介绍
异常检测是机器学习的一个常用应用,主要针对非监督学习问题。
比如:
* 飞机引擎制造商,采集生产的引擎的各个特征,通过异常检测算法来鉴定引擎有异常的概率。
* 信用卡欺诈账户检测
* 服务器集群,异常节点监测。
高斯分布
俗称:正态分布。
两个参数定义一个分布:
1. 均值μ
2. 方差σ^2
图形:
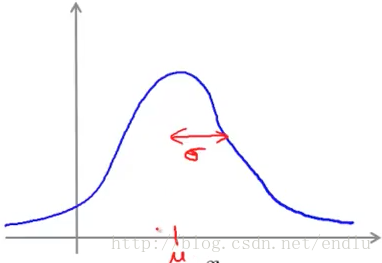
μ决定中心位置,σ决定波峰宽度。y轴为x取某值的概率。
公式:
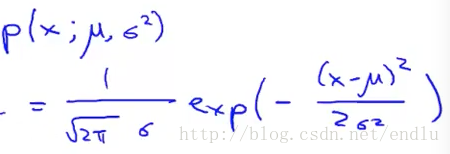
算法
利用上面提到的例子,假设我们在做飞机引擎的异常检测。引擎有m个特征X。
每个特征服从各自的高斯分布,结果概率P为:每个特征在其服从的高斯分布中的概率p(i)的乘积。
为P设定边界,超过边界的主体定义为异常主体。

算法评估
如果我们已经有一些带标签的数据,我们就可以找到标准的评估算法的方法。
1. 首先,还是将数据分为训练集、交叉验证集、测试集。
训练集为正常样本,交叉验证集和测试集均含有正常样本和异常样本。
这里建议交叉验证集和测试集的样本不要共享。
2. 因为异常样本通常比例非常小,所以仅通过准确率来评估模型是不好的。可以通过计算查准率、召回率、F1-score等指标来评估模型。
通过这种方法,我们可以直观的、有明确标准的选择使用哪些特征、P值边界等。仅需要做多种尝试,然后在交叉验证集上选择表现足够好的一种。
与逻辑回归、神经网络对比
- 如果正样本数量非常小,而负样本数量非常大时。例如上面的引擎异常检测,更适合以异常检测算法。甚至只有负样本时,我们也能非常好的拟合数据。
- 正负样本量都比较多时,适合监督学习的逻辑回归和神经网络。
- 另一种认识:异常的种类可能有非常多种,但是由于负样本数量很少。监督学习算法并不能拟合出所有情况。即,未来的异常可能未曾出现过。而当正负样本都很多时,未来的样本与见过的某样本类似。
特征选择与处理
非高斯分布特征处理
对特征绘图时,发现数据不服从高斯分布。例如,非对称分布。

此时可以使用些转换方法,例如log(x)、log(x + c)、x^a(a通常小于1)等,使其更加接近高斯分布。
特征选择
- 与之前提过的方法类似,想训练一个模型,然后利用交叉训练集检测。如果某个异常值没有被检测出来,那么我们可以分析数据,是哪些特征出了错,或者增加哪些特征可以将这类异常样本检测出来。
- 如果特征间具有相关性,例如cpu使用率和带宽占用率,如果cpu单独升高则不正常,但是如果带宽也很高时,通常是正常的业务高峰。此时,可以增加一个特征为cpu/带宽。
多元高斯分布
上面提到的cpu与带宽使用率的相关性问题,通过上面的算法,可能表现并不是很好。此时,可以使用多元高斯分布。

参数:μ均值向量,sigma协方差矩阵,为n*n。
下面是几中不同表现:μ为中心位置,Sigma主对角线为各特征标准差,其他为相关性。



基于多元高斯的异常检测
参数估计

步骤

提示
如果在实现多元高斯算法时,发现Sigma不可逆。有两种可能:
1. 没有满足m>>n。
2. 有冗余特征,例如:x1=x2 、 x3=x4+x5。去掉荣誉变量即可。

两种算法关系
数学上可以证明,第一种算法(多个p相乘)实际上是多元高斯模型算法的一种特殊情况:非对角线上的元素均为0。即,没有相关性的多元高斯。
在使用中,第一种算法更加常用。那么如果针对两种算法选择呢?
* 如果有类似cpu、带宽占用率的问题时,如果有精力自己建立新特征(关联特征),第一种算法会运行的很好。第二种算法则会自动的产生关联性。
* 第一种算法的运算量更少,特征数量很大时,也可以很好运行。但是算法二,Sigma将会是n*n矩阵,n很大时,不适用。
* 即使拥有的样本数m很小,算法一可以运行的很好。但是算法二,当m必须大于n,否则Sigma不可逆。实际中,只有m远大于n时(经验是十倍以上),才会考虑使用它。n不大,m比较大时,可以使用它,省去了手动建立而外特征的工作。