文章目录
简介
公式输入请参考:在线Latex公式
本节讲如何用GAN递推(改进)Generator。本节内容大纲如下:
Conditional Sequence Generation
• RL (human feedback)
• GAN (discriminator feedback)
Unsupervised Conditional Sequence Generation
• Text Style Transfer
• Unsupervised Abstractive Summarization
• Unsupervised Translation
Conditional Sequence Generation
概念,只要是产生Sequence的task都是属于Conditional Sequence Generation的范畴。
如:语音识别,机器翻译、智能聊天机器人

Those generator is a typical seq2seq model.
With GAN, you can train seq2seq model in another way.
这节课就是要学习如何用GAN来改进这些seq2seq模型
原始seq2seq模型回顾
之前讲过的的seq2seq模型包含两个模块,分别是Encoder和Decoder,这里是一个Chatbot的例子,所以模型的Encoder吃一个句子,Decoder吐出来另外一个句子。

例如,我们有这么一组训练数据:

那么我们的模型目标就是要最大化输出句子和标签的likelihood。

但是这是一个seq模型,因此输出的句子不是一起出来的,第一个时间步我们希望输出【I’m】概率越大越好,第二个时间步我们希望输出【good】的概率越大越好。
这样就有问题,我们看一下下面的输出比较
| 输出的句子 | Not bad | I’m John |
|---|---|---|
| 从人的角度看 | 这个好 | |
| 从与标签的相似度看 | 这个好 |
这里补充一点,模型的目标是:Maximize likelihood,这个目标和Minimize crossentropy是一样的。
下面来看如何改进这个问题
RL (human feedback)
先看如何用强化学习来改进这个问题,实际上RL是seq2seq的一个特例(special case)
先来看如何用RL来训练一个Chat-bot:Machine obtains feedback from user.

上图表达的意思就是人说一句话,Chat-bot有一个回应,然后得到一个分数,Chat-bot的目标就是要把分数最大化。
Chat-bot learns to maximize the expected reward.
把这个事情模型化表达:

Chat-bot就是要调整内部Encoder和DEcoder的参数,使得Reward最大化,这个最大化的过程要用到的方法就是Policy Gradient。上面模型中,人可以看做是已经训练好的模型,亦可看做是Conditional GAN中的条件。
Policy Gradient
这块内容在ML的课程里面有讲,这里快速过一遍:

先假设参数
不变,则这个seq2seq模型得到的Reward的期望是:
h是输入,
是h出现的几率,把所有输入出现的几率求和:
是给定参数
,给定输入h后,Chat-bot输出x的机率(因为同一个输入,输出可能是不同的,输出的可能性是一个分布,我们从这个分布里面sample出x)。
是Chat-bot输出x的时候人给出的reward,这里可以看做是一个权重。
接下来我们要调整参数
,使得Reward的期望越大越好:
要解这个,先把公式1进行变形,由于h是从分布
来的可以写成
,x是从分布
来的可以写成
,所以有:
这里要求期望E,理论上是要对所有样本进行求和,是无法完成的,因为我们没有办法穷举所有的可能样本。
实作上我们是做sample,输入h我们可以从数据库里面做sample,输出x我们可以把输入丢到模型算出来,这样我们就可以sample到N个样本:
那么公式2可以写为:
发现算到最后,
中并没有包含参数
,这样就没办法用梯度下降法进行求解,因此这里我们要在
的约等于之前先做微分才行,那个时候
还在。
下面给出数学的推导:
warning of math
对公式1左右同时求
的导数
把
分子分母同时乘以
根据以下公式:
有复合函数:
公式3中的:
因此,公式3可以写为:
推导结束,如果没看懂。。。没关系,结论如下:
Policy Gradient Ascent
参数
更新的方法:
计算梯度的公式为:
解释一下公式4:去sample N个
出来,然后计算
,最后乘上
。
也就是说:
如果输入
,Chatbot回答
,人觉得这个回答不错,给出的Reward:
是正的(positive),那么就要更新参数
,使得
增加,也就是增加输入
,Chatbot回答
的几率;
反之:
如果输入
,Chatbot回答
,人觉得这个回答很烂错,给出的Reward:
是负的(negative),那么就要更新参数
,使得
减少,也就是减少输入
,Chatbot回答
的几率。
Policy Gradient Implemenation

上图显示了Policy Gradient实作过程:
第一步是左边的红框,先输入N个句子给Chatbot,得到N个回答(相当于采样),然后人对这N个问答进行评分
第二步是更新参数
,其中蓝色部分是计算
的公式
这里要注意,在更新完参数
后,需要重新回到第一步,重新做采样,重新做采样,重新做采样。
因为
是根据参数
计算出来的,如果
变化了,需要重新采样。这里是和普通的GD不一样的地方,普通GD不需要重新采样。因此Policy Gradient中更新参数这个步骤是非常难得的,每次的更新都是N次互动后的结果,挖坑:后面会有trick来改进这个步骤。
原始模型 vs RL模型

表格不好写公式,上图中的notation和之前有点不一样,这里的输入是用c表示,而前面用的h,这里说明一下。
原始模型中用的训练数据是用的标签数据
比较二者的Gradient可以发现,二者非常相似,只不过RL模型每个Gradient多了一个
,可以看过权重。
所以从全局来看,相当于原始模型中默认的权重都是1,而RL模型权重各不相同(权重是根据Chatbot回答好不好决定的) 。
Tip:
在实作的时候,
是概率,总是正数,评分
也是正数,这样训练是有问题,我们希望不好的回答是负反馈,是负数,因此可以对评分进行一个平移,使得分数有正有负。
GAN (discriminator feedback)
上面讲的RL太麻烦,理论上虽然可行,但是不可能每次更新参数都去互动N次,于是有人就想了一个办法,用机器来替代人做评分这个环节。
Using a pre-defined evaluation function to compute R(h,x)

但是这个evaluation function:R(h,x)不好定义,像上面的图片中,左边死循环就差,右边就好?标准是什么?难,所以引入GAN的思想来解决这个问题:用discriminator代替人来给出评分feedback。
模型框架如下:

上图中的Discriminator可以看做是人在给Reward,只不过这个Discriminator是不完美的人,它也需要调整参数,进行训练。
算法描述
Training data:
Pairs of conditional input
and response
• Initialize generator G (chatbot) and discriminator D
对于discriminator D
• In each iteration:
• Sample input
and response
from training set. 从训练数据中采样问答数据对(真实数据)
• Sample input
from training set, and generate response
by
.从训练数据采样输入
,并用Chatbot生成对应的回答
(生成数据)
• Update D to increase
and decrease
.更新Discriminator使得真实数据概率越大越好,生成数据的概率越小越好。
对于generator G
更新G使得生成器生成数据骗过Discriminator打分越高越好。
Update generator G (chatbot) such that

上图中Discriminator少了一个输入,应该还有一个真实的问答对数据。
整个过程和conditional GAN一样的。
但是这里的问题在于Generator是一个RNN的序列模型。

这里注意红圈内是通过sample出来的结果(蓝色虚线箭头)。然后把Generator得到结果丢到Discriminator里面得到一个scalar(分数),然后根据这个分数来更新Generator的参数,使得下一次的分数更高。

这个过程是没有办法实现的,因为没有办法做梯度下降:
Due to the sampling process, “discriminator+ generator” is not differentiable.
梯度下降里面要求导数,中间那个红框部分是采样,采样是有随机性的,是不可导的。从求导的本质来看,导数就是:求x变化后,y的变化程度。如果x变化了,y是随机采样出来的,那么就不能保证y的变化程度了。
这里和图像处理的GAN不一样的地方,文字处理生成句子的过程用了采样,无法求导,也就是无法梯度下降,无法反向传播,无法更新参数。
同样的使用TF或者PYTORCH来实现这个模型,会得到一个错误。
这个问题也是有解决方案的,一共三种:
Gumbel-softmax
不展开,思想就是使用一个trick使得不可求导的变成可以求导的。
•
Continuous Input for Discriminator
•
这个方法就是绕过不可求导的采样步骤,直接将采样前的分布作为Discriminator的输入,注意看下图中红色箭头。

但是将连续的分布表示作为Discriminator的输入是有问题的,因为对于真实数据中的句子,每个词都是用独热编码进行表示的;

而由Generator生成的,生成的中间部分的概率分布是连续表示的,不会也不可能是独热编码。

这样的明显的区别Discriminator不用很高智商就能分辨出来了(看是否独热编码),也就是说Generator永远没法骗过Discriminator。
当然可以用WGAN来试试,WGAN的Discriminator好比带上了毛玻璃眼镜,对于是否独热编码这里是分辨得不是很清楚,因此,有可能训练出Generator。
Reinforcement Learning
•

将之前RL (human feedback)模型中的人替换为Discriminator,也就是:
• Consider the output of discriminator as reward
• Update generator to increase discriminator = to get maximum reward
• Using the formulation of policy gradient, replace reward
with discriminator output
• Different from typical RL(human feedback)
• The discriminator would update
下面给出人和Discriminator做评分的算法上的区别,其实很简单,就是把
替换为
:

当然用Discriminator来进行评分还要额外对Discriminator进行训练,训练方式见上图d-step。
Reward for Every Generation Step
下面来具体看看RL中的Reward计算的trick,用Discriminator替换人评分后,评分计算梯度的公式就变成了(参考公式4,把R换成D):(这里输入把h又换成c了,老师的ppt和视频有点不统一,明白即可)
假设输入
回答为:
那么Discriminator会判断这个回答不好(negative),那么模型就会更新参数
使得回答出现概率
降低。
根据语言模型,这句话出现的概率为:
取对数后乘法变加法:
要降低
,就是降低
,就是降低右边三项,使得右边三项分别都降低。
如果我们看第一项:
第一个单词出现【I】这个没错呀,因为回答可能是【I am Hanmeimei】。
再看另外一个例子:
假设假设输入
回答为:
那么Discriminator会判断这个回答不错(positive),那么模型就会更新参数
使得回答出现概率
增加。
根据公式6,要增加
,就是增加
,就是增加右边三项,使得右边三项分别都增加。
通过以上两个小例子,我们看到,如果positive和negative样本对个数相当的话,那么公式7中的【I】出现的概率可能不变,但是如果negative样本比较多,那么【I】出现的概率会变小,不科学!
正确的做法是:
假设输入
回答为:
那么Discriminator会判断这个回答不好(negative),那么模型就会更新参数
使得回答出现概率
降低。根据语言模型,这句话出现的概率为:
模型找出这个回答不好的是后面两项:
和
,概率要减少,第一项概率是要增加的。
要做到这个事情要把公式5进行改写为:
不是对整个句子给分数了,而是给每个生成的step都要有分数,这里换了新的评价函数,所以取名叫Q。
这个评价函数还没有正规很好的解决方法,目前有两种方法解决:
Method 1. Monte Carlo(MC) Search [ Yu, et al, AAAl,2017]运算量大,类似alphaGo。
Method 2.Discriminator For Partially Decoded Sequences [ Li, et al., EMNLP2017]运算量小,效果不如法1。
当然还有另外一种解决方案,老师又挖坑,不展开,这里只贴图:
RankGAN
Kevin Lin, Dianqi Li, Xiaodong He, Zhengyou Zhang, Ming-Ting Sun, “Adversarial Ranking for Language Generation”, NIPS 2017

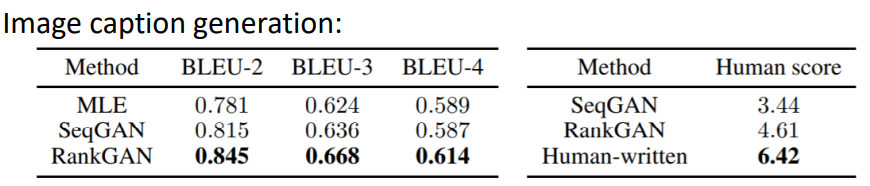
Experimental Results
| Input | We’ve got to look for another route. |
|---|---|
| MLE | I’m sorry. |
| GAN | N You’re not going to be here for a while. |
| Input | You can save him by talking. |
|---|---|
| MLE | I don’t know. |
| GAN | You know what’s going on in there, you know what I mean? |
通过实作后观察MLE模型的输出会发现,MLE模型通常(十分之一)都是倾向短句,且回答比较一般化,例如:我不知道。
• MLE frequently generates “I’m sorry”, “I don’t know”, etc.
(corresponding to fuzzy images?)
GAN会产生比较长的句子
• GAN generates longer and more complex responses
(however, no strong evidence shows that they are better)
Find more comparison in the survey papers.
最后建议:If you are using seq2seq models, consider to improve them by GAN.
Unsupervised Conditional Sequence Generation
Text Style Transfer
可以回顾之前学习的图片的Unsupervised Conditional GAN

用在语音和文字上:
变声器

文本风格转换
Direct Transformation
这个是借鉴Cycle GAN的做法,我们先稍微回顾一下:用两个Generator,第二个(橙色的)Generator要把第一个Generator生成对象重新还原回原输入的照片。两个Generator接在一起,被称为:Cycle GAN。:

把图像换为文字就可以应用的文本处理上,具体模型如下图所示:

其中可以把Positive的语料可以看做一个domain,Negative的语料可以看做另外一个domain。
但是上面的模型Generator在生成语句的过程中也是用到了采样,因此也是不能求导和反向传播的,解决方案在上一小节已经说了有三种。这里用的是第二种,用Word Embedding来表示词,Word Embedding是Continuious的表示,这样就解决了求导和反向传播的问题,模型就变成:

下面是做的结果:

当然最后两句是失败的例子。
Projection to Common Space
这个方法前面也讲过,就是把两个domain的特征都抽取到同一个公共向量上。

把图片换成不同domain的文本,当然也可以用上面的模型,对于模型Decoder/Generator在生成语句的过程中也是用到了采样,不能反向传播,这里可以将Decoder的隐藏层作为Encoder的输入(下图红色箭头部分)。

当然对于把两个domain的文本投影到公共向量这个事情上,在图像上已经有很多很好的constraint trick来提升效果,在文本上这块研究做得还比较少,可以深入一下,目前对于这里的constraint只有一种,就是在公共变量上接一个Discriminator分类器,要分辨这个公共变量是由哪个Domain的Encoder得来的。而两个Domain的Encoder则是要骗过Discriminator。整个结构如下:

Unsupervised Abstractive Summarization
以前机器做摘要都是Extract方式的,就是判断文章中那些句子比较重要(可以用二分类来判断是否重要),然后拿出来拼在一起就完事。这样的摘要都是原文。
现在要用seq2seq模型来做这个事情:write summaries in its own words。思想如下图,就是给很多语料,并且带有这些语料对应的摘要,丢到seq2seq模型训练,这样的问题就是在于需要大量的标记数据,这个很难。。。根据老师的经验,要训练这样的seq2seq模型,至少要100w的数据才行。

为了解决数据收集困难的问题,提出一种新的无监督的方法(其实就是借鉴Unsupervised Conditional Generation)。把文章看做一个Domain,把摘要看做是另外一种Domain,这样一来,数据就只要两堆,一堆是文章,一堆是摘要,二者不需要对应。

模型构架如下图:

这里D是用来分辨G生成的摘要是否和人类相近,R则用来保证生成的摘要和原文相关。
补充:
- 具体实作的时候Unsupervised Learning的方法用的数据只需要supervised 的1/5左右就可以达到相同或者相近的效果
- 训练完Unsupervised 模型后,可以用一些带有标签的数据对模型进行fine-tune,效果可以进一步提升。
Unsupervised Translation
同样的,在翻译上,可以把两种语言看做是两个不同的Domain,然后进行训练,就可以得到一个翻译模型。

以上两篇都是非死不可发的论文。
下图是论文结果截图,横轴是数据量,纵轴是翻译效果。从图中可以看到,数据量越大,效果当然是越好,但是
Unsupervised learning with 10M sentences = Supervised learning with 100K sentence pairs

附加Unsupervised Speech Recognition
如果把语音和文字各自看成两个Domain,然后用Cycle GAN训练,这个是有可能实现的,注意看下面的图:

语音中的发音都是
,然后再看文章都是单词【The】开头,所以模型可以推理:
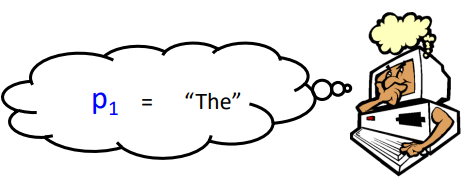
当然效果没有比监督学习好,但是比没有强。。。

这里的语音和文字的语料都是不相干的:
Audio: TIMIT
Text: WMT