KAFKA
Kafka是一个分布式、多副本、多订阅者的日志系统(或称作“分布式消息队列系统”),可用来处理持续的数据流。各个节点之间的状态协调可通过ZooKeeper完成,Kafka常用于Web站点的日志收集、日志检索、日志监控和消息服务等。
Kafka是一个分布式、可弹性伸缩的消息队列。运行Kafka要依赖ZooKeeper。主题、分区、偏移量、生产者和消费者是Kafka中的几个核心概念。Broker是Kafka的核心,Broker有多种部署方式。
KAFKA Connector
Kafka Connector是一个可以对接其他系统进行数据传输的组件,使用该组件避免了必须编程实现生产者或消费者。
-
File Source:
File Source连接器的功能类似于kafka-console-product.sh脚本,它能够读取一个文本文件中的内容并作为生产者,把数据发送给Broker。 -
File Sink:
File Sink连接器的功能类似于kafka-console-consumer.sh脚本,它能够把接收到Broker的数据落地到文本文件中。
与Flume集成
Kafka可以作为Flume的Source或Sink。Flume的优势在于日志采集、合并或分解;Kafka是一个分布式消息队列,可用来把复杂的系统拆分解耦。
- 给Flume提供数据
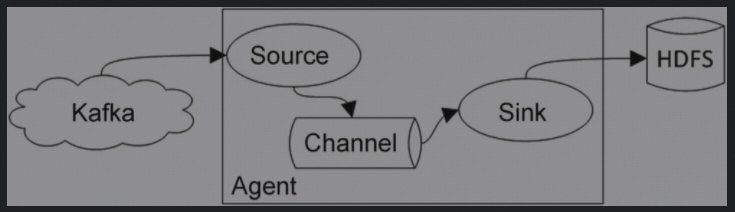
在Flume代码中实现了Kafka的数据源功能(只需要定义一个Flume conf文件就可以实现):
# Name the components on this agent
a1.sources = kafkaSource
a1.channels = memoryChannel
a1.sinks = hdfsSink
# define kafka data source.
a1.sources.kafkaSource.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.kafkaSource.zookeeperConnect=slave01:2182
a1.sources.kafkaSource.topic=slave01_weblog
a1.sources.kafkaSource.groupId=flume
a1.sources.kafkaSource.kafka.consumer.timeout.ms=100
a1.sources.kafkaSource.migrateZookeeperOffsets = false
a1.sources.kafkaSource.kafka.consumer.auto.offset.reset = earliest
# Use a channel which buffers events in memory
a1.channels.memoryChannel.type=memory
a1.channels.memoryChannel.capacity=1000
a1.channels.memoryChannel.transactionCapacity=100
# the sink of hdfs
a1.sinks.hdfsSink.type=hdfs
a1.sinks.hdfsSink.hdfs.path=hdfs://master:9000/flume-log/kafka
a1.sinks.hdfsSink.hdfs.writeFormat=Text
a1.sinks.hdfsSink.hdfs.fileType=DataStream
# Bind the source and sink to the channel
a1.sources.kafkaSource.channels = memoryChannel
a1.sinks.hdfsSink.channel = memoryChannel
- 从Flume中获取数据
Flume Sink中的数据可以作为生产者提供给Kafka
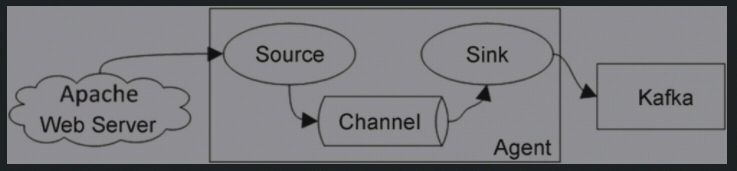
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = master
a1.sources.r1.port = 41414
# Describe the sink
a1.sinks.k1.type =file_roll
a1.sinks.k1.sink.directory=/home/hadoop/bigdata/flume/myconf/fileroll_output
a1.sinks.k1.sink.pathManager.extension=dat
a1.sinks.k1.sink.pathManager.prefix=avro
a1.sinks.k1.sink.rollInterval=3000
a1.sinks.k1.channel = c1
#设置Kafka接收器
a1.sinks.k2.type=org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
a1.sinks.k2.brokerList=slave01:9092
#设置Kafka的Topic
a1.sinks.k2.topic=newtest
#设置序列化方式
a1.sinks.k2.serializer.class=kafka.serializer.StringEncoder
a1.sinks.k2.channel = c1
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c1.keep-alive = 60
# Bind the source and sink to the channel
a1.sources.r1.channels = c1