异常值检测方法可以用于寻找/判断outlier和样本极度不平衡二分类
sklearn提供了几种异常值检测方法
说明:2.7. Novelty and Outlier Detection
例子:Outlier detection with several methods
注意Novelty和Outlier的区别
novelty detection:
The training data is not polluted by outliers, and we are interested in detecting anomalies in new observations.
outlier detection:
The training data contains outliers, and we need to fit the central mode of the training data, ignoring the deviant observations.
即Novelty Detection要求所有训练数据都是正常的,不包含异常点,模型用于探测新加入的点是否异常;OneClassSVM属于此类
而Outlier Detection允许训练数据中有异常点,模型会尽可能适应训练数据而忽视异常点;EllipticEnvelope、IsolationForest、LocalOutlierFactor属于此类
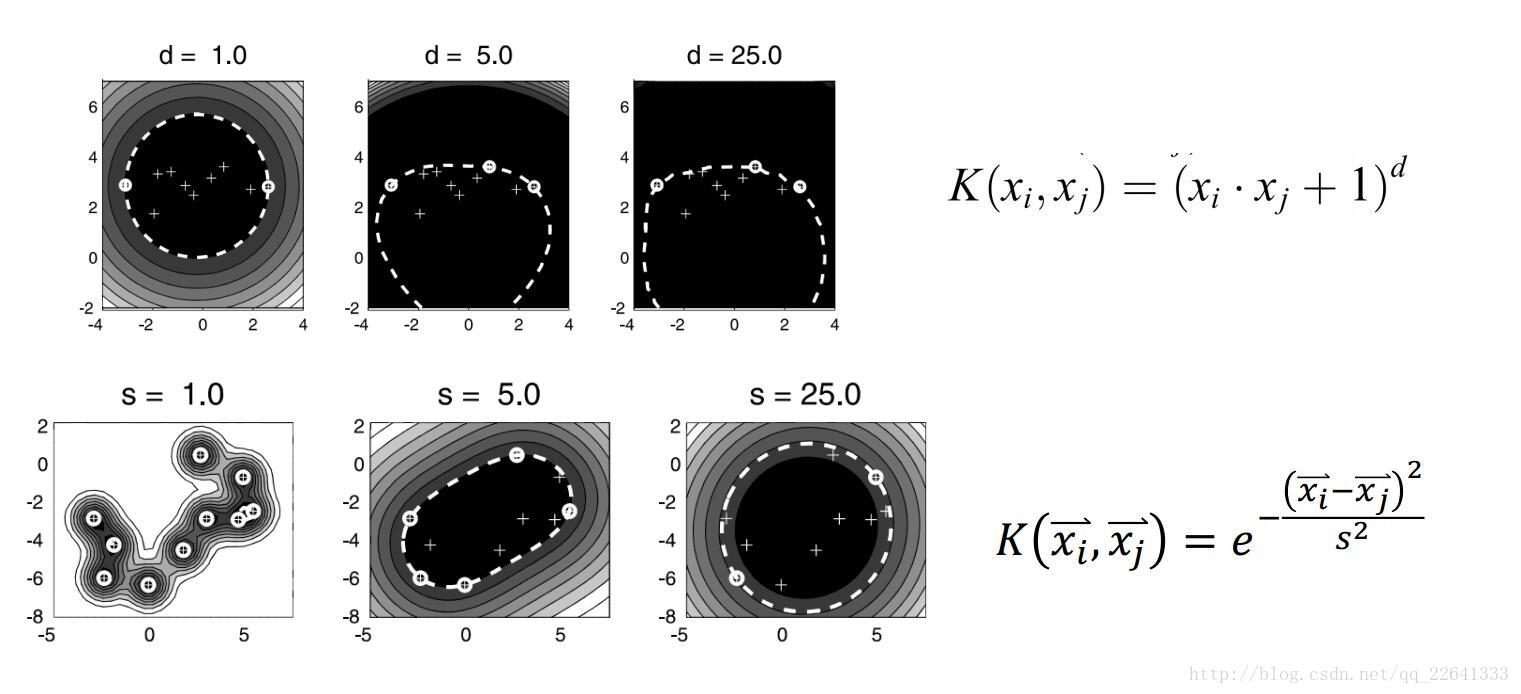
OneClassSVM
一分类SVM,等同于SVDD,sklearn中为svm.OneClassSVM,参考
无监督︱异常、离群点检测 一分类——OneClassSVM
SVDD(Support Vector Domain Description) 支持向量数据域描述(2)
sklearn官方文档-OneClassSVM
class sklearn.svm.OneClassSVM(kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1, random_state=None)
-基本思想:确定一个超球体,使得球尽可能小,而又包含了尽可能多的点,球内视为正,球外视为异常。则目标函数
通过C来调节球的大小和误分类点的惩罚程度,当点再球内或边界上则 ,边界上的称为支持向量SV,外部为BSV
对应的可以将原始数据映射到高维空间,然后在高维空间中找到这个超球体,再映射回低维度

EllipticEnvelope
鲁棒协方差估计,没太看懂,以后再补吧。大概就是画个把目标数据包进去的超椭球,其中椭球形状考虑协方差、马氏距离什么的。。。
class sklearn.covariance.EllipticEnvelope(store_precision=True, assume_centered=False, support_fraction=None, contamination=0.1, random_state=None)
-
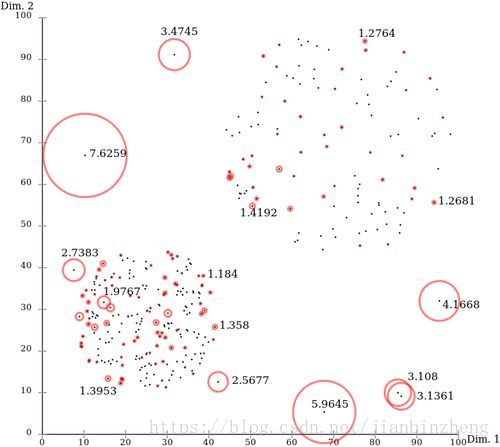
Isolation Forest
孤立森林。N棵二叉树,每棵树选取部分/全部数据,每次随机选取一个特征,随机选取一个切点(max和min之间),直到每个/相同点分配到叶子,得到每个点的路径距离d(跟到叶子结点),N棵树的d的均值即为点的距离。d越小,越异常(离得远,易被分出来);d越大,越正常。
class sklearn.ensemble.IsolationForest(n_estimators=100, max_samples=’auto’, contamination=0.1, max_features=1.0, bootstrap=False, n_jobs=1, random_state=None, verbose=0)
-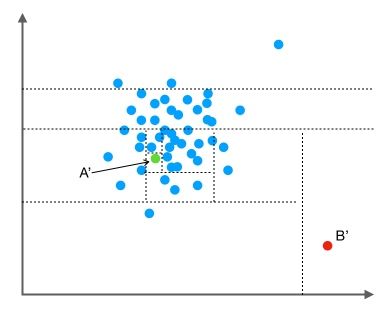

Local Outlier Factor
基于密度的算法。LOF为1,则点p的局部密度与邻居类似;若LOF<1,则其在相对密集的区域;若LOF>>1,则p与其他点比较疏远(邻居密度大,而自己密度小)
K邻近距离(K-distance):对点p最近的几个点中,第k近的点到p的距离
可达距离(reachability distance):p与o的可达距离reach-dist(p,o)为数据点o的K-邻近距离和p-o距离的较大值
局部可达密度(local reachability density):点p与K个邻近点的平均可达距离的倒数
局部异常因子(local outlier factor):如果一个数据点跟其他点比较疏远的话,那么显然它的局部可达密度就小,这是绝对局部密度。LOF算法用相对局部密度(局部异常因子),为点p的邻居的平均局部可达密度跟数据点p的局部可达密度的比值。
class sklearn.neighbors.LocalOutlierFactor(n_neighbors=20, algorithm=’auto’, leaf_size=30, metric=’minkowski’, p=2, metric_params=None, contamination=0.1, n_jobs=1)
-
上面几种方法的对比
- 对于聚合比较好的数据集,OneClassSVM不太适用

- 对于双峰的数据集,EllipticEnvelope不太适用,其他三个都可以,其中OneClassSVM易过拟合

- 对于强烈非高斯分布的,EllipticEnvelope非常不使用,其他三个可以

其他的一些异常检测方法
- 基于正态分布的一元离群点检测方法,68.3%、95.4%、99.7%
- 马氏距离
- 四分位分割
- DBSCAN
- PCA