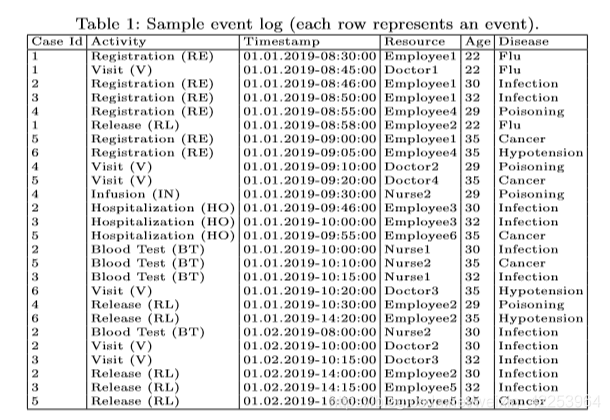
问题所在领域
过程挖掘旨在基于事件数据,以带注释的模型的形式揭示对实际过程的洞察。然而,数据通常包含个人的私人信息。例如,考虑记录与诊断和治疗活动相关的高度敏感数据的医疗保健信息系统。
提出的新方法
引入了TLKC隐私模型来进行过程挖掘,它扩展了LKC隐私模型,用于处理高维,稀疏和连续的轨迹数据。
得出的新结论
在保持案例隐私的同时,为流程发现和性能分析提供了很高的实用性。
问题引出
包含精确时间戳的的事件数据非常敏感。一些事件属性可以指个人,例如病例id可以指患者,资源可以指为患者执行活动的雇员(护士或医生)。当个人数据被明确或隐含地包括在内时,隐私问题就出现了。
隐私的两个不同视角:
- 资源视角:构成活动的个人的隐私。
- 案例视角:数据被记录和分析的个人的隐私。
通常案例视角比资源视角更重要。例如,在医疗保健领域,活动的执行者可以公开获得,然而,特定患者的情况和他的个人信息应该保密。
由于过程挖掘算法使用的数据时高维稀疏数据,因此具有高数据利用率的隐私保护具有极大的挑战性。
根据结果的相似性来看保留的效用。
医疗攻击例子:
-
案例链接攻击:例如:如果对手知道已经对患者进行了两次血液测试,则唯一匹配的案例是case2。
-
属性链接攻击:在对手已经将患者与案例匹配上时,若更进一步,将敏感信息联系起来。例如,病例2的疾病是感染,则属性也被被暴露了。属性链接攻击不一定在案例链接攻击后进行,比如,所有案例都具有相同的属性值。
假设一个可信模型,数据持有者是可信的(医院),数据接收者(过程挖掘者)是不可信的。
- 背景知识1:bk(set)。假设对手知道案例活动的子集。例如,如果对手知道{V,IN}是一个案例中已经完成的活动的子集,那么唯一匹配的案例就是案例4。因此,整个活动序列和敏感属性被公开。
- 背景知识2:bk(mult)。假设对手不仅知道案例活动的子集,还知道每个活动的频率。例如,如果对手知道【HO1,BT2】是一个案例执行的活动多集,则唯一匹配的是案例2。因此整个活动序列和敏感属性被公开。
- 背景知识3:bk(seq)。假设对手知道该案例的一系列活动。例如,如果对手知道<RE,V,HO>是一个案例执行的活动的子序列,则唯一匹配的案例是案例5。
- 背景知识4:bk(rel)。假设对手不仅知道一系列活动,还知道活动的时间差。例如案例1和案例6具有相同的活动顺序。然而,如果对手知道,对于受害者案件,在接受医生探视后,几乎花了四个小时才被释放,那唯一匹配的案例就是按比例6。该背景知识最难获得。
分析解决方法:
过程挖掘所需要的最少信息是每个案例执行的活动序列。
过程挖掘使用匿名化技术的重大挑战:
- 高可变性:事件日志轨迹的可变性很高(顺序不同,重复发生)。
- 帕累托分布:trace的分布类似于pareto分布,即很少的trace是频繁的,而很多trace是唯一的。
TLKC隐私保护模型
LKC模型:继承了K-匿名,置信度约束,(α,k)-匿名和l-多样性。
- L为背景知识的最大长度,即序列长度。
- k是k-匿名中的k。
- C是等价类中敏感属性值的置信度限制。
思想是确保事件日志中最大长度为L的背景知识被至少K个案例共享,并且在给定准标识符的情况下,推断S中任何敏感值的置信度不大于C。
TLKC模型:
- T是时间标记的准确性。比如秒,分钟,小时,天等级别的时间精度。
- L为背景知识的最大长度,即序列长度。比如set,mult,seq,rel。
- k是k-匿名中的k。
- C是等价类中敏感属性值的置信度限制。
对对手的背景知识进行了限制。
算法
效用度量:
- 最大频繁轨迹MFT:给定最小支持阈值θ,最大频繁轨迹是轨迹频率≥θ的。它比日志中的频繁轨迹集要小的多。
- 数据效用的目标是保存尽可能多的MFT。MFT的任何子空间也是一个频繁轨迹。
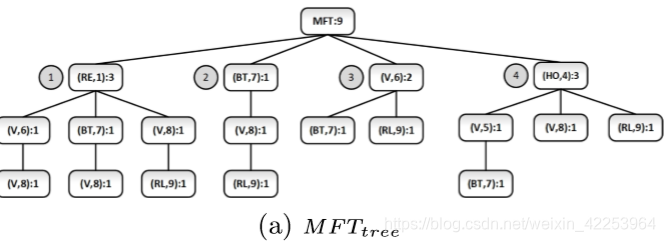
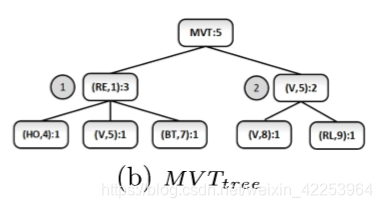
- 违反轨迹:在给定最大背景知识长度下,满足以下条件的则是违反轨迹。

- 最小违反轨迹MVT:轨迹的每个子空间都不是违反迹线.
- 贪婪函数Score:选择一个事件来抑制,使得它最大化的移除MVT的数量(隐私增益),最小化移除MFT的数量(效用损失)。PG(e)是包含事件e的MVT数,UL(e)是包含事件的MFT数。得分最高的e获胜,表示为ew。
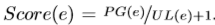
事件日志中每个违规轨迹要么是MVT,要么包含MVT。如果日志不包含MVT,那么日志中不包含违规轨迹。
算法:

应用例子:
取T =天,L = 2,K = 2,C = 50%,θ= 25%,S =疾病,bk(rel)为背景知识。

- 生成最大频繁轨迹MFT(EL)=
{<(RE,1),(V,6),(V,8)>,
<(RE,1),(BT,7),(V,8)>,
<(RE,1),(V,8),(RL,9)>,
<(HO, 4),V,5),(BT,7)>,
<(BT,7),(V,8),(RL,9)>,
<(V,6),(BT,7)>,
<(V,6),(RL,9)>,
<(HO,4),(V,8)>,
<(HO, 4),(RL,9)>},
2.生成最小违规轨迹MVT(EL) = {<(RE,1),(HO,4)>,
<(RE,1),(V,5)>,
<(RE,1),(BT,7)>,
<(V,5),(V,8) >,
<(V,5),(RL,9)>}.
- 计算事件的贪婪分数:
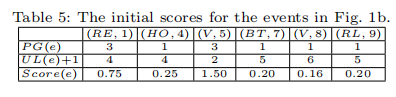
确定了获胜事件(V,5) - 删除包含获胜事件的MVT和MFT。
- 更新事件频率,重新计算,更新分数。
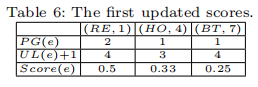
- 将获胜事件加入抑制集Sup(EL)。
- 重复4-6,直到MVT中没有节点。
最终结果是Sup(EL)={(V,5),(RE,1)}。将取消抑制事件的列表作为匿名日志返回。

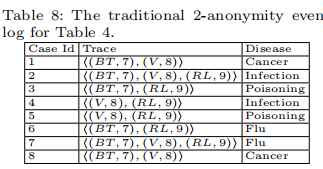
表8是传统的k-匿名的结果。它提供较弱隐私,却有更多信息被抑制。可见TLKC的优势。
效用
TLKC隐私模型会根据结果与实际结果的相似性保留数据实用性。
过程发现:
计算两个模型的fitness,precision,f1-score,作为模型的质量度量。
Fitness量化发现的模型可以重现事件日志中记录的迹线的程度.
Precision量化模型在事件日志中看不到的迹线所占的比例,
f1-score组合适应性和精度:f1-score = 2 ×精度×合适度/精度+合适度。
某些质量度量的高值并不一定意味着隐私保护算法会保留数据效用,因为目的是提供尽可能相似的结果,而不是提高发现模型的质量。