一、什么是ik分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是每个字看成一个词,比如“超级喜欢不经意”会被分为“超”,“级”,“喜”,“欢”,“不”,“经”,“意”这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度切分!
二、如何使用
1.下载
各版本下载地址(建议与es和kibana版本一致):https://github.com/medcl/elasticsearch-analysis-ik/releases
2.解压至elasticsearch安装目录的plugins文件夹下。建议在此文件夹下新建ik目录,将分词器解压至这个ik文件夹下,因为也许会使用别的插件,不要混合在一起。我的解压目录/home/devops/ElasticSearch/elasticsearch-7.6.1/plugins/ik
3.重启es和kibana,在日志中发现ik分词器已经被加载:

4.使用kibana测试,进入kibana后打开开发者工具:

4.1:查看ik_smart分词器效果

4.2:查看ik_max_word分词器效果

4.3:ik_smart和ik_max_word的区别,和应用场景
ik_smart会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂(也就是最少拆分)。
ik_max_word会做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
两种分词器使用的最佳场景是:索引时用ik_max_word,在搜索时用ik_smart。
即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
5.假如我们要搜索"幸仁杰"这个关键词,我们先试试结果:

5.1:发现"幸仁杰"这个词被ik分词器分成了三个字,而这个并不是我们想要的,我们要的是准确搜索"幸仁杰",而不是所搜所有包含这三个字的文档,所以我们需要将这三个字加入到分词器的字典中。
我们打开ik分词器的解压目录,在es的plugins文件夹下的ik文件夹里,打开config目录,我的linux下的路径是/home/devops/ElasticSearch/elasticsearch-7.6.1/plugins/ik/config,打开IKAnalyzer.cfg.xml,这是ik分词器的字典,我们可以自己加入我们的扩展字典。

我们在config目录下新建一个我们自己的字典,后缀为.dic,我新建一个字典为xingrenjie.dic,里面的内容就是我们想要的词,比如"幸仁杰",每一行一个词,字典新建完后在IKAnalyzer.cfg.xml里的<entry key="ext_dict"></entry>标签里填上刚才新建的字典名,保存,然后重启es即可,如图:

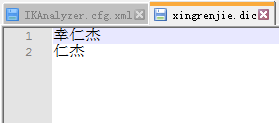

完事了保存,重启,再次打开kibana测试搜"超级喜欢幸仁杰",看分词效果:


仔细看一下,我的自定义扩展词典里把"幸仁杰"拆成了2个词,当我使用ik_smart分词时,做最少分词,所以只分成"幸仁杰"。而使用ik_max_word分词时,做最细粒度的分词,将字典里的所有可能都分了出来。所以在做项目的搜索时,我们可以根据业务需要自定义字典,想怎么分就怎么分,超级简单!!!!!