
一、HyperLogLog 概述
HyperLogLog 算法一种概率算法,用来实现大数据下的基数估计,即无法精确计算集合的基数,存在一定偏差。具体的算法实现可以参见我写的另一篇文章:夜深人静写算法(十四)- 基数估计 (Cardinality Estimation)。
Redis 对这个算法进行了一些改进。主要有以下几点:
a) 采用 64 位哈希函数,这样基数数值就不用局限在 10^9 了,当基数在 2^32 附近的时候,不需要额外进行修正;
b) 采用 16384 个 6比特的寄存器(桶)提高计算的精确度,每个集合的内存总数仅有 12K (16384 * 6 / 8 / 1024 = 12);
c) 存储采用 Redis 自带的 sds 字符串(Redis底层详解(二) 字符串),并提供了两种存储方式:密集型存储 和 稀疏型存储;
1、算法概述
改进后算法的简介如下:
给定一个集合 S,集合中的元素可以是 整数、指针、字符串 等等任意对象。给定一个 64 位的哈希函数 H,能够将这些对象进行映射,映射后的值是一个 64 位的比特串(每位是 0 或 1),比特串的低 14 位用来表示寄存器(也称为桶)编号,剩下 50 位用来寻找“最长 0 尾缀”。一共 16384 (2 的 14次幂) 个寄存器,用来存储 “最长 0 尾缀”(原算法用的是前缀,Redis为了方便计算采用尾缀的形式,其实是一样的)。然后计算这些 “最长 0 尾缀” 的调和平均数得到一个初始估值 E。然后根据 E 的相对大小再进行二次估值 得到最后的集合基数。其中 E 的计算公式如下:
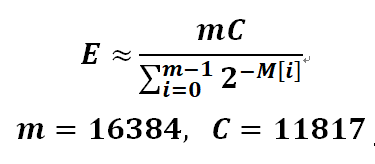
m 即寄存器的数量,M[i] 代表第 i 个寄存器中的 “最长 0 尾缀” 的值,C 在 m 确定的情况下是个常量,E 就是调和平均数。
2、存储优化
由于当集合元素较少时,大多数的寄存器的值为 0,所以在存储时,可以采用 Run Length Encoding 进行压缩存储,这种压缩后的存储方式就是稀疏型存储(HLL_SPARSE),对应的,未压缩前的存储方式就是密集型存储(HLL_DENSE)。两种存储方式对应的核心算法是一致的,只不过在持久化时采用不同的存储方式,介于篇幅的关系,本文只介绍密集型存储。
二、HyperLogLog 结构
1、HyperLogLog 头
无论是密集型存储还是稀疏型存储,都有一个头结构 hllhdr,定义如下:
struct hllhdr {
char magic[4];
uint8_t encoding;
uint8_t notused[3];
uint8_t card[8];
uint8_t registers[];
};
#define HLL_HDR_SIZE sizeof(struct hllhdr)
#define HLL_DENSE_SIZE (HLL_HDR_SIZE+((HLL_REGISTERS*HLL_BITS+7)/8))
#define HLL_DENSE 0
#define HLL_SPARSE 1 magic[4] 为四个 “魔法” (固定不变的意思)字符,即 “HYLL”,代表这是一个 HyperLogLog 结构,区分于普通的 sds 字符串;
encoding 代表存储的编码方式,总共两种:密集型编码存储 HLL_DENSE、稀疏型编码存储 HLL_SPARSE;
notused[3] 为三个暂时不用到的保留字节,值为0;
card[8] 以小端序存储了一个 64 位的整数,代表上次计算出来的近似集合基数。这个是很有用的,因为每次在执行集合插入的过程中,有很大概率是不会改变原有的数据结构的,这样这个近似的基数值就可以直接拿过来用而不需要重新计算。
registers[] 存储了寄存器,根据 encoding 来决定存储的编码方式。寄存器的作用会在下文中详述。以下是 HyperLogLog 的内存结构的示意图(可以理解成整个 HyperLogLog 结构就是一个以 "HYLL" 为首的 sds 字符串):

2、HyperLogLog 寄存器
寄存器(register)又名 桶 (bucket),每个寄存器用来存储分配给它的元素在进行哈希后的 “最长 0 尾缀” 的值,HyperLogLog 正是利用所有寄存器的值来计算调和平均数,最终得到集合的基数的初始估计值。一些寄存器常量定义如下:
#define HLL_P 14
#define HLL_REGISTERS (1<<HLL_P)
#define HLL_P_MASK (HLL_REGISTERS-1)
#define HLL_BITS 6
#define HLL_REGISTER_MAX ((1<<HLL_BITS)-1)HLL_P 的值越大,计算得到的基数的误差越小。HLL_REGISTERS 是寄存器的总数量,值为 16384 。HLL_P_MASK 用来将取模运算转化成 位与,下面会讲到。
三、HyperLogLog 算法详解
1、最长 0 尾缀
在分析 HyperLogLog 算法之前,先来看下之前提到的 “最长 0 尾缀” 的实现方式,hllPatLen 的作用是将传入的字符串 ele,通过 MurmurHash64 哈希算法得到一个 64 比特的串,然后将这个串的低 14 位作为寄存器编号,高 50 用来计算 “0” 尾缀。那么顾名思义,“最长 0 尾缀” 就是在寄存器编号相同的情况下,“0” 尾缀的最大值。实现如下:
int hllPatLen(unsigned char *ele, size_t elesize, long *regp) {
uint64_t hash, bit, index;
int count;
hash = MurmurHash64A(ele,elesize,0xadc83b19ULL); /* a */
index = hash & HLL_P_MASK; /* b */
hash |= ((uint64_t)1<<63); /* c */
bit = HLL_REGISTERS;
count = 1;
while((hash & bit) == 0) {
count++;
bit <<= 1;
}
*regp = (int) index;
return count;
} a、MurmurHash64A 是一个哈希算法:MurmurHash2。通过传入的字符串计算出一个 64 位的整数 (其中 0xadc83b19ULL 是哈希计算时的种子 seed)。Redis 中的这个函数修改了一下,支持大端序和小端序两种版本。
b、hash & HLL_P_MASK 的含义是 hash % HLL_REGISTERS,作用是通过取模找到对应的寄存器。用 & 有两个好处:位运算速度远快于取模;取模可能产生负数,而 & 不会。寄存器编号会存储在 regp 并通过指针的方式返回出去。
c、从 hash 这个 64 位整数的低位开始第 14 位 (即 HLL_P,0 - based)开始往高位一位一位的找,找到第一个值为 1 的位,中间如果有 k 个 0,则 “0” 尾缀的值 count = k + 1。为了不在 while 时产生死循环,将 hash 的最高位 (第 63 位) 用位或设置为 1。
如下图所示,分别表示两个 hash 值的 64 个比特位,内存从上往下递增,每个字节的右侧为比特位的低位(LSB),左侧为高位(MSB)。第一个 hash 从 14 位开始遍历 4 次找到第一个 1,所以“0” 尾缀的值为4;第二个 hash 的 14 位已经是 1 了,所以“0” 尾缀的值为 1 。

那么,所有的集合元素计算完毕,每个寄存器的值(最长0尾缀的值)也就得到了。
2、密集型存储
密集型存储相对于稀疏型存储来说比较简单,采用紧凑型的编码方式,每 HLL_BITS (默认为 6)个比特位存储一个寄存器,所以寄存器能够存储的最大值为 63 (二进制表示为 6 个 1),即 HLL_REGISTER_MAX 宏定义。
但是计算机存储的基本单元是字节,一个字节 8 个比特位,所以为了节约内存,某些寄存器是跨字节存储的。
如下图所示,红色代表 0 号寄存器的 6个比特位,橙色代表 1 号寄存器,黄色代表 2 号,以此类推。6 和 8 的最小公倍数为 24,所以 3个字节一个周期。每 3 个字节存储 4 个寄存器,总共 16384 个寄存器,占用字节数为 16384 / 4 * 3 = 12288 = 12K。
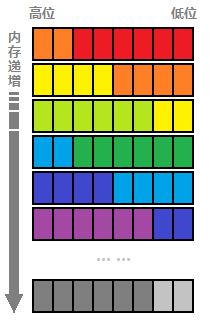
3、寄存器值获取
寄存器的获取通过宏 HLL_DENSE_GET_REGISTER 实现。源码实现如下:
#define HLL_DENSE_GET_REGISTER(target,p,regnum) do { \
uint8_t *_p = (uint8_t*) p; \
unsigned long _byte = regnum*HLL_BITS/8; \
unsigned long _fb = regnum*HLL_BITS&7; \
unsigned long _fb8 = 8 - _fb; \
unsigned long b0 = _p[_byte]; \
unsigned long b1 = _p[_byte+1]; \
target = ((b0 >> _fb) | (b1 << _fb8)) & HLL_REGISTER_MAX; \
} while(0) target 用于存储寄存器的值,当返回值用;p 是所有寄存器内存首地址;regnum 表示第几个寄存器(0-based)。这个宏定义的含义就是获取第 regnum 个寄存器存的值并且返回到 target 中。让我们来看下这些位运算的含义。
首先,由于寄存器的长度(6个比特位)小于 1 个字节的比特位长度,所以每个寄存器最多跨越两个字节,我们定义内存地址小的叫低字节,地址大的叫高字节。所以低字节的高 k 位 和 高字节的低 (6 - k) 位组成了一个完整的寄存器。如图所示,浅蓝色部分是一个完整的寄存器地址,它由低字节的高 2 位和高字节的低 4 位组成。
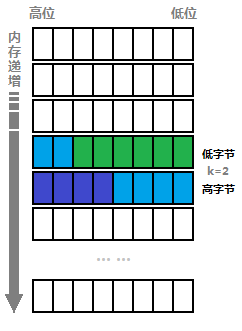
_byte 用来计算第 regnum 个寄存器的低字节相对于 p 的字节偏移量。那么 p[_byte] 和 p[_byte+1] 就分别代表了上文提到的低字节和高字节的值。_fb 的 “位与 7 ” 相当于 “模 8 ”,再用 8 去减后得到 _fb8,这里的 _fb8 就是上图中得到的 k 。最后 target 的值分四步获得:
(1) 低字节的值右移 ( 8 - k ) 位,得到 x;
(2) 高字节的值左移 k,得到 y;
(3) x 位或 y,得到 z;
(4) z 位与 HLL_REGISTER_MAX,截掉无用高位,得到最终值 target;
举例说明,当 regnum = 5 时,则需要取到蓝色寄存器的值,k 的值为 8 - 5 * 6 % 8 = 2。计算 target 的过程如下:

4、寄存器值设置
寄存器的设置通过宏 HLL_DENSE_SET_REGISTER 实现。源码实现如下:
#define HLL_DENSE_SET_REGISTER(p,regnum,val) do { \
uint8_t *_p = (uint8_t*) p; \
unsigned long _byte = regnum*HLL_BITS/8; \
unsigned long _fb = regnum*HLL_BITS&7; \
unsigned long _fb8 = 8 - _fb; \
unsigned long _v = val; \
_p[_byte] &= ~(HLL_REGISTER_MAX << _fb); \
_p[_byte] |= _v << _fb; \
_p[_byte+1] &= ~(HLL_REGISTER_MAX >> _fb8); \
_p[_byte+1] |= _v >> _fb8; \
} while(0) 这个宏定义的含义就是将第 regnum 个寄存器存的值设置为 val 。和获取一样,同样需要分成高低两字节进行设置。假设低字节的高 k 位 和 高字节的低 (6 - k) 位组成了一个完整的寄存器。 那么只要截取 val 的低 k 位 和 高 (6 - k) 位分别放到寄存器的对应位置就行了。
对于寄存器的低字节操作如下:
(1) HLL_REGISTER_MAX 左移 (8 - k) 位 , 然后取反得到 x ,使得 x 的高 k 位等于 0;
(2) 低字节位与上 x,目的是清空低字节的高 k 位的值;
(3) val 左移 (8 - k) 位得到 y ;
(4) 低字节 位或 y ,将 val 的低 k 位填充到 低字节的高 k 位上;
举例说明,当 regnum = 5 时,则需要设置蓝色寄存器的值,k 的值为 8 - 5 * 6 % 8 = 2。低字节的计算过程如下:

对于寄存器的高字节操作如下:
(1) HLL_REGISTER_MAX 右移 k 位 , 然后取反得到 x ,使得 x 的低 (6 - k) 位等于 0;
(2) 高字节位与上 x,目的是清空高字节的低 (6 - k) 位的值;
(3) val 右移 k 位得到 y ;
(4) 高字节 位或 y ,将 val 的高 (6 - k) 位填充到 高字节的低 (6 - k) 位上;
举例说明,同样当 regnum = 5 时,则需要设置蓝色寄存器的值,k 的值为 8 - 5 * 6 % 8 = 2。高字节的计算过程如下:

结合以上两种情况,我们就将 val 的值设置到蓝色寄存器上了,如图所示(val 前两个比特位为虚线是因为 val 的值不会超过 2 的 6 次 减 1,即 63):
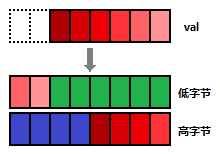
5、集合添加元素
集合增加元素调用 hllAdd 接口,这对应的是更新 "最长 0 尾缀" 的过程,实现如下:
int hllAdd(robj *o, unsigned char *ele, size_t elesize) {
struct hllhdr *hdr = o->ptr;
switch(hdr->encoding) {
case HLL_DENSE: return hllDenseAdd(hdr->registers,ele,elesize);
case HLL_SPARSE: return hllSparseAdd(o,ele,elesize);
default: return -1;
}
}根据存储方式选择不同的接口,密集型存储调用 hllDenseAdd,稀疏型存储调用 hllSparseAdd。稀疏型存储的实现相对较复杂,这里以密集型存储实现为例来说明实现机理。添加元素的过程的并非真正的元素添加,只有当传入的字符串算出来的 "最长 0 尾缀" 比对应寄存器中存的值大的时候才做更新,否则保持原样。主要用到了上文提到的两个宏定义:HLL_DENSE_GET_REGISTER 和 HLL_DENSE_SET_REGISTER。源码在 hyperloglog.c 中,实现如下:
int hllDenseAdd(uint8_t *registers, unsigned char *ele, size_t elesize) {
uint8_t oldcount, count;
long index;
count = hllPatLen(ele,elesize,&index);
HLL_DENSE_GET_REGISTER(oldcount,registers,index);
if (count > oldcount) {
HLL_DENSE_SET_REGISTER(registers,index,count);
return 1;
} else {
return 0;
}
} 6、集合元素统计
统计就是利用 16384 个寄存器计算调和平均数的过程,调用 hllCount 接口完成统计工作,实现如下:
uint64_t hllCount(struct hllhdr *hdr, int *invalid) {
double m = HLL_REGISTERS;
double E, alpha = 0.7213/(1+1.079/m);
int j, ez;
... /* a */
if (hdr->encoding == HLL_DENSE) { /* b */
E = hllDenseSum(hdr->registers,PE,&ez);
} else if (hdr->encoding == HLL_SPARSE) {
E = hllSparseSum(hdr->registers,
sdslen((sds)hdr)-HLL_HDR_SIZE,PE,&ez,invalid);
} else if (hdr->encoding == HLL_RAW) {
E = hllRawSum(hdr->registers,PE,&ez);
} else {
serverPanic("Unknown HyperLogLog encoding in hllCount()");
}
E = (1/E)*alpha*m*m; /* c */
if (E < m*2.5 && ez != 0) {
E = m*log(m/ez); /* d */
} else if (m == 16384 && E < 72000) {
double bias = 5.9119*1.0e-18*(E*E*E*E) /* e */
-1.4253*1.0e-12*(E*E*E)+
1.2940*1.0e-7*(E*E)
-5.2921*1.0e-3*E+
83.3216;
E -= E*(bias/100);
}
return (uint64_t) E;
} a) 初始化计算 PE 的过程,PE[i] = 2 ^ (-i),为了避免重复计算,节省时间,所以预处理在数组 PE[] 中;
b) hllDenseSum、hllSparseSum 分别表示在不同存储方式下计算调和平均数的分母(下文作详细讲解)。hllRawSum 是原生的存储方式,用1个字节代表一个寄存器,不对外开放,用于加速计算;
c) 这个公式是本文开始提到的初始估值的计算公式;
d) 数据量比较小时采用线性估值(Linear Counting);
e) 误差修正;
hllDenseSum 求的是如下式子,其中 r 为寄存器数组,max 是寄存器数量:

先来看代码如何实现的,同样在 hyperloglog.c 中:
double hllDenseSum(uint8_t *registers, double *PE, int *ezp) {
double E = 0;
int j, ez = 0;
if (HLL_REGISTERS == 16384 && HLL_BITS == 6) {
uint8_t *r = registers;
unsigned long r0, r1, r2, r3, r4, r5, r6, r7, r8, r9,
r10, r11, r12, r13, r14, r15;
for (j = 0; j < 1024; j++) {
r0 = r[0] & 63; if (r0 == 0) ez++;
r1 = (r[0] >> 6 | r[1] << 2) & 63; if (r1 == 0) ez++;
....... 此处省略,节约篇幅
r14 = (r[10] >> 4 | r[11] << 4) & 63; if (r14 == 0) ez++;
r15 = (r[11] >> 2) & 63; if (r15 == 0) ez++;
E += (PE[r0] + PE[r1]) + (PE[r2] + PE[r3]) + (PE[r4] + PE[r5]) +
(PE[r6] + PE[r7]) + (PE[r8] + PE[r9]) + (PE[r10] + PE[r11]) +
(PE[r12] + PE[r13]) + (PE[r14] + PE[r15]);
r += 12;
}
} else {
for (j = 0; j < HLL_REGISTERS; j++) {
unsigned long reg;
HLL_DENSE_GET_REGISTER(reg,registers,j);
if (reg == 0) ez++;
else E += PE[reg];
}
E += ez;
}
*ezp = ez;
return E;
}计算密集型存储,各个寄存器的相反数作为指数,且底数为 2 的幂的和。其中 PE[i] = 2 ^ (-i),为了避免重复计算,节省时间,所以预处理在数组 PE[] 中。*ezp 记录了值为 0 的寄存器数量。为了提高效率,当 HLL_REGISTERS 等于 16384 且 HLL_BITS 等于 6 时,这种属于默认情况,所以为了提高效率写了一堆位运算进行优化。如果已经理解寄存器的存储结构,那么这段代码很容易理解,它的执行效果和 else 语句里执行 HLL_REGISTERS 次 for 的效果是一样的,都是为了求 E = Sum(r, max)。
四、HyperLogLog 常用命令
1、pfadd 向集合中增加元素
pfadd key element [element ...]
127.0.0.1:6370> pfadd hyperloglog_key1 1 2 3 4 5 6
(integer) 1
127.0.0.1:6370> pfadd hyperloglog_key2 0 3 4 5
(integer) 12、pfcount 统计集合中元素个数
pfcount key [key ...]
127.0.0.1:6370> pfcount hyperloglog_key1
(integer) 6
127.0.0.1:6370> pfcount hyperloglog_key2
(integer) 4
127.0.0.1:6370> pfcount hyperloglog_key1 hyperloglog_key2
(integer) 73、pfmerge 对集合作合并操作
pfmerge destkey sourcekey [sourcekey ...]
127.0.0.1:6370[1]> pfmerge hyperloglog_keymerge hyperloglog_key1 hyperloglog_key2
OK
127.0.0.1:6370[1]> pfcount hyperloglog_keymerge
(integer) 7
由于 HyperLogLog 结构并没有存储实际的集合元素,所以无法输出集合的成员。