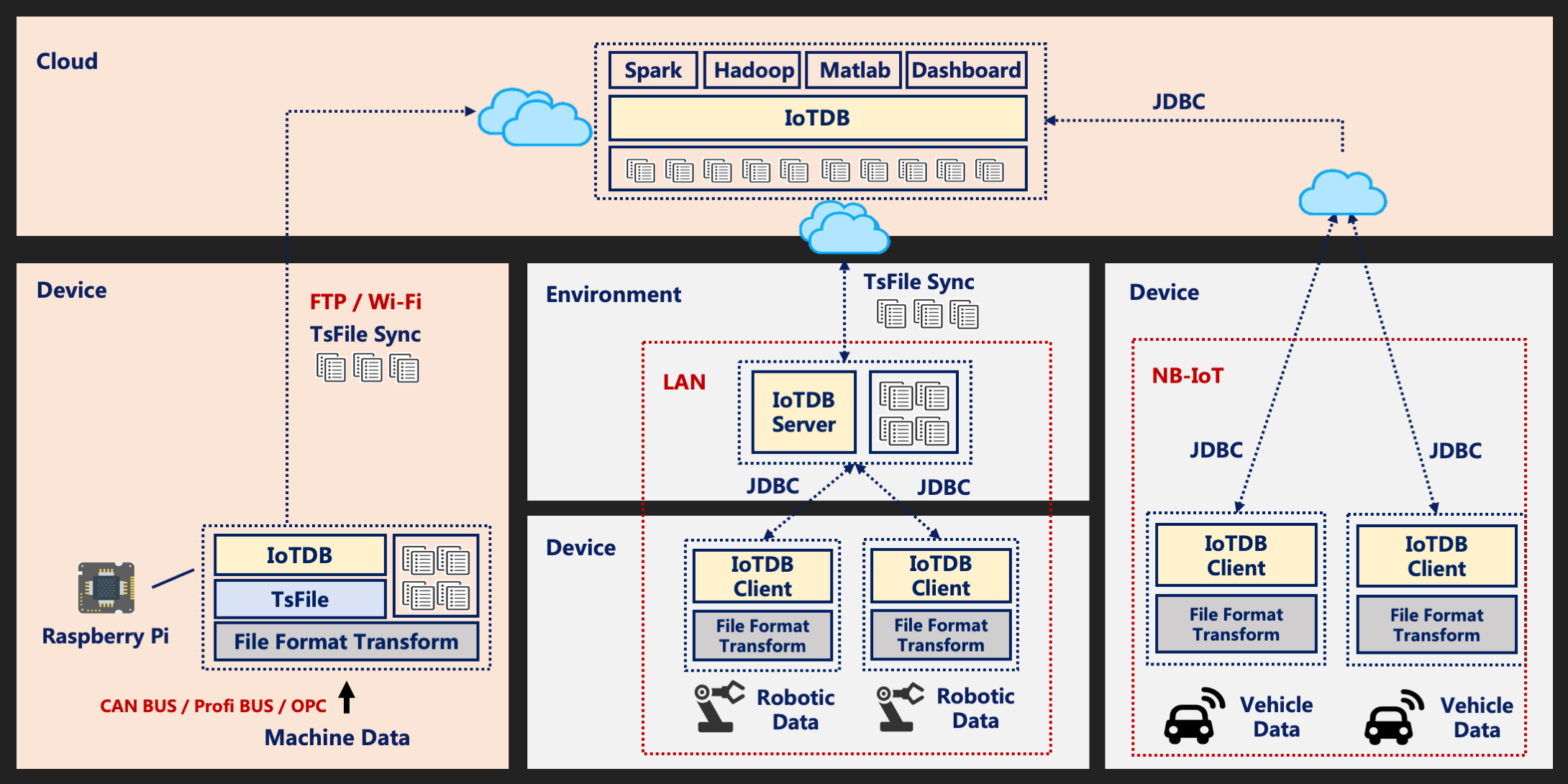
Apache IoTDB 是专为物联网时序数据打造的数据库,提供数据采集、存储、分析的功能。IoTDB 提供端云一体化的解决方案,在云端,提供高性能的数据读写以及丰富的查询能力,针对物联网场景定制高效的目录组织结构,并与 Apache Hadoop、Spark、Flink 等大数据系统无缝打通;在边缘端,提供轻量化的 TsFile 管理能力,端上的数据写到本地 TsFile,并提供一定的基础查询能力,同时支持将 TsFile 数据同步到云端。
TsFile
TsFile 是为物联网设备时序数据存储定制的文件格式,整体以树状目录结构组织,一个 TsFile 里可存储多个设备的数据,每个设备包含多个 measurment(指标)。如下图,TsFile 里包含两个设备数据,标识分别为 d1、d2;每个设备包含 s1、s2、s3 三个监测指标。
TsFile 整体是一个多级映射表,TsFileMetaData ==> TimeSeriesMetadata ==> ChunkMetadata ==> Chunk。
TsFileMetadata 描述整个 TsFile ,包含格式版本信息, MetadataIndexNode 的位置,总的 chunk 数等元数据信息。
MetadataIndexNode 包含多个 TimeSeriesMetadata ,每个 TimeSeriesMetadata 指向一个设备的元数据信息 ChunkMetadata 列表;
ChunkMetadata 指向 ChunkHeader 位置,并对应最终的 Chunk Data。

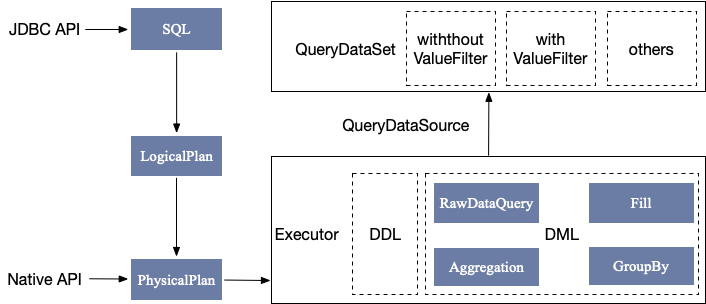
查询引擎
IoTDB 内置查询引擎负责所有用户命令的解析、生成计划、交给对应的执行器、返回结果集。IoTDB 通过查询引擎提供了 JDBC 访问 API,简单易用。
IoTDB> CREATE TIMESERIES root.ln.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN
IoTDB> CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE
IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,status) values(100,true);
IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,status,temperature) values(200,false,20.71)
IoTDB> SELECT status FROM root.ln.wf01.wt01
+-----------------------+------------------------+
| Time|root.ln.wf01.wt01.status|
+-----------------------+------------------------+
|1970-01-01T08:00:00.100| true|
|1970-01-01T08:00:00.200| false|
+-----------------------+------------------------+
Total line number = 2
元数据管理
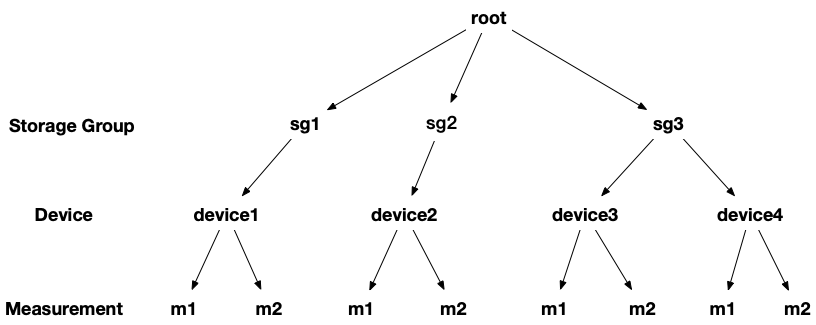
IoTDB 的元数据模型采用树状结构组织,一个实例包含多个 Storage Group (类似于 Namespace、Database 的概念),一个 Storage Group 里包含多个 Device ,每个 Device 包含多个 Measurement , Measurement 对应的时间序列数据最终存储在 TsFile Chunk 里。另外,为了方便数据过期,每个 Stroage Group 的数据会以时间范围的形式切分存储,默认以周为单位,使用不同的目录存储。
// Storage Group 分区存储结构
data
-- sequence
---- [存储组名1]
------ [时间分区ID1]
-------- xxxx.tsfile
-------- xxxx.resource
------ [时间分区ID2]
---- [存储组名2]
-- unsequence
同步工具
IoTDB 支持在边缘侧、云端部署,通常在边缘侧采集的数据有同步到远端进一步分析处理的需求;IoTDB 提供了同步工具,支持将端/设备上的 TsFile 数据往云端同步。

连接器
IoTDB 支持与现有的大数据处理系统,包括 Hive、Spark 等无缝连通,IoTDB 提供了 hive-tsfile 、 spark-tsfile 、 spark-iotdb 等连接器,让 Hive、Spark 能直接访问 tsfile 格式的数据,以及访问 IoTDB 的数据。
总结
优势
针对物联网模型做了定制化,提供 JDBC 访问方式,支持边云一体化部署。
存储使用 Hadoop File system,并提供多种 connector,与现有大数据生态无缝打通。
开放的 TsFile 存储格式,设备模型简单易理解。
不足
IoTDB TsFile 的结构,目前仅有 java 版本,资源占用方面对边缘轻量级设备不友好,限制了其在端/设备侧的应用。
云端版本目前仅有单节点版本,无法满足海量设备数据接入云端的需求。
存储上支持使用 HDFS 或 本地盘,通过使用 HDFS 来存储可保证存储层高可用,但计算层没有进一步的高可用保障。