1.数据结构与对象:
Redis数据库里每个键值对都是由对象组成的,其中键总是一个字符串对象,值可以是字符串对象(String)、列表对象(List)、哈希对象(Hash)、集合对象(Set)、有序集合对象(ZSet)等对象的其中一种
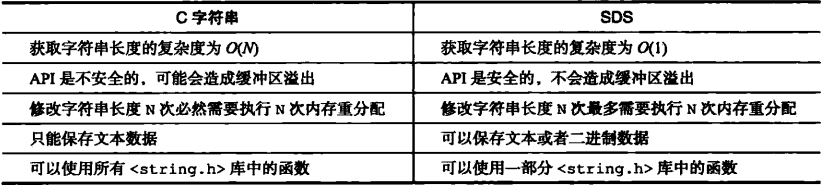
Redis采用SDS(简单动态字符串)作为字符串类型进行存储,相较C字符串类型来说,其优点明显且突出如下:
1.常熟复杂度获取字符串长度:
无需像C字符串一般对字符串进行遍历后才能获取字符串长度,它拥有自己的len区域,当需要获取字符串长度时只需读取该字符串len属性O(1)就可简洁方便的拿到字符串长度,无需如像C字符串一般将所有字符进行遍历O(n)后才能获取
2.杜绝缓冲区溢出:
很好的解决使用C字符串时产生的缓存区溢出问题,当需要进行字符拼接时,会先检查SDS的空间是否满足即将拼接字符串长度的大小,满足则拼接,如不满足就会自动扩展SDS的空间大小,使之能够装下拼接后的字符串,杜绝缓冲区溢出可能
3.减少修改字符串时带来的内存重新分配的次数:
Redis通过空间预分配策略,来减少连续执行字符串增长所需的内存分配次数
空间预分配策略:
当修改后的SDS长度小于1MB时,程序则会给该对象分配Free=len的预分配空间
当修改后的SDS长度大于1MB时,程序就会给该对象分配Free=1MB的预分配空间
Redis使用惰性空间释放来优化SDS的字符串缩短操作
惰性空间释放:
当需要缩短SDS保存的字符串时,程序并不会直接调用内存重新分配来将缩短空间回收,而是使用 Free属性来记录这段缩短空间,以便将来增长SDS字符串时使用
4.二进制保存、保证数据安全
Redis中以处理二进制的方式处理SDS键所对应的存放在Buf数组中的数据、程序不会对该数据做任何限制、过滤或假设等操作,而是将数据原样保存
5.兼容部分C字符串函数
总结:C字符串和SDS的区别:
以下是针对SDS的相应操作说明及API:
1.

2.

2.Redis持久化机制之RDB和AOF
1.为什么需要持久化?
因为Redis是一个内存数据库,它将数据库状态保存在内存中,如果不使用持久化机制,当进程退出时,数据库状态也随之消失,为了很好的保存数据库状态,我们需要持久化机制将数据库状态保存至磁盘中,从而避免数据意外丢失。
RDB持久化是将数据进行压缩,生成一个二进制压缩文件,该文件可以通过还原生成RDB文件时的数据库状态
2.生成RDB文件
两种方式:
1. save------该命令会阻塞Redis服务器进程,直到RDB文件生成完毕为止,期间服务器不能处理任何命令请求
2. bgsave---该命令则不会阻塞服务器进程,而是派生出一个子进程来生成RDB文件,主进程则继续处理其他命令请求
3.数据载入
(1)因为AOF文件更新的频率远比RDB文件要高出很多,从而数据的完整性要比后者也相对要好,所以如果在服务器开启了AOF持久化功能的时候,在载入文件时,服务器会优先使用AOF文件来还原数据库状态
(2)只有在AOF处于关闭状态时(默认处于关闭),服务器才会使用RDB文件来还原数据库状态,这时RDB文件的载入是随着Redis服务器启动而自动载入的

注释:
服务器在载入RDB文件期间都是出于阻塞状态的,直到RDB文件在完成
在执行bgsave命令期间,服务器是拒绝save和另一个bgsave命令的,服务器禁止save和bgsave命令同时执行,是为了避免主进程和子进程同时执行两个rdbSave函数调用,防止产生竞争关系
另外,bgrewriteaof和bgsave命令不能同时执行。如果
bgrewriteaof
先执行,服务器会拒绝bgsave命令;如果bgsave先执行时,服务器会等待bgsave执行完毕后再执行
bgrewriteaof
命令
原因:
bgrewriteaof和bgsave命令都是由子进程执行,如果并发,两个进程又都在执行大量的写操作,这样会影响性能,显然不是一个好场景
4.自动间隔性保存
因为bgsave是使用子进程进行保存工作,并且不会产生服务器阻塞,
所以Redis允许用户可以通过设置服务器配置来实现自动间隔性保存的功能
Redis中默认配置:
save 900 1---------------900S内,对数据库至少进行了1次修改
save 300 10
--------------300S内,对数据库至少进行了10次修改
save 60 10000
------------60S内,对数据库至少进行了10000次修改
只要满足以上三个条件之一,服务器就会执行bgsave命令,对数据库状态进行保存
Redis通过调用serverCron函数每个100毫秒对正在运行的服务器进行维护,其中一个任务就是检查数据库状态是否满足save条件,如果满足,则执行bgsave
3.RDB文件结构
第一部分REDIS,占5个字符,用于程序载入文件时,快速检测是否为RDB文件
第二部分db_version,占4个字符,是一个字符串表示的整数,记录了RDB文件的版本号
第三部分databases,为RDB文件的主要部分,包含0个或多个数据库以及各个数据库所储存的键值对数据
第四部分EOF常量,占1个字符,该常量标志着RDB文件正文结束,当程序读取到该常量是就知道载入结束
第五部分check_sum,占8个字符,一个无符号整数,保存着一个校验和,该校验和是程序通过前四部分计算而得,在载入文件时,程序会根据前四个部分计算一个校验和,再将计算得到校验和与文件中先前保存的校验和进行比较,从而确定载入文件是否损坏或者出错
注释:
databases部分可以有一个或多个,例如:
databases部分的数据结构:
第一部分SELECTDB一个常量,占1字节,告诉程序下一个读取的将是数据库号码
第二部分db_number,保存着一个数据库号码,占1、2、5字节根据号码大小决定,
第三部分key_value_pairs,保存相应数据库所有的键值对数据,包括过期的键值对数据
不带过期键值对数据结构
:
带过期键值对数据数据结构:
最近看的书有些多,总感觉不自己总结,再敲下来是很难有记忆点的,写写博客也方便复习记忆。所以这算是读后感吧,至于《Redis设计与实现2》,我只会挑一些比较容易、且现阶段理解的内容作为重点加强,对于第一部分的什么跳跃表、压缩表、字典、双端链表等等知识,可能有些深了,暂时只是了解就行。
写篇做AOF,欢迎胖友一起共勉!