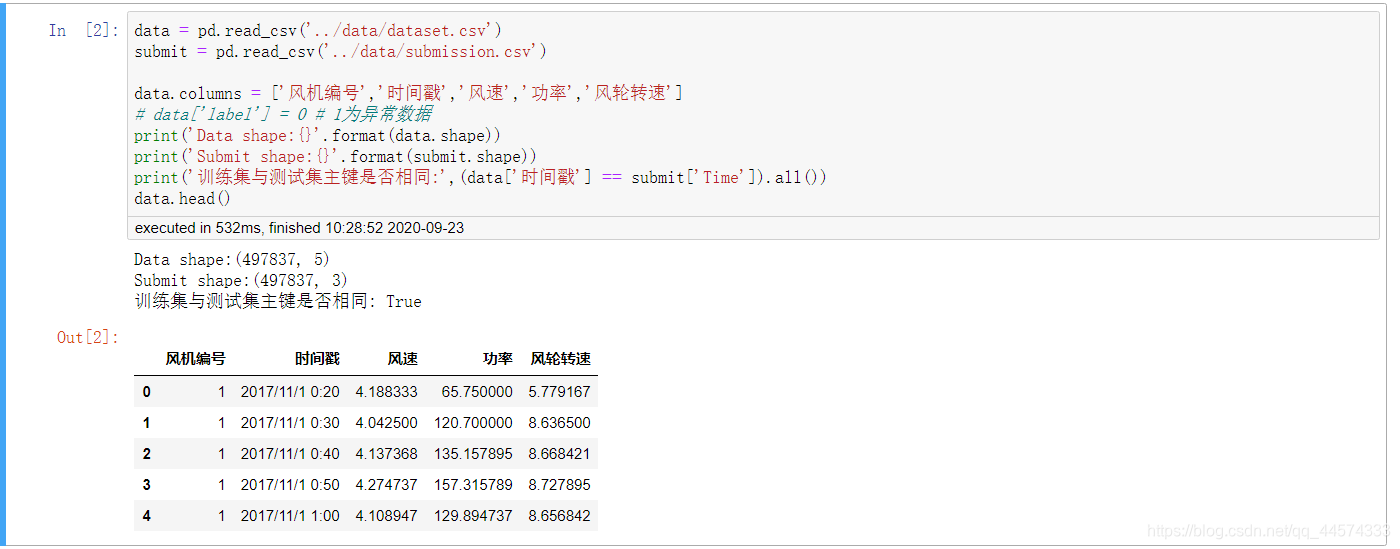
data = pd.read_csv('../data/dataset.csv')
submit = pd.read_csv('../data/submission.csv')
data.columns = ['风机编号','时间戳','风速','功率','风轮转速']
# data['label'] = 0 # 1为异常数据
print('Data shape:{}'.format(data.shape))
print('Submit shape:{}'.format(submit.shape))
print('训练集与测试集主键是否相同:',(data['时间戳'] == submit['Time']).all())
data.head()
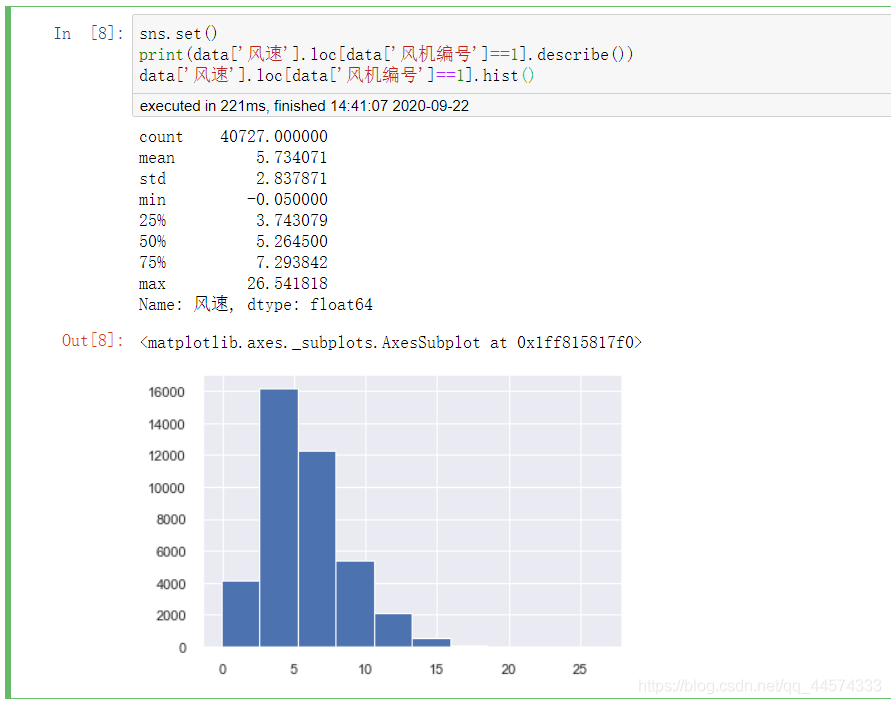
1.2 数据可视化
sns.set()
print(data['风速'].loc[data['风机编号']==1].describe())
data['风速'].loc[data['风机编号']==1].hist()
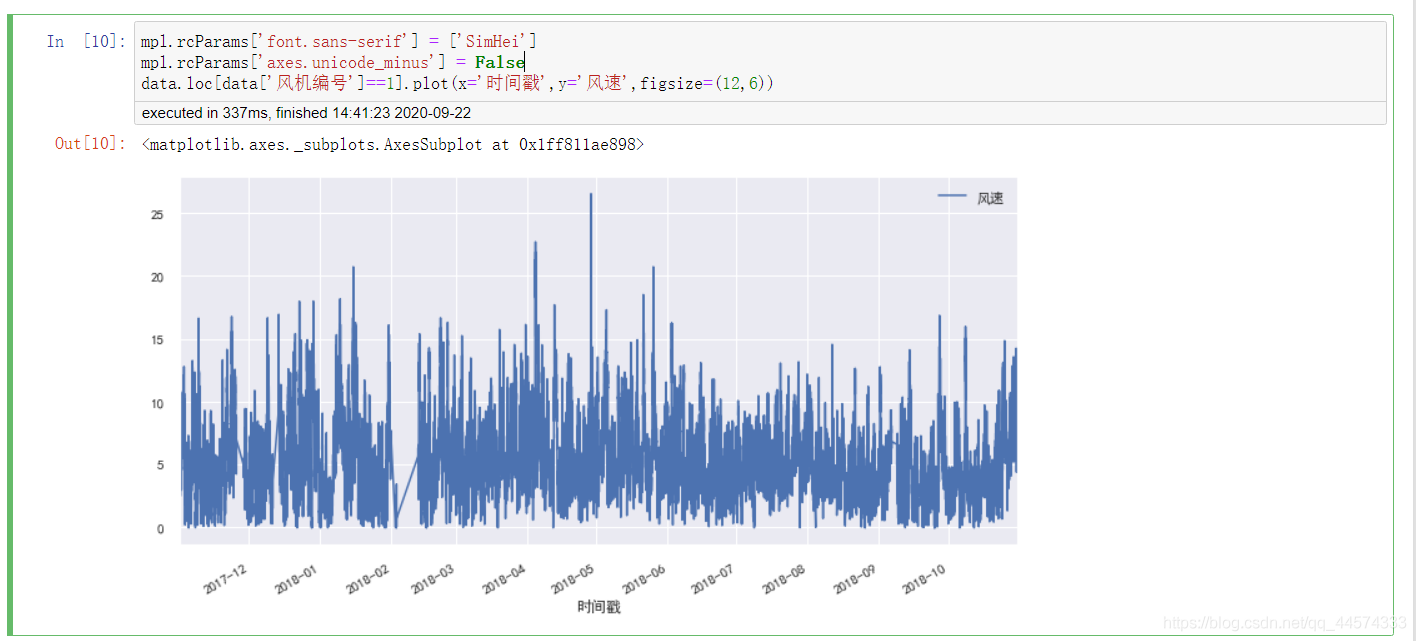
风机1号的全年风速图
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
data.loc[data['风机编号']==1].plot(x='时间戳',y='风速',figsize=(12,6))
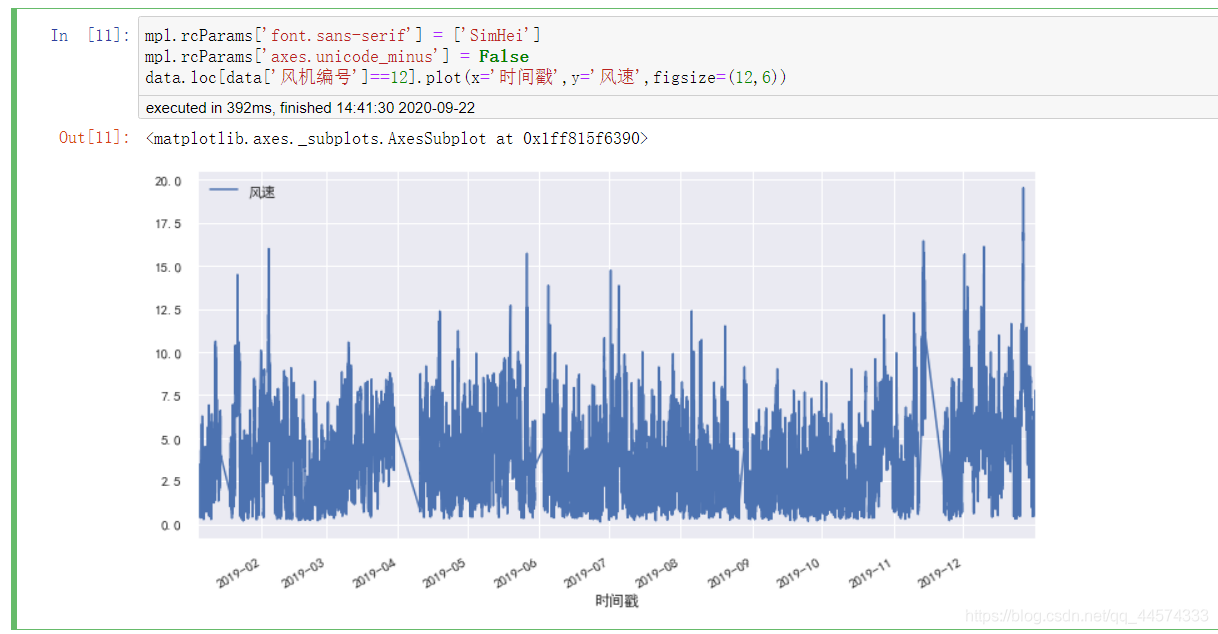
风机12号的全年风速图
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
data.loc[data['风机编号']==12].plot(x='时间戳',y='风速',figsize=(12,6))
12台风机的全年风速图
a1 = data.loc[data['风机编号']==1,'风速']
a2 = data.loc[data['风机编号']==2,'风速']
a3 = data.loc[data['风机编号']==3,'风速']
a4 = data.loc[data['风机编号']==4,'风速']
a5 = data.loc[data['风机编号']==5,'风速']
a6 = data.loc[data['风机编号']==6,'风速']
a7 = data.loc[data['风机编号']==7,'风速']
a8 = data.loc[data['风机编号']==8,'风速']
a9 = data.loc[data['风机编号']==9,'风速']
a10 = data.loc[data['风机编号']==10,'风速']
a11 = data.loc[data['风机编号']==11,'风速']
a12 = data.loc[data['风机编号']==12,'风速']
plt.figure(figsize=(15,10))
plt.hist(a1,bins=50 , alpha=0.5,label='风机编号1')
plt.hist(a2,bins=50 , alpha=0.5,label='风机编号2')
plt.hist(a3,bins=50 , alpha=0.5,label='风机编号3')
plt.hist(a4,bins=50 , alpha=0.5,label='风机编号4')
plt.hist(a5,bins=50 , alpha=0.5,label='风机编号5')
plt.hist(a6,bins=50 , alpha=0.5,label='风机编号6')
plt.hist(a7,bins=50 , alpha=0.5,label='风机编号7')
plt.hist(a8,bins=50 , alpha=0.5,label='风机编号8')
plt.hist(a9,bins=50 , alpha=0.5,label='风机编号9')
plt.hist(a10,bins=50 , alpha=0.5,label='风机编号10')
plt.hist(a11,bins=50 , alpha=0.5,label='风机编号11')
plt.hist(a12,bins=50 , alpha=0.5,label='风机编号12')
plt.legend(loc='upper right')
plt.xlabel('风速')
plt.ylabel('统计')
plt.show()
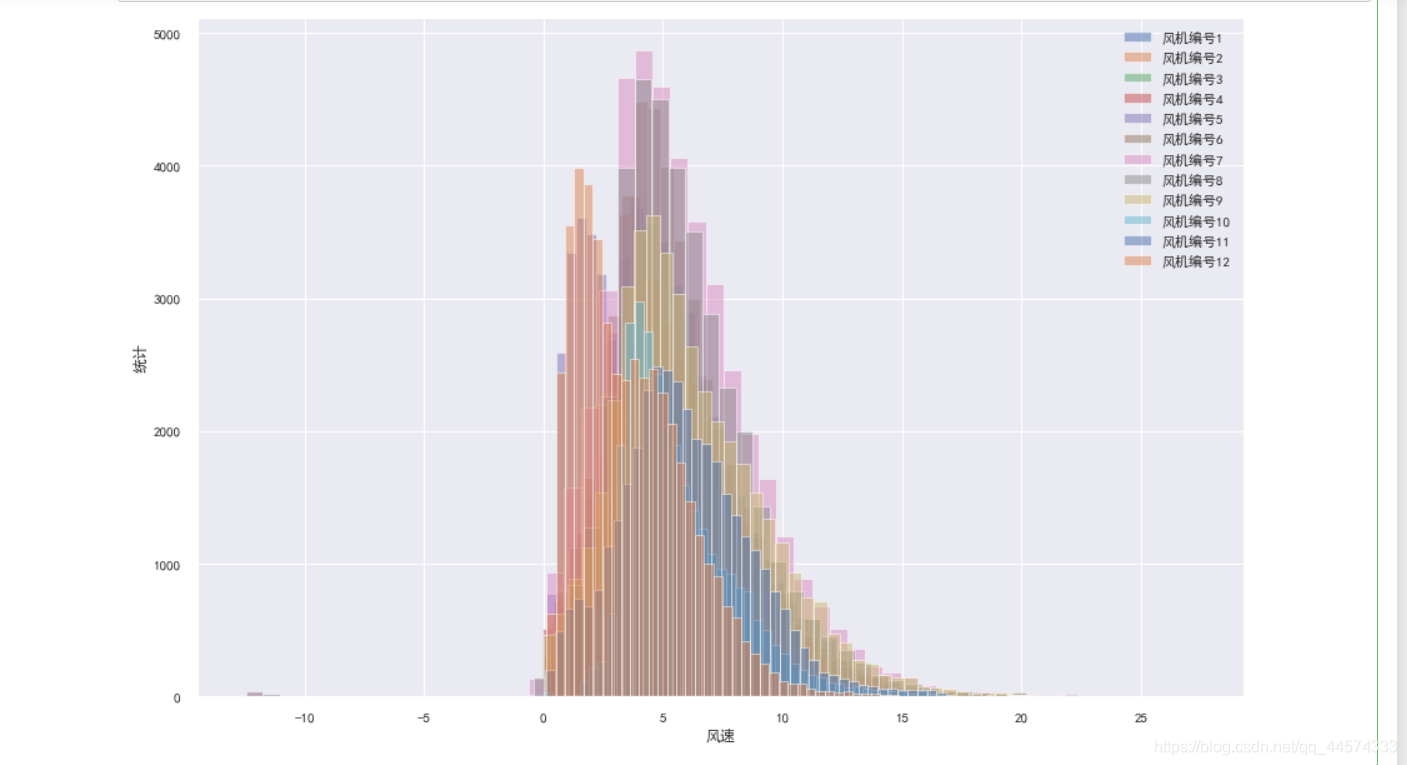
从上面的直方图中可以看出各个风机的全年风速的趋势类似,都是有一定正态分布的规律的,在此分析上,可以对风速进行np.log1p的数字特征处理来减低偏度等。
1.3 特征工程
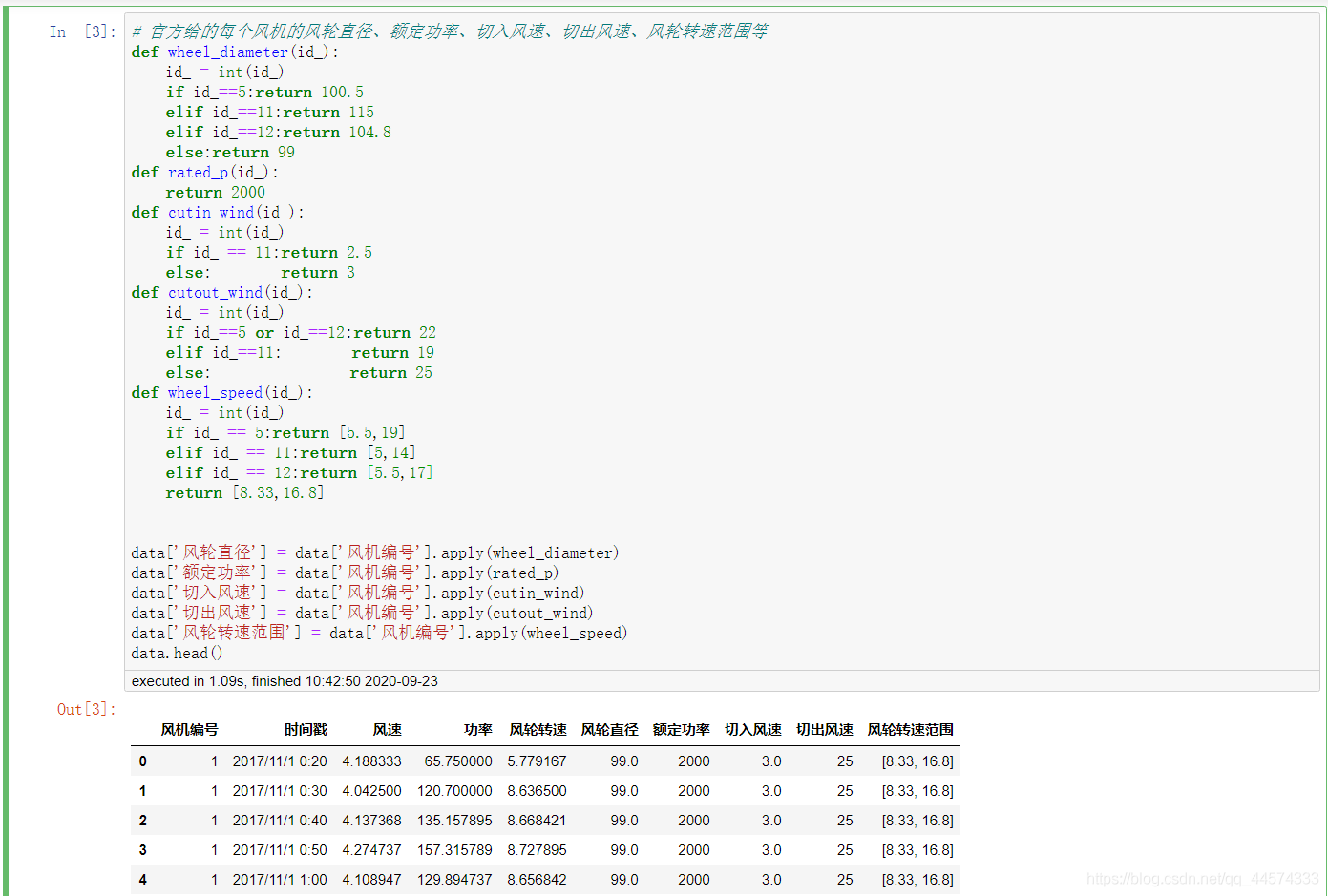
根据比赛官方给出的不同风机各自的风轮直径、额定功率、切入风速、切出风速、风轮转速范围进行添加。
# 官方给的每个风机的风轮直径、额定功率、切入风速、切出风速、风轮转速范围
def wheel_diameter(id_):
id_ = int(id_)
if id_==5:return 100.5
elif id_==11:return 115
elif id_==12:return 104.8
else:return 99
def rated_p(id_):
return 2000
def cutin_wind(id_):
id_ = int(id_)
if id_ == 11:return 2.5
else: return 3
def cutout_wind(id_):
id_ = int(id_)
if id_==5 or id_==12:return 22
elif id_==11: return 19
else: return 25
def wheel_speed(id_):
id_ = int(id_)
if id_ == 5:return [5.5,19]
elif id_ == 11:return [5,14]
elif id_ == 12:return [5.5,17]
return [8.33,16.8]
data['风轮直径'] = data['风机编号'].apply(wheel_diameter)
data['额定功率'] = data['风机编号'].apply(rated_p)
data['切入风速'] = data['风机编号'].apply(cutin_wind)
data['切出风速'] = data['风机编号'].apply(cutout_wind)
data['风轮转速范围'] = data['风机编号'].apply(wheel_speed)
data.head()
在此,为保证比赛竞争性,本baseline再仅提供一个二值特征,比赛群里讨论发现,风轮转速<7约有89%的异常数据,故该二值特征很有意义(能上分)。
def speed(v):
return 0 if v>7 else 1
data['风轮转速_01'] = data['风轮转速'].apply(speed)
提示:你可以通过时间戳做时序特征、根据功率和风轮转速做物理特征、根据切入风速、切出风速等做风速判断等等,以及对数字特征做统计特征等。
II 建立模型
2.1 基于聚类的异常检测
k-means是一种广泛使用的聚类算法。 它创建了k个具有相似特性的数据组。 不属于这些组的数据实例可能会被标记为异常。 在我们开始k-means聚类之前,我们使用elbow方法来确定最佳聚类数量。
data_num = data[['风速','功率','风轮转速']]
n_cluster = range(1, 20)
kmeans = [KMeans(n_clusters=i).fit(data_num) for i in n_cluster]
scores = [kmeans[i].score(data_num) for i in range(len(kmeans))]
fig, ax = plt.subplots(figsize=(10,6))
ax.plot(n_cluster, scores)
plt.xlabel('N_cluster')
plt.ylabel('Score')
plt.title('Elbow Curve')
plt.show()
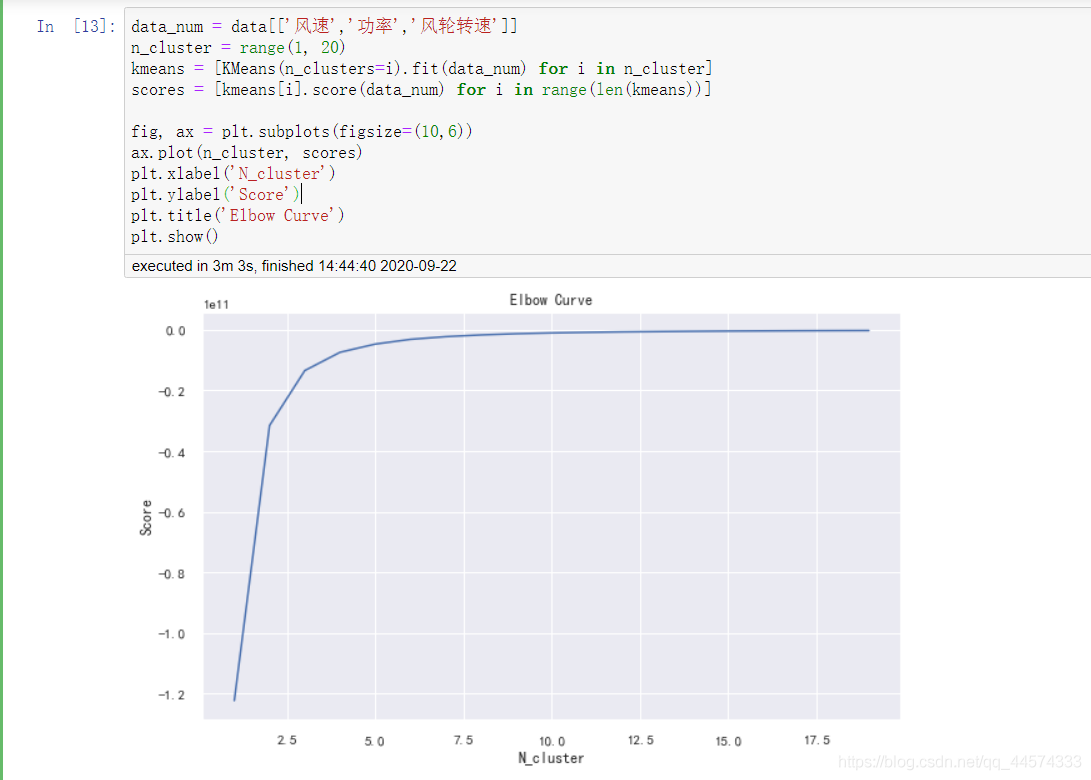
为了找出合理的距离中心数,我们尝试尽可能多的聚类中心数(从1个到20个聚类中心),然后我们画出Elbow曲线,通过观察Elbow曲线,我们发现当我们的聚类中心数量增加到10个以上时Elbow曲线趋于收敛,因此我们大致可以将聚类中心数定为10.
注:在此,请时刻记得我们的任务是什么,是对12台风机的全年数据进行异常数据的检测,聚类成10类仅仅是从整体数据的角度进行考虑的。可以考虑的是分成12组进行分组聚类,聚类的类别为2组,即一组正常、一组异常。
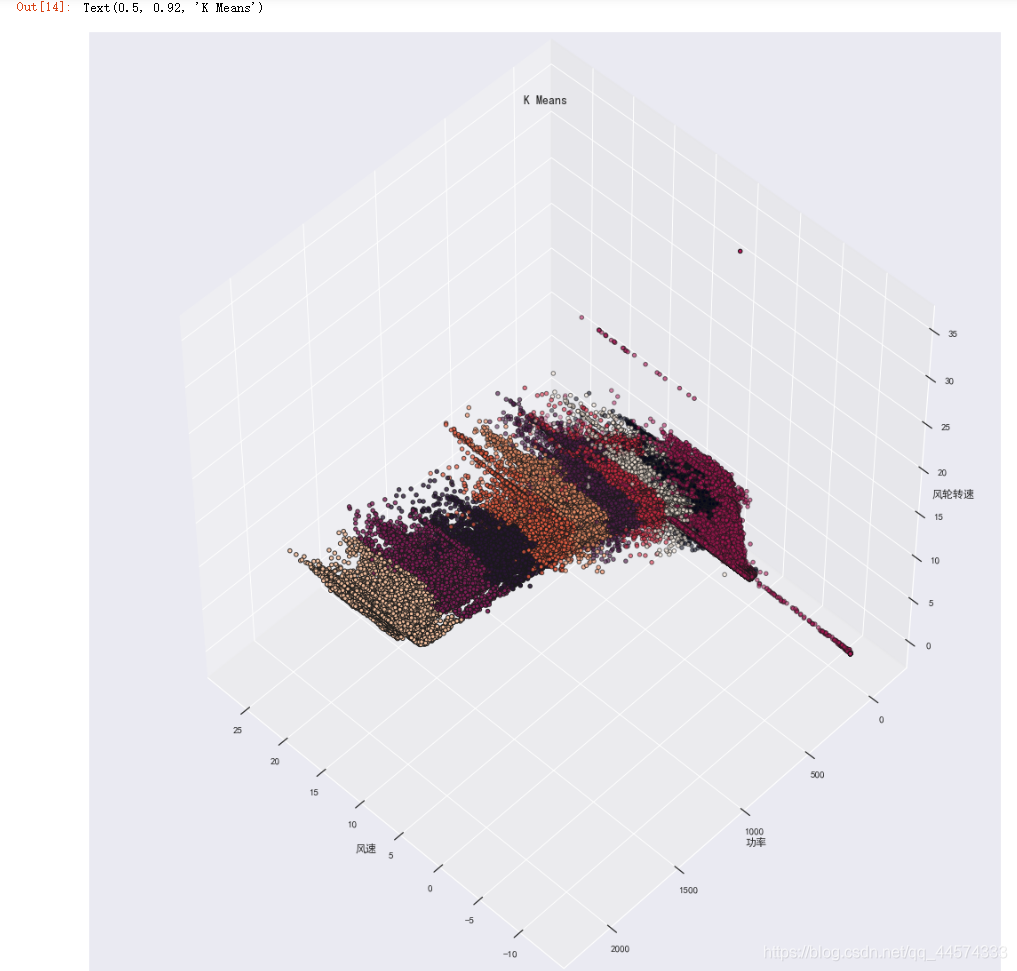
下面我们将K-means算法的n_clusters设置为10,然后我们将数据进行3D可视化。
X = data_num
X = X.reset_index(drop=True)
km = KMeans(n_clusters=10)
km.fit(X)
km.predict(X)
labels = km.labels_
fig = plt.figure(1, figsize=(15,15))
ax = Axes3D(fig, rect=[0, 0, 0.95, 1], elev=48, azim=134)
ax.scatter(X.iloc[:,0], X.iloc[:,1], X.iloc[:,2],
c=labels.astype(np.float), edgecolor="k")
# '风速','功率','风轮转速'
ax.set_xlabel("风速")
ax.set_ylabel("功率")
ax.set_zlabel("风轮转速")
plt.title("K Means", fontsize=14)
让我们再单独看看给1号风机进行类别为2种的聚类
X = data[['风速','功率','风轮转速']].loc[data['风机编号']==1]
X = X.reset_index(drop=True)
km = KMeans(n_clusters=2)
km.fit(X)
km.predict(X)
labels = km.labels_
fig = plt.figure(1, figsize=(10,10))
ax = Axes3D(fig, rect=[0, 0, 0.95, 1], elev=48, azim=134)
ax.scatter(X.iloc[:,0], X.iloc[:,1], X.iloc[:,2],
c=labels.astype(np.float), edgecolor="k")
# '风速','功率','风轮转速'
ax.set_xlabel("风速")
ax.set_ylabel("功率")
ax.set_zlabel("风轮转速")
plt.title("风机编号1 K Means", fontsize=14)

接下来让我们来确定需要保留数据中的哪些主要成分(特征)
X = data_num.values
# 标准化 均值为0 标准差为1
X_std = StandardScaler().fit_transform(X)
mean_vec = np.mean(X_std,axis=0)
# 协方差,协方差矩阵反应了特征变量之间的相关性
# 如果两个特征变量之间的协方差为正则说明它们之间是正相关关系
# 如果为负则说明它们之间是负相关关系
cov_mat = np.cov(X_std.T)
# 特征值和特征向量
eig_vals,eig_vecs = np.linalg.eig(cov_mat)
# 特征值对应的特征向量
eig_pairs = [ (np.abs(eig_vals[i]),eig_vecs[:,i]) for i in range(len(eig_vals))]
eig_pairs.sort(key = lambda x: x[0], reverse= True)
# 特征之求和
eig_sum = sum(eig_vals)
# 解释方差
var_exp = [(i/eig_sum)*100 for i in sorted(eig_vals, reverse=True)]
# 累计的解释方差
cum_var_exp = np.cumsum(var_exp)
plt.figure(figsize=(10,5))
plt.bar(range(len(var_exp)), var_exp, alpha=0.3, align='center', label='独立的解释方差', color = 'g')
plt.step(range(len(cum_var_exp)), cum_var_exp, where='mid',label='累积解释方差')
plt.ylabel('解释方差率')
plt.xlabel('主成分')
plt.legend(loc='best')
plt.show()
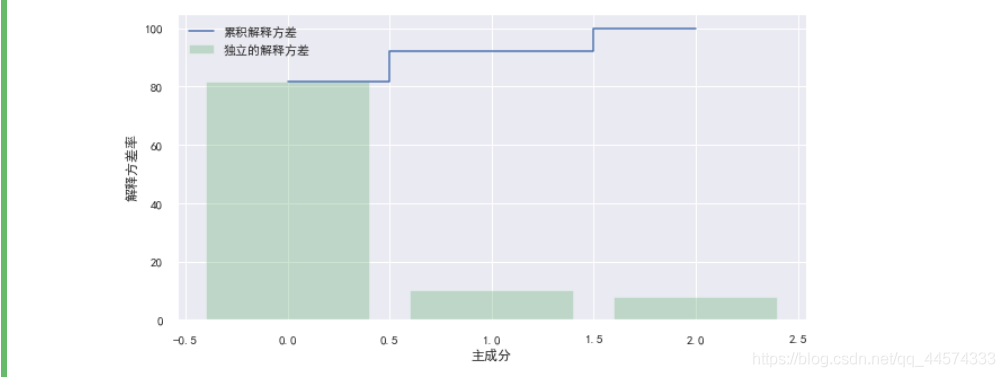
我们首先对数据进行标准化处理(StandardScaler),
然后再计算特征变量之间的协方差矩阵,协方差矩阵反应了特征变量之间的相关性,如果两个特征变量之间的协方差为正则说明它们之间是正相关关系,如果为负则说明它们之间是负相关关系,如果为0则说明特征变量之间是相互独立的关系,不存在相关关系(有时候我们也会用相关系数矩阵来代替协方差矩阵)。
最后在协方差矩阵的基础上又计算了协方差矩阵的特征值和特征向量,根据特征值计算出每个主成分(特征)的解释方差,以及累计解释方差,
我们这样做的目的是为了下一步做主成分分析(PCA)挑选出特征变量中的主成分。
我们挑选第一个主成分,因为它的累计解释方差为80%。
从上图可知我们的三个主成分,第一个主成分(特征)解释了将近80%的方差变化,第二个主成分解释了近15%的方差变化,那么第一个主成分解释了近80%的方差。因此接下来我们将使用PCA算法进行降维并将设置参数n_components=1。
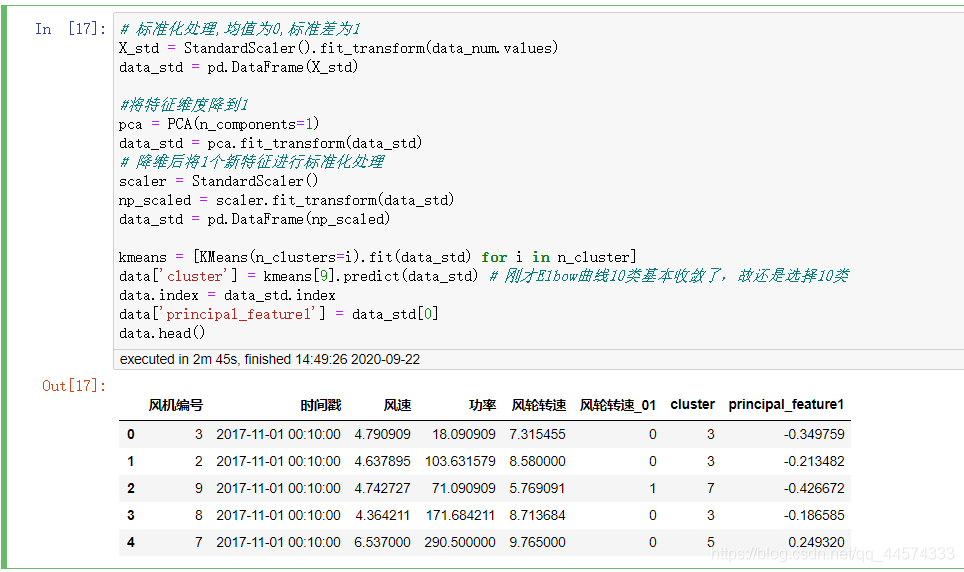
# 标准化处理,均值为0,标准差为1
X_std = StandardScaler().fit_transform(data_num.values)
data_std = pd.DataFrame(X_std)
#将特征维度降到1
pca = PCA(n_components=1)
data_std = pca.fit_transform(data_std)
# 降维后将1个新特征进行标准化处理
scaler = StandardScaler()
np_scaled = scaler.fit_transform(data_std)
data_std = pd.DataFrame(np_scaled)
kmeans = [KMeans(n_clusters=i).fit(data_std) for i in n_cluster]
data['cluster'] = kmeans[9].predict(data_std) # 刚才Elbow曲线10类基本收敛了,故还是选择10类
data.index = data_std.index
data['principal_feature1'] = data_std[0]
data.head()
基于聚类的异常检测中的假设是,如果我们对数据进行聚类,则正常数据将属于聚类,而异常将不属于任何聚类或属于小聚类。 我们使用以下步骤来查找和可视化异常值。
计算每个数据点与其最近的聚类中心之间的距离。 最大的距离被认为是异常的。设定一个异常值的比例outliers_fraction为40%,这样设置是因为在标准正太分布的情况下(N(0,1))我们一般认定3个标准差以外的数据为异常值,3个标准差以内的数据包含了数据集中99%以上的数据,所以剩下的1%的数据可以视为异常值。
根据异常值比例outliers_fraction,计算异常值的数量number_of_outliers。设定一个判定异常值的阈值threshold,通过阈值threshold来判定数据是否为异常值。以及对数据进行可视化(包含正常数据和异常数据)
# 计算每个数据点到其聚类中心的距离
def getDistanceByPoint(data, model):
distance = pd.Series()
for i in range(0,len(data)):
Xa = np.array(data.loc[i])
Xb = model.cluster_centers_[model.labels_[i]]
distance.set_value(i, np.linalg.norm(Xa-Xb))
return distance
#设置异常值比例
outliers_fraction = 0.4
# 得到每个点到取聚类中心的距离,我们设置了10个聚类中心,kmeans[9]表示有10个聚类中心的模型
distance = getDistanceByPoint(data_std, kmeans[9])
#根据异常值比例outliers_fraction计算异常值的数量
number_of_outliers = int(outliers_fraction*len(distance))
#设定异常值的阈值
threshold = distance.nlargest(number_of_outliers).min()
#根据阈值来判断是否为异常值
data['anomaly1'] = (distance >= threshold).astype(int)
#数据可视化
fig, ax = plt.subplots(figsize=(10,6))
colors = {
0:'blue', 1:'red'}
ax.scatter(data['principal_feature1'],data['风速'],c=data["anomaly1"].apply(lambda x: colors[x]))
plt.xlabel('principal feature1')
plt.ylabel('风速')
plt.show()
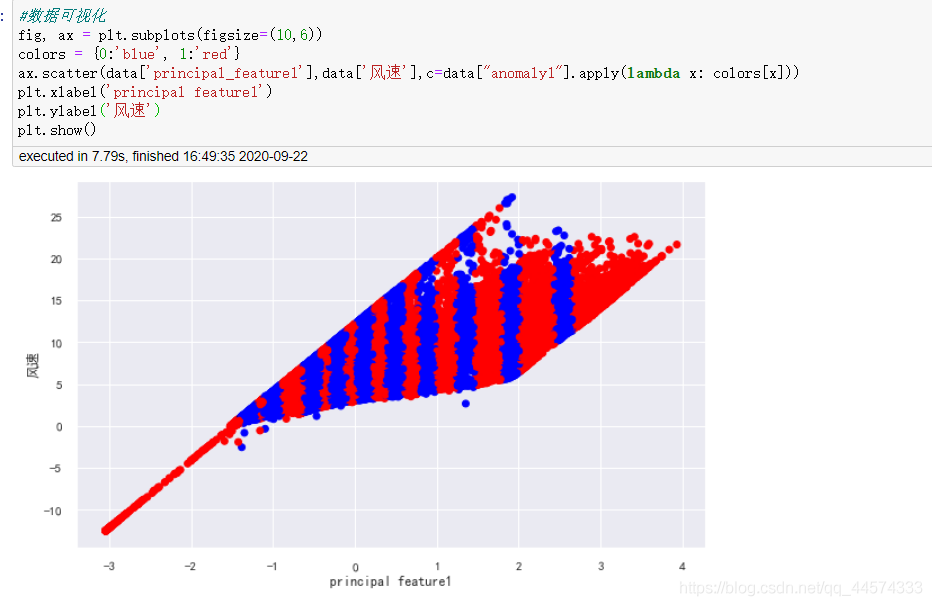
上图中红色的点即是被认定的异常值,它们大约占总数据量的40%。
下述代码也证实了这一点。
fig, ax = plt.subplots(figsize=(12,6))
a = data.loc[data['anomaly1'] == 1, ['时间戳', '风轮转速']] #anomaly
ax.plot(data['时间戳'], data['风轮转速'], color='blue', label='正常值')
ax.scatter(a['时间戳'],a['风轮转速'], color='red', label='异常值')
plt.xlabel('时间戳')
plt.ylabel('风轮转速')
plt.legend()
plt.show()
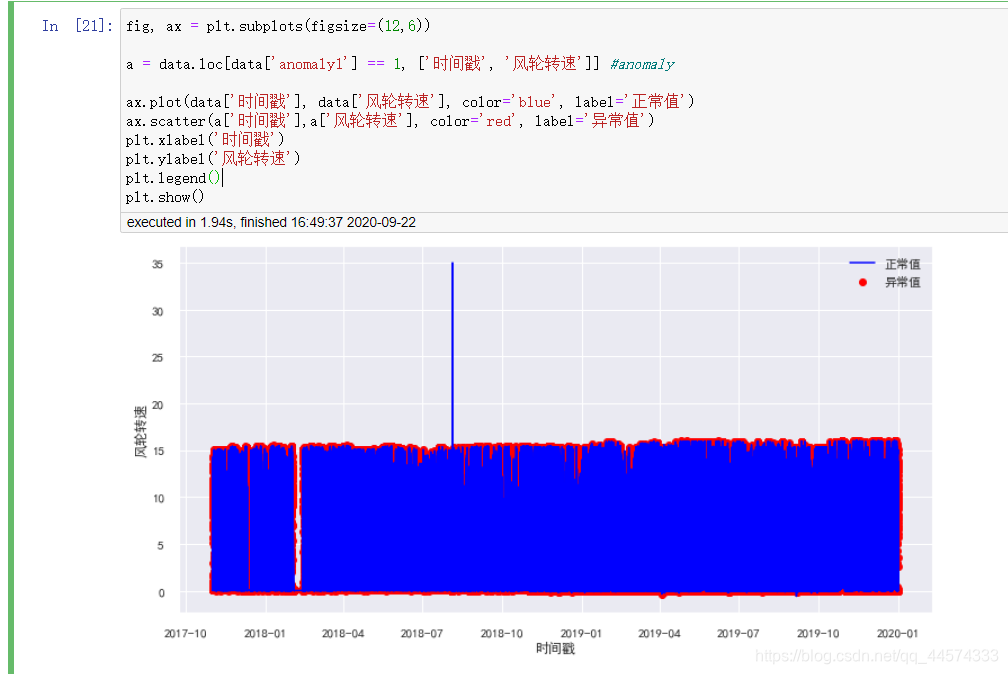
从上图可知,经过PCA和KMeans计算出的异常值,它们的风轮转速大多位于区间的最高点和最低点处,这应该是合理的。
2.2 孤立森林(IsolationForest)异常检测
IsolationForest算法它是一种集成算法(类似于随机森林)主要用于挖掘异常(Anomaly)数据,或者说离群点挖掘,总之是在一大堆数据中,找出与其它数据的规律不太符合的数据。该算法不采样任何基于聚类或距离的方法,因此他和那些基于距离的的异常值检测算法有着根本上的不同,孤立森林认定异常值的原则是异常值是少数的和不同的数据。它通常用于网络安全中的攻击检测和流量异常等分析,金融机构则用于挖掘出欺诈行为。
●当我们使用IsolationForest算法时需要设置一个异常值比例的参数contamination, 该参数的作用类似于之前的outliers_fraction。
●使用 fit 方法对孤立森林模型进行训练
●使用 predict 方法去发现数据中的异常值。返回1表示正常值,-1表示异常值。
# 训练孤立森林模型
model = IsolationForest(contamination=outliers_fraction)
model.fit(data_std)
#返回1表示正常值,-1表示异常值
data['anomaly2'] = pd.Series(model.predict(data_std))
fig, ax = plt.subplots(figsize=(10,6))
a = data.loc[data['anomaly2'] == -1, ['时间戳', '风轮转速']] #异常值
ax.plot(data['时间戳'], data['风轮转速'], color='blue', label = '正常值')
ax.scatter(a['时间戳'],a['风轮转速'], color='red', label = '异常值')
plt.legend()
plt.show()

从上图可知,使用孤立森林预测的异常值,它们的风轮转速大多位于区间的最高点或最低点处。
2.3 支持向量机(SVM)的异常检测
SVM通常应用于监督式学习,但OneClassSVM算法可用于将异常检测这样的无监督式学习,它学习一个用于异常检测的决策函数其主要功能将新数据分类为与训练集相似的正常值或不相似的异常值。
SVM使用大边距的方法,它用于异常检测的主要思想是:将数据密度较高的区域分类为正,将数据密度较低的区域分类为负
●在训练OneClassSVM模型时,我们需要设置参数nu = outliers_fraction,它是训练误差分数的上限和支持向量分数的下限,并且必须在0和1之间。基本上它代表了我们期望的异常值在我们的数据集中的比例。
●指定要在算法中使用的核类型:rbf。 它使SVM能够使用非线性函数将超空间投影到更高维度。
●gamma是RBF内核类型的参数,并控制各个训练样本的影响 - 这会影响模型的“平滑度”。
●predict 对数据进行分类,因为我们的模型是单类模型,所以返回+1或-1,-1表示是异常值,1表示是正常值。
# 训练 oneclassSVM 模型
model = OneClassSVM(nu=outliers_fraction, kernel="rbf", gamma=0.01)
model.fit(data_std)
data['anomaly3'] = pd.Series(model.predict(data_std))
fig, ax = plt.subplots(figsize=(10,6))
a = data.loc[data['anomaly3'] == -1, ['时间戳', '风轮转速']] #异常值
ax.plot(data['时间戳'], data['风轮转速'], color='blue', label = '正常值')
ax.scatter(a['时间戳'],a['风轮转速'], color='red', label = '异常值')
plt.legend()
plt.show()
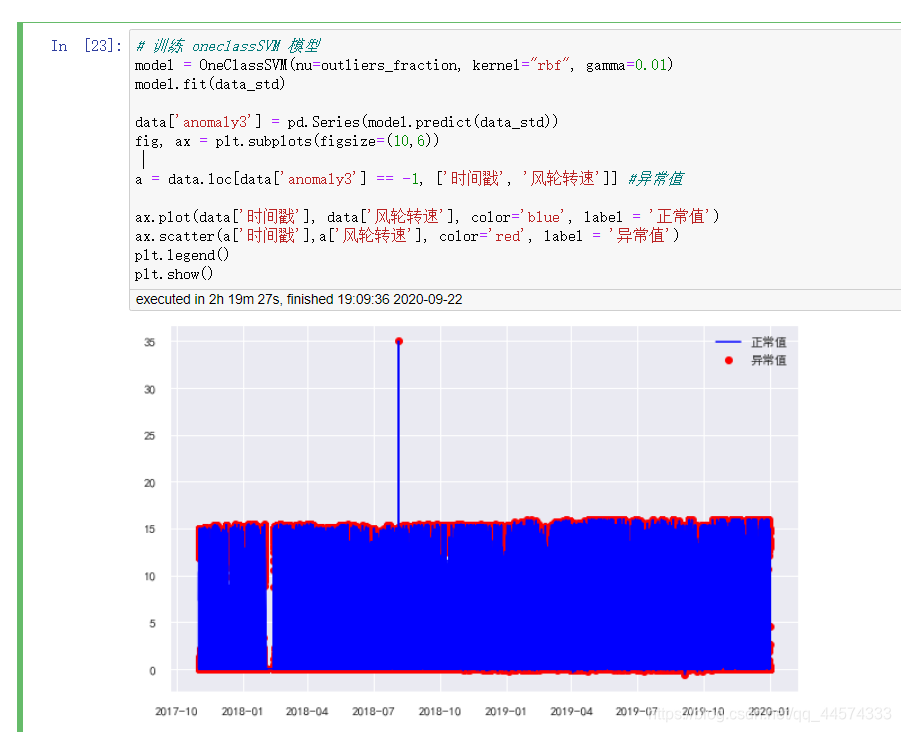
从上图可知,使用OneClassSVM预测的异常值,它们的风轮转速大多位于区间的最高点或最低点处。
2.4 基于高斯概分布的异常检测
高斯分布也称为正态分布。 它可以被用来进行异常值检测,不过我们首先要假设我们的数据是正态分布的。 不过这个假设不能适应于所有数据集。但如果我们做了这种假设那么它将会有一种有效的方法来发现异常值。
Scikit-Learn的EllipticEnvelope模型,它在假设我们的数据是多元高斯分布的基础上计算出高斯分布的一些关键参数过程。过程大致如下:
●根据前面定义的类别创建两个不同的数据集 : search_Sat_night和Search_Non_Sat_night。
●在每个类别应用EllipticEnvelope(高斯分布)。
●我们设置contamination参数,它表示我们数据集中异常值的比例。
●使用decision_function来计算给定数据的决策函数。 它等于移位的马氏距离(Mahalanobis distances)。 异常值的阈值为0,这确保了与其他异常值检测算法的兼容性。
●使用predict 来预测数据是否为异常值(1 正常值, -1 异常值)
# 基于高斯概分布的异常检测
df_class0 = data.loc[data['风轮转速'] >7, '风轮转速']
df_class1 = data.loc[data['风轮转速'] <=7, '风轮转速']
envelope = EllipticEnvelope(contamination = outliers_fraction)
X_train = df_class0.values.reshape(-1,1)
envelope.fit(X_train)
df_class0 = pd.DataFrame(df_class0)
df_class0['deviation'] = envelope.decision_function(X_train)
df_class0['anomaly'] = envelope.predict(X_train)
envelope = EllipticEnvelope(contamination = outliers_fraction)
X_train = df_class1.values.reshape(-1,1)
envelope.fit(X_train)
df_class1 = pd.DataFrame(df_class1)
df_class1['deviation'] = envelope.decision_function(X_train)
df_class1['anomaly'] = envelope.predict(X_train)
df_class = pd.concat([df_class0, df_class1])
data['anomaly4'] = df_class['anomaly']
fig, ax = plt.subplots(figsize=(10, 6))
a = data.loc[data['anomaly4'] == -1, ('时间戳', '风轮转速')]
ax.plot(data['时间戳'], data['风轮转速'], color='blue', label = '正常值')
ax.scatter(a['时间戳'],a['风轮转速'], color='red', label = '异常值')
plt.show()
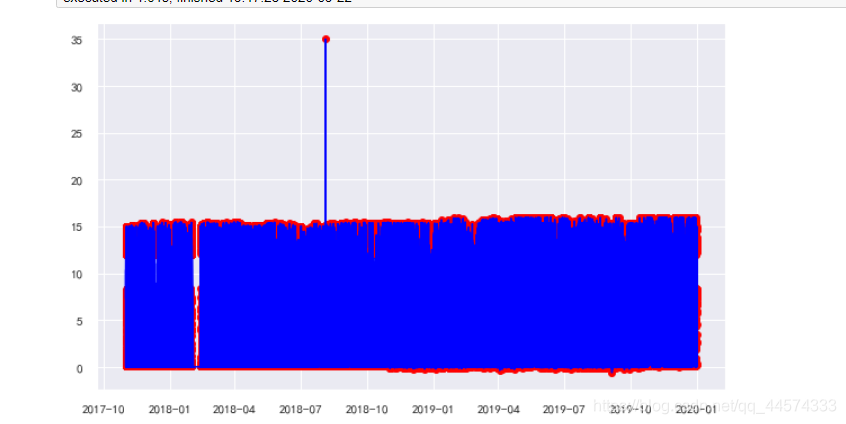
从上图可知,使用EllipticEnvelope预测的异常值,它们的风轮转速大多位于区间的最高点处,而在最低点处没有出现异常值。
到目前为止,我们已经用四种不同的方法进行了风轮数据异常检测。 因为我们的异常检测是无监督学习。 在构建模型之后,我们不知道他们的异常检测效果怎么样,因为我们没有办法可以对他们进行测试。 通常异常检测只有在实际的应用场景中才能测试出它的效果。
III “预测”提交
让我们先来看一下我们的训练集data
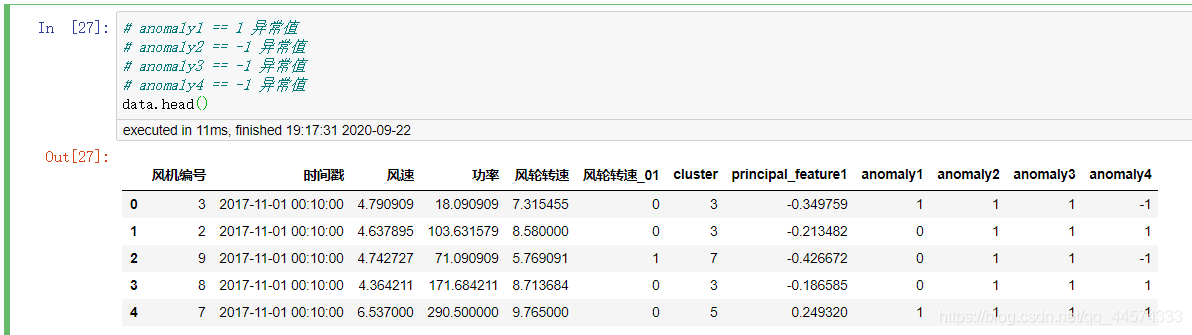
根据上述四种不同模型的异常检测我们得到了anomaly1-4的检测值,在此基础上,你可以选择投票的方式得到最终的结果“预测”,或一票决定。
data['sum'] = data['风轮转速_01'] + data['anomaly1'] + data['anomaly2'] + data['anomaly3'] + data['anomaly4']
## 注意,请选择以下两种方式的一种进行运行,直接运行将会使一票决定覆盖投票
# 投票
submit.loc[:,'label'] = data.loc[:,'sum'].map({
0:0,1:0,2:0,3:1,4:1,5:1})
# 一票决定
submit.loc[:,'label'] = data.loc[:,'sum'].map({
0:0,1:1,2:1,3:1,4:1,5:1})
最终提交,并评测
submit.to_csv('../output/baseline.csv',index=False)
submit.head()
完整ipynb代码文件和比赛数据可见Github:
https://github.com/AmangAris/Abnormal-data-identification-and-cleaning-of-wind-turbine