目录
1.Mycat内置的常用分片规则
分片规则4大类:范围、列表、哈希、混合上面的几种
(1)分片枚举(列表分片)
通过在配置文件中配置可能的枚举id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则,配置如下:

function分片函数中配置说明:
- I% : io.mycat.route.function.PartitionByFileMap
- mapFile标识配置文件名称;
- type默认值为0,0表示Integer,非零表示String;
- defaultNode默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点为第几个数据节点。
默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点
如果不配置默认节点(defaultNode值小于0表示不配置默认节点),碰到不识别的枚举值就会报错。
like this: can't find datanode for sharding column:column_name val:ffffffff
- sharding-by-enum.txt放置在conf/下,配置内容示例:
10000=0 #字段值为10000的放到0号数据节点
10010=1
示例:
客户表 t_customer
CREATE TABLE t_customer(
id BIGINT PRIMARY KEY,
name VARCHAR(100) not NULL,
province int not null
);
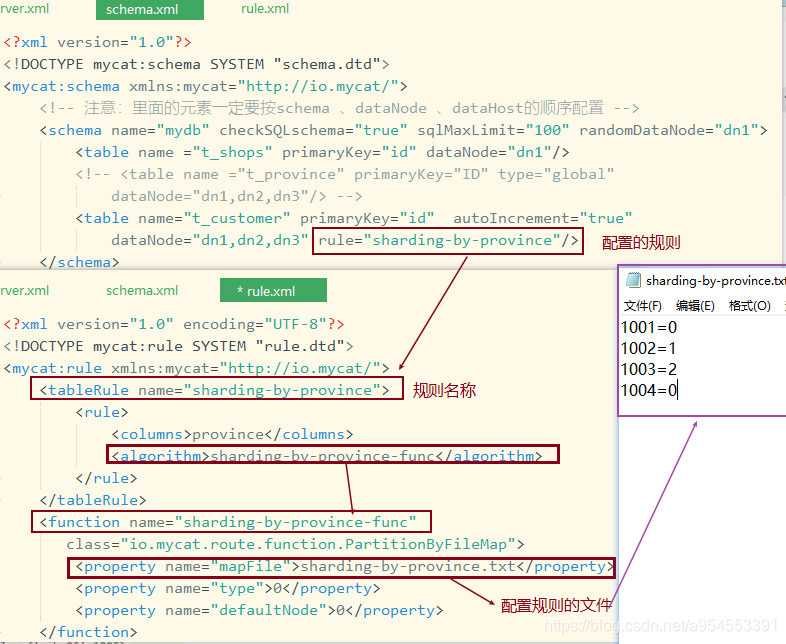
- 按省份进行分片,schema.xml配置
<table name="t_customer" primaryKey="id" autoIncrement="true"
dataNode="dn1,dn2,dn3" rule="sharding-by-province"/>
- 分片规则配置rule.xml文件
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="sharding-by-province">
<rule>
<columns>province</columns>
<algorithm>sharding-by-province-func</algorithm>
</rule>
</tableRule>
<function name="sharding-by-province-func"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">sharding-by-province.txt</property>
<property name="defaultNode">0</property>
</function>
</mycat:rule>
- sharding-by-province.txt放置在conf/下,配置内容:
1001=0
1002=1
1003=2
1004=0
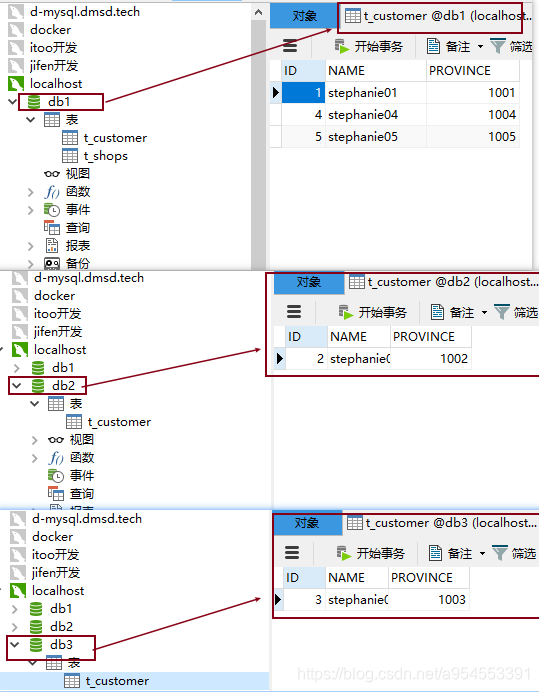
- 插入数据测试:
insert int t_customer(name,province) values('stephanie01',1001);
insert int t_customer(name,province) values('stephanie02',1002);
insert int t_customer(name,province) values('stephanie03',1003);
insert int t_customer(name,province) values('stephanie04',1004);
insert int t_customer(name,province) values('stephanie05',1005);
如果没有设置主键值生成,则用下面的插入语句:
insert into t_customer(id,name,province) values(1,'stephanie01',1001);
insert into t_customer(id,name,province) values(2,'stephanie02',1002);
insert into t_customer(id,name,province) values(3,'stephanie03',1003);
insert into t_customer(id,name,province) values(4,'stephanie04',1004);
insert into t_customer(id,name,province) values(5,'stephanie05',1005);
测试
-
配置schema.xml和rule.xml文件
-
输入sql语句测试
-
结果:按照配置的分片规则,数据插入到了不同的数据库中。
(2)范围分片
此分配是用于,提前规划好分片字段某个范围属于哪个分片
<tableRule name="range-sharding">
<rule>
<columns>user_id</columns>
<algorithm>range-long</algorithm>
</rule>
</tableRule>
<function name="range-long" class ="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">range-partition.txt</property>
<property name="defaultNode">0</property>
</function>
配置说明:
- mapFile代表配置文件路径
- defaultNode超过范围后的默认节点。
所有的节点配置都是从0开始,及0代表节点1,
mapFile中的定义规则:
start <= range <= end.
range start-end=data node index
K=1000,M=10000.
配置示例:
0-500M=0
500M-1000M=1
1000M-1500M=2
或
0-10000000=0
10000001-20000000=1
示例:
在mycat中定义分片表
- schema.xml配置
<table name="t_company" primaryKey="id" autoIncrement="true"
dataNode="dn1,dn2,dn3" rule="range-sharding-by-members-count"/>
rule.xml配置
<tableRule name="range-sharding-by-members-count">
<rule>
<columns>province</columns>
<algorithm>range-members-count</algorithm>
</rule>
</tableRule>
<function name="range-members-count" class=
"io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">company-range-partition.txt</property>
<property name="defaultNode">0</property>
</function>
company-range-partition.txt中分片定义
0-10=0
11-50=1
51-100=2
101-1000=0
1000-9999=1
10000-9999999=2
创建表
CREATE TABLE t_company(
id BIGINT PRIMARY KEY,
name varchar(100) not nu11,
members int not nu11
);
测试
INSERT INTO t_company(name,members) VALUES('company01',10);
INSERT INTO t_company(name,members) VALUES('company01',20);
INSERT INTO t_company(name,members) VALUES('company01',200);
(3)按日期范围分片
此规则为按日期进行分片
<tableRule name="order-sharding-by-date">
<rule>
<columns>order_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date"
class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">YYYY-MM-dd</property>
<property name="sBeginDate">2019-01-01</property>
<property name="sEndDate">2020-03-01</property>
<property name="sPartionDay">20</property>
</function>
配置说明:
- columns:标识将要分片的表字段
- algorithm:分片函数
- dateFormat:日期格式
- sBeginDate:开始日期
- sEndDate:结束日期
- sPartionDay:分区天数,即默认从开始日期算起,分隔10天一个分区
sBeginDate,sEndDate配置情况说明 :
- sBeginDate,sEndDate都有指定
此时表的dataNode数量的>=这个时间段算出的分片数,否则启动时会异常:
Exception in thread ”main” java.1ang.ExceptionInInitializerError
at io.mycat.Mycatstartup.main(MycatStartup.java:53)
Caused by: io.mycat.config.util.ConfigException: Il1egal table conf : table [ T_ORDER ] rule function [ shardi partition size : 4 > table datanode size : 3, please make sure table datanode size = function partition size
如果配置了sEndDate则代表数据达到了这个日期的分片后循环从开始分片插入。
- 没有指定sEndDate的情况
数据分片将依次存储到dataNode上,数据分片随时间增长,所需的dataNode数也随之增长,当超出了为该表配置的dataNode数时,将得到如下异常信息:
[SQL]
INSERT INTO t_order(order_time,customer_id,order_amount) VALUES ('2020-02- 05',1001,203);
[Err] 1064 - Can't find a valid data node for specified node index :T_ORDER -> ORDER_TIME -> 2020-02-05 -> Index : 3
示例:
server.xml
<table name="t_order" primaryKey="order_id" autoIncrement="true"
dataNode="dn1,dn2,dn3" rule="range-sharding-by-date"/>
rule.xml
<tableRule name="order-sharding-by-date">
<rule>
<columns>order_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date"
class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">YYYY-MM-dd</property>
<property name="sBeginDate">2019-01-01</property>
<property name="sEndDate">2020-03-01</property>
<property name="sPartionDay">20</property>
</function>
创建表
CREATE TABLE t_order (
order_id BIGINT PRIMARY KEY,
order_time DATETIME.
customer_id BIGINT,
order_amount DECIMAL(8,2)
);
测试:
INSERT INTO t_order(order_time,customer_id,order_amount) VALUES ('2019-01-05',1001,201);
INSERT INTO t_order(order_time,customer_id,order_amount) VALUES ('2019-01-25',1001,202);
INSERT INTO t_order(order_time,customer_id,order_amount) VALUES ('2019-02-15',1001,203);
INSERT INTO t_order(order_time,customer_id,order_amount) VALUES ('2019-03-15',1001,203);
(4)自然月分片
按月份列分区,每个自然月一个分片。
<tableRule name="order-sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-month</algorithm>
</rule>
</tableRule>
<function name="sharding-by-month"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">YYYY-MM-dd</property>
<property name="sBeginDate">2019-01-01</property>
</function>
配置说明:
- columns:分片字段,字符串类型
- dateFormat:日期字符串格式,默认为yyyy-MM-dd·sBeginDate:开始日期,无默认值
- sEndDate:结束日期,无默认值
- 节点从0开始分片
使用场景:
场景1:默认设置(不指定sBeginDate、sEndDate)
节点数量必须是12个,对应1月~12月
- ”2017-01-01”=节点0
- ”2018-01-01”=节点0
- ”2018-05-01”=节点4
- ”2019-12-01”=节点11
场景2:仅指定sBeginDate
sBeginDate = ”20/17-01-01”
该配置表示”2017-01月”是第0个节点,从该时间按月递增,无最大节点
- 2014-01-01”=未找到节点
- ”2017-01-01”=节点0
- “2017-12-01”=节点11Ⅰ
- ”2018-01-01”=节点12
- ”2018-12-01”=节点23
场景3:指定sBeginDate=1月、sEndDate=12月
sBeginDate = ”2015-01-01” sEndDate = ”2015-12-01”
该配置可看成与场景1一致。
- ”2014-01-01”=节点0
- ”2014-02-01”=节点1
- ”2015-02-01”=节点1
- ”2017-01-01”=节点0
- ”2017-12-01”=节点11
- ”2018-12-01”=节点11
场景4:
sBeginDate = ”2019-01-01”sEndDate = ”2019-03-01”
该配置表示只有3个节点;很难与月份对应上;平均分散到3个节点上
(5)取模
此规则为对应分片字段进行十进制运算,来分片数据。
<tableRule name="mod-sharding">
<rule>
<columns>user_id</columns>
<algorithm>mod-fun</algorithm>
</rule>
</tableRule>
<function name="mod-fun"
class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
配置说明:
- count指明dataNode的数量,是求模的基数
此种在批量插入时可能存在批量插入单事务插入多数据分片,增大事务一致性难度。
(6)取模范围分片
此规则是取模运算与范围约束的结合,主要为了后续数据迁移做准备,即可以自主决定取模后数据的节点分布。
<tableRule name="sharding-by-pattern">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-pattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-pattern"
class="io.mycat.route.function.PartitionByPattern">
<property name="patternValue">256</property>
<property name="defaultNode">2</property>
<property name="mapFile">partition-pattern.txt</property>
</function>
partition-pattern.txt
1-32=0 #余数为1-32的放到数据节点0上
33-64=1
65-96=2
97-128=3
129-160=4
161-192=5
193-224=6
225-256=7
0-0=7
配置说明:
- patternValue即求模基数
- defaoultNode默认节点,如果配置了默认节点,如果id非数据,则会分配在defaoultNode默认节点·
- mapFile指定余数范围分片配置文件
(7)二进制取模范围分片
本条规则类似于十进制的求模范围分片,区别在于是二进制的操作,是分片列值的二进制低10位&1111111111。此算法的优点在于如果按照10进制取模运算,在连续插入1-10时候1-10会被分到1-10个分片,增大了插入的事务控制难度,而此算法根据二进制则可能会分到连续的分片,减少插入事务控制难度。
二进制低10&1111111111的结果是0-1023一共是1024个值,按范围分成多个连续的片(最大1024个片)
<tableRule name=”rulel”>
<rule>
<columns>user_id</columns>
<algorithm>func1</a1gorithm>
</rule>
</tableRule>
<function name=”func1” class=”io.mycat. route.function.PartitionByLong”>
<property name=”partitionCount”>2,11</property>
<property name=”partitionLength”>256,512</property>
</function>
配置说明:
- partitionCount分片个数列表。
- partitionLength分片范围列表
分区长度:默认为最大2^n=1024,即最大支持1024分区
约束:
- count,length两个数组的长度必须是一致的。
- 1024 = sum((count[i] * length[i])) , count和length两个向量的点积值恒值等于1024
用法例子:
本例的分区策略:希望将数据水平分成3份,前两份各占25%,第三份占50%。(本例非均匀分区)
// |<------1024-----> |
// |<---256--->|<---256--->|<---512--->
// | partition0 | partition1 | partition2 |
// |共2份,故count[0]=2|共1份,故count[1]=1|
如果需要平均分配设置:平均分为4分片,partitionCount*partitionLength=1024
<function name=”func1” class=”io.mycat. route.function.PartitionByLong”>
<property name=”partitionCount”>4</property>
<property name=”partitionLength”>256</property>
</function>
(8)范围取模分片
先进行范围分片计算出分片组,组内再求模。
优点可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题。综合了范围分片和求模分片的优点,分片组内使用求模可以保证组内数据比较均匀,分片组之间是范围分片可以兼顾范围查询。
最好事先规划好分片的数量,数据扩容时按分片组扩容,则原有分片组的数据不需要迁移。由于分片组内数据比较均匀,所以分片组内可以避免热点数据问题。
<tableRule name=”auto-sharding-rang-mod”>
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<fuịction name=”rang-mod” class=”io.mycat.route.function. PartitionByRangeMod”> <property name=”mapFile”>partition-range-mod. txt</property>
<property name=”defaultNode”>21</property>
</function>
配置说明:
- mapFile配置文件路径
- defaultNode超过范围后的默认节点顺序号,节点从0开始。
partition-range-mod.txt
以下配置一个范围代表一个分片组,=号后面的数字代表该分片组所拥有的分片的数量。
0-200M=5 //代表有5个分片节点
200M1-400M=1
400M1-600M=4
600M1-800M=4
800M1-1000M=6
(9)一致性hash
一致性hash算法有效解决了分布式数据的扩容问题。
<tablerule name=”sharding-by-murmur”>
<rule>
<columns>user_id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name=”murmur” class=”io.mycat.route.function.PartitionByMurmurHash”>
<!--默认是0-->
<property name=”seed”>0</property>
<!--要分片的数据库节点数量,必须指定,否则没法分片-->
<property name=”count”>2</property>
<!--一个实际的数据库节点被映射为多少个虚拟节点,默认是160-->
<property name=”virtualBucketTimes”>160</property>
<!--
<property name=”weightMapFile”>weightMapFile</property>
节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替-->
<!--
<property name=”bucketMapPath”>/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmurhash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西-->
</function>
(10)应用指定
此规则是在运行阶段有应用自主决定路由到那个分片。
<tableRule name=”sharding-by-substring”>
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRu1e>
<function name=”sharding-by-substring”
class=”io.mycat.route.function.PartitionDirectBySubString”>
<property name=”startIndex”>0</property><!-- zero-based -->
<property name=”size”>2</property>
<property name=”partitionCount”>8</property>
<property name=”defau1tPartition”>0</property>
</function>
配置说明:
此方法为直接根据字符子串(必须是数字)计算分区号(由应用传递参数,显式指定分区号)。
例如:id=05-100000002
在此配置中代表根据id中从startIndex=0,开始,截取siz=2位数字即05,05就是获取的分区,如果没传默认分配到defaultPartition
(11)截取字符ASCII求和求模范围分片
此种规则类似于取模范围约束,只是计算的数值是取前几个字符的ASCII值和,再取模,再对余数范围分片。
<tableRule name=”sharding-by-prefixpattern”>
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-prefixpattern</algorithm>
</ru1e>
</tableRule>
<function name=”sharding-by-pattern”
class=”io.mycat.route.function.PartitionByPrefixPattern”>
<property name=”patternValue”>256</property>
<property name=”prefixLength”>5</property>
<property name=”mapFile”>partition-pattern.txt</property>
</function>
partition-pattern.tx
range start-end =data node index
#ASCII
#8-57=0-9阿拉伯数字
#64、65-90=@、A-Z
#97-122=a-z
1-4=0 #余数1-4的放到0号数据节点
5-8=1
9-12=2
13-16=3
17-20=4
21-24=5
25-28=6
29-32=7
0-0=7
配置说明:
- patternValue即求模基数。
- prefixLength ASCII截取的位数,求这几位字符的ASCII码值的和,再求余patternValue
- mapFile配置文件路径,配置文件中配置余数范围分片规则。
2.主键值生成
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。
CREATE TABLE t_customer(
id BIGINT PRIMARY KEY,
name varchar(100) not nul1,
province int not nu11
);
<table name=”t_customer” primaryKey=”id” autoIncrement=”true”
dataNode=”dn1,dn2,dn3” rule=”sharding-by-province” />
为此,MyCat提供了全局sequence,并且提供了包含本地配置和数据库配置等多种实现方式。
(1)本地文件方式
原理:此方式MyCAT将sequence配置到文件中,当使用到sequence中的配置后,MyCAT会更新conf中的sequence_conf.properties文件中sequence当前的值。
配置方式:
- 在sequence_conf.properties文件中做如下配置:
GLOBAL.HISIDS=
GLOBAL.MINID=1001
GLOBAL.MAXID=1000000000
GLOBAL. CURID=1000
其中HISIDS表示使用过的历史分段(一般无特殊需要可不配置),MINID表示最小ID值,MAXID表示最大ID值,CURID表示当前ID值。
- server.xml中配置:
<system><property name=”sequnceHand1erType”>0</property></system>
注:sequnceHandlerType需要配置为0,表示使用本地文件方式。
使用示例:
insert into tablel(id,name) values(next value for MYCATSEQ_GLOBAL, 'test');
缺点:当MyCAT重新发布后,配置文件中的sequence会恢复到初始值。
优点:本地加载,读取速度较快。
【操作】
为表配置主键自增的序列:
规则:在sequence_conf.properties中配置以表名为名的序列
T_COMPANY.HISIDS=
T_COMPANY.CURID=501
T_COMPANY.MINID=1
T_COMPANY.MAXID=100
schema.xml中写入:
<table name="t_company" primaryKey="id" autoIncrement="true"
dataNode="dn1,dn2,dn3" rule="range-sharding-by-members-count"/>
数据库测试:
CREATE TABLE t_company(
id BIGINT PRIMARY KEY,
name varchar(100) not NULL,
members int not NULL
);
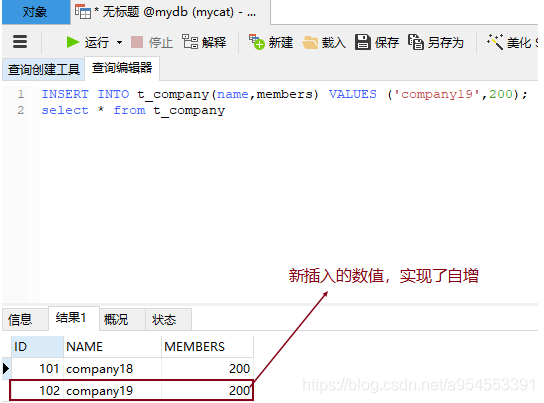
INSERT INTO t_company(name,members) VALUES ('company19',200);
select * from t_company
测试结果:
(2)数据库方式
原理
在数据库中建立一张表,存放sequence名称(name),sequence当前值(current_value),步长(incrementint类型,每次读取多少个sequence)等信息;
Sequence获取步骤:
- 当初次使用该sequence时,根据传入的sequence名称,从数据库这张表中读取current_value,和increment到MyCat中,并将数据库中的current_value设置为原current_value值+increment值。
- MyCat将读取到current_value+increment作为本次要使用的sequence值,下次使用时,自动加1,当使用increment次后,执行步骤1)相同的操作。
MyCat负责维护这张表,用到哪些sequence,只需要在这张表中插入一条记录即可。若某次读取的sequence没有用完,系统就停掉了,则这次读取的sequence剩余值不会再使用。
配置方式:
server.xml 配置 :
<system><property name=”sequnceHand1erType”>1</property></system>
注:sequnceHandlerType需要配置为1,表示使用数据库方式生成sequence。
数据库配置:
1)创建MYCAT_SEQUENCE表
--创建存放sequence的表
DROP TABLE IF EXISTS MYCAT_SEQUENCE;
--namesequence名称
current_value Wvalue
--increment增长步长!可理解为mycat在数据库中一次读取多少个sequence.当这些用完后,下次再从数据库中读取。
CREATE TABLE MYCAT_SEQUENCE (
name VARCHAR(50) NOT NULL,
current_value INT NOT NULL,
increment INT NOT NULL DEFAULT 100,
PRIMARY KEY(name));
--插入一条sequence
INSERT INTO MYCAT_SEQUENCE(name ,current_value,increment) VALUES ('GLOBAL', 100000, 100);
2)创建相关function
--获取sequence当前值(返回当前值,增量)的函数
DROP FUNCTION IF EXISTS mycat_seq_currva1;
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50))
RETURNS varchar(64)
BEGIN
DECLARE retval VARCHAR(64);
SET retval='-999999999,nu11';
SELECT concat(CAST(current_value AS CHAR),',',CAST(increment AS CHAR)) INTO retval
FROM MYCAT_SEQUENCE
WHERE name = seq_name;
RETURN retval;
END;
--设置sequence值的函数
DROP FUNCTION IF EXISTS mycat_seq_setval;
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),value INTEGER) RETURNS varchar(64)
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = value
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END;
--获取下一个sequence值
DROP FUNCTION IF EXISTS mycat_seq_nextva1;
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50))
RETURNS varchar(64)
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END;
注意:MYCAT_SEQUENCE表和以上的3个function,需要放在同一个节点上。function直接在具体点的数据库上执行,如果执行的时候报:
you might want to use the less safe log_bin_trust_function_creators variable
需要对数据库做如下设置:
windows Tmy.ini[mysqld])o.Elog_bin_trust_function_creators=1
linux T/etc/my.cnf Tmy.ini[mysqld])o.Elog_bin_trust_function_creators=1
修改完后,即可在mysql数据库中执行上面的函数。
3)sequence_db_conf.properties相关配置,指定sequence相关配置在哪个节点上:
例如:
USER_SEQ=test_dn1
使用示例:
insert into tablel(id,name) values(next value for MYCATSEQ_GLOBAL,'test');
配置表的主键自增使用序列:
- 在序列定义表中增加名字为表名的序列:
INSERT INTO MYCAT_SEQUENCE(name,current_value,increment) VALUES ('T_COMPANY', 1,100) ;
- 在sequence_db_conf.properties中增加表的序列配置
T_COMPANY=dn1
- 主键自增就可以使用了
<table name=”t_company” primaryKey=”id” autoIncrement=”true”
dataNode=”dn1,dn2,dn3” rule=”range-sharding-by-members-count” />
sql语句测试:
INSERT INTO t_company (name, members) VALUES('company08',200);
select * from t_company;
(3)本地时间戳方式
原理:
ID=64位二进制:42(毫秒)+5(机器ID)+5(业务编码)+12(重复累加)
换算成十进制为18位数的long类型,每毫秒可以并发12位二进制的累加。
使用方式:
配置server.xml
<property name=”sequnceHand1erType”>2</property>
在 mycat下配置: sequence_time_conf.properties
WORKID=0-31 任意整数 表示机器id(或mycat实例id)
DATAACENTERID=0-31 任意整数 E8业务编码
多个mycat节点下每个mycat配置的WORKID,DATAACENTERID不同,组成唯一标识,总共支持32*32=1024种组合。
ID示例:56763083475511。
主键自增配置
<table name=”t_company” primaryKey=”id” autoIncrement=”true” dataNode=”dn1,dn2,dn3” rule=”range-sharding-by-members-count” />
INSERT INTO t_company(name ,members) VALUES ('company09',200); select * from t_company;
(4)分布式ZK ID生成器
<property name=”sequnceHand1erType”>3</property>
配置
1)Zk的连接信息统一在myid.properties的zkURL属性中配置。只需关注zkURL。
loadZk=false
zkURL=127.0.0.1:2181
clusterId=mycat-cluster-1
myid=mycat_fz_01
clusterSize=3
clusterNodes=mycat_fz_01,mycat_fz_02,mycat_fz_04
#server booster booster install on db same server,will reset all mincon to :
type=server
boosterDataHosts=dataHostl
基于ZK与本地配置的分布式ID生成器,ID结构:long64位,ID最大可占63位:
- |currenttimemilis(微秒时间戳38位,可以使用17年)
- |clusterld(机房或者ZKid,通过配置文件配置5位)
- |instanceld(实例ID,可以通过ZK或者配置文件获取,5位)
- |threadld(线程ID,9位)
- |increment(自增,6位)
- 一共63位,可以承受单机房单机器单线程1000*(2^6)=640000的并发。
- 无悲观锁,无强竞争,吞吐量更高
2)配置文件: sequence_distributed_conf.properties , 只需配置 : INSTANCEID=ZK 9JE)ZK Ei 取InstancelD。(可以通过ZK获取集群(机房)唯一InstancelD,也可以通过配置文件配置InstancelD)
测试:
<table name=”t_company” primaryKey=”id” autoIncrement=”true”
dataNode=”dn1,dn2,dn3” rule=”range-sharding-by-members-count” />
sql语句测试:
INSERT INTO t_company (name, members) VALUES('company12',200);
select * from t_company;
(6)last_insert_id()问题
我们配置分片表主键自增。
<table name=”t_company” primaryKey=”id” autoIncrement=”true”
dataNode=”dn1,dn2,dn3”
rule=”range-sharding-by-members-count” />
如需通过selectlast_insert_id()来获得自增主键值,则表定义中主键列需是自增的AUTO_INCREMENT:
CREATE TABLE t_company(
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name varchar(100) not nul1,
members int not nu11
);
如果没有指定AUTO_INCREMENT,则selectlast_insert_id()获取不到刚插入数据的主键值。
CREATE TABLE t_company(
id BIGINT PRIMARY KEYI
name varchar(100) not nul1,
members int not nul1
);
Mybatis中新增记录后获取last_insert_id的示例:
<insert id=”insert” parameterType=”com. study.mike.user.model.User”>
insert intp t_user (user_name,1ogin_name, 1ogin_pwd, role_id)
values(#(userName),#(1oginName),#(1oginPwd),#(roleId))
<selectKey resultType=”java.lang.Long” order=”AFTER” keyProperty=”id”>
select last_insert_idO as id
</selectKey>
</insert>