什么是Hbase?
Hbase是一个利用在HDFS做文件存储,利用mapReduce做数据处理,zookeeper做服务协同的一个高可靠性、高性能、列存储、可伸缩、多版本的 NoSQL 的分布式数据存储系统,实现对大型数据的实时、随机的读写访问。
以下部分API操作代码转载自
http://blog.itpub.net/31506529/viewspace-2214159/
Hbase的表结构模型
不说废话,先上图

跟关系型数据库不同,hbase在建立的时候列是不必确定的,而是在创建数据的时候动态的创建列。因为Hbase中引入了列族的概念
什么是列族
列族:可以理解为一组列的集合,
为什么要有多个列族呢?
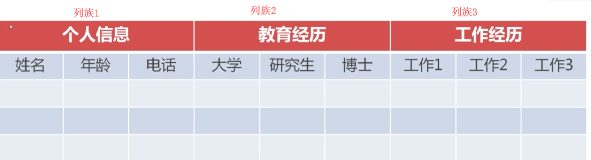 可
可
以看这张图,不同的数据可能拥有的列族是不一样的,一张简历表可以由几个列族组成(列族越少越好,最好不要超过三个),且列族是在创建表格时就确定了的。
列名的命名:按照约定,列名由其列族前缀和限定符组成。courses:history 和 courses:math 都是 courses 列族的成员,冒号字符(:)从列族限定符分隔列族。
Rowkey:的概念和mysql中的主键是完全一样的,Hbase使用Rowkey来唯一的区分某一行的数据。
Hbase只支持3中查询方式:
1、基于Rowkey的单行查询
2、基于Rowkey的范围扫描
3、全表扫描
TimeStamp
HBase 中通过 rowkey 和 columns 确定的为一个存储单元称为 cell。每个 cell 都保存着同一份 数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64 位整型。时间戳可以由 hbase(在数据写入时自动)赋值
简而言之,数据多版本就是靠它实现的!
hbase 提供了两种数据版 本回收方式:
保存数据的最后 n 个版本
保存最近一段时间内的版本(设置数据的生命周期 TTL)。
Cell
由{row key,columnFamily,version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存储。当数据不存在时,是不会占用cell的。
java操作Hbase API
定义常量
static Configuration config = null;
8 private Connection connection = null;
9 private Table table = null;
初始化配置
@Before
12 public void init() throws Exception {
13 config = HBaseConfiguration.create();// 配置
14 config.set("hbase.zookeeper.quorum", "192.168.33.61");// zookeeper地址
15 config.set("hbase.zookeeper.property.clientPort", "2181");// zookeeper端口
16 connection = ConnectionFactory.createConnection(config);
17 Table table = connection.getTable(TableName.valueOf("dept"));//获取dept表
18 }
创建数据库表dept,并增加列族info和subdep**
public void createTable() throws Exception {
27 // 创建表管理类
28 HBaseAdmin admin = new HBaseAdmin(config); // hbase表管理
29 // 创建表描述类
30 TableName tableName = TableName.valueOf("dept"); // 表名称
if(!admin.tableExists(tableName )){//如果表名不存在
HTableDescriptor desc = new HTableDescriptor(tableName);//表描述类
32 // 创建列族的描述类
33 HColumnDescriptor family = new HColumnDescriptor("info"); // 列族
34 // 将列族添加到表中
35 desc.addFamily(family);
36 HColumnDescriptor family2 = new HColumnDescriptor("subdept"); // 列族
37 // 将列族添加到表中
38 desc.addFamily(family2);
39 // 创建表
40 admin.createTable(desc); // 创建表
41 System.out.println("创建表成功!");
}
42 }
删除表
TableName tn = TableName.valueOf(tableName);
if (admin.tableExists(tn)) {
admin.disableTable(tn);//删除表前必须将表设置disable无效状态
admin.deleteTable(tn);//删除表
logger.info("删除表<" + tableName + ">成功!");
} else {
logger.warn(tableName + "表不存在 !删除失败!");
}
单条插入
@Test
public void insertOneData() throws IOException {
//new 一个列 ,hgs_000为row key
Put put = new Put(Bytes.toBytes("hgs_000"));
//下面三个分别为,列族,列名,列值
put.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("name") , Bytes.toBytes("hgs"));
TableName tableName = TableName.valueOf("test");
//得到 table
Table table = conn.getTable(tableName);
//执行插入
table.put(put);
}
插入多个列
@Test
public void insertManyData() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
List<Put> puts = new ArrayList<Put>();
Put put1 = new Put(Bytes.toBytes("hgs_001"));//填充row_key
put1.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("name") , Bytes.toBytes("wd"));
Put put2 = new Put(Bytes.toBytes("hgs_001"));
put2.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("age") , Bytes.toBytes("25"));
Put put3 = new Put(Bytes.toBytes("hgs_001"));
put3.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("weight") , Bytes.toBytes("60kg"));
Put put4 = new Put(Bytes.toBytes("hgs_001"));
put4.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("sex") , Bytes.toBytes("男"));
puts.add(put1);
puts.add(put2);
puts.add(put3);
puts.add(put4);
table.put(puts);
table.close();
}
同一条数据的插入
@Test
public void singleRowInsert() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
Put put1 = new Put(Bytes.toBytes("hgs_005"));
put1.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("name") , Bytes.toBytes("cm"));
put1.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("age") , Bytes.toBytes("22"));
put1.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("weight") , Bytes.toBytes("88kg"));
put1.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("sex") , Bytes.toBytes("男"));
table.put(put1);
table.close();
}
数据的更新
hbase对数据只有追加,没有更新,但是查询的时候会把最新的数据返回给哦我们
@Test
public void updateData() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
Put put1 = new Put(Bytes.toBytes("hgs_002"));
put1.addColumn(Bytes.toBytes("testfm"),Bytes.toBytes("weight") , Bytes.toBytes("63kg"));
table.put(put1);
table.close();
}
删除数据
@Test
public void deleteData() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
//参数为 row key
//删除一列
Delete delete1 = new Delete(Bytes.toBytes("hgs_000"));
delete1.addColumn(Bytes.toBytes("testfm"), Bytes.toBytes("weight"));
//删除多列
Delete delete2 = new Delete(Bytes.toBytes("hgs_001"));
delete2.addColumns(Bytes.toBytes("testfm"), Bytes.toBytes("age"));
delete2.addColumns(Bytes.toBytes("testfm"), Bytes.toBytes("sex"));
//删除某一行的列族内容
Delete delete3 = new Delete(Bytes.toBytes("hgs_002"));
delete3.addFamily(Bytes.toBytes("testfm"));
//删除一整行
Delete delete4 = new Delete(Bytes.toBytes("hgs_003"));
table.delete(delete1);
table.delete(delete2);
table.delete(delete3);
table.delete(delete4);
table.close();
}
查询
@Test
public void querySingleRow() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
//获得一行
Get get = new Get(Bytes.toBytes("hgs_000"));
Result set = table.get(get);
Cell[] cells = set.rawCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength())+"::"+
Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
table.close();
//Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("password")))
}
全表扫描
@Test
public void scanTable() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan = new Scan();
//scan.addFamily(Bytes.toBytes("info"));
//scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("password"));
//scan.setStartRow(Bytes.toBytes("wangsf_0"));
//scan.setStopRow(Bytes.toBytes("wangwu"));
ResultScanner rsacn = table.getScanner(scan);
for(Result rs:rsacn) {
String rowkey = Bytes.toString(rs.getRow());
System.out.println("row key :"+rowkey);
Cell[] cells = rs.rawCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength())+"::"+
Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
System.out.println("-----------------------------------------");
}
}
过滤器
//列值过滤器
public void singColumnFilter() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan = new Scan();
//下列参数分别为,列族,列名,比较符号,值
SingleColumnValueFilter filter = new SingleColumnValueFilter( Bytes.toBytes("testfm"), Bytes.toBytes("name"),
CompareOperator.EQUAL, Bytes.toBytes("wd")) ;
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
for(Result rs:scanner) {
String rowkey = Bytes.toString(rs.getRow());
System.out.println("row key :"+rowkey);
Cell[] cells = rs.rawCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength())+"::"+
Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
System.out.println("-----------------------------------------");
}
}
row key过滤器
@Test
public void rowkeyFilter() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan = new Scan();
RowFilter filter = new RowFilter(CompareOperator.EQUAL,new RegexStringComparator("^hgs_00*"));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
for(Result rs:scanner) {
String rowkey = Bytes.toString(rs.getRow());
System.out.println("row key :"+rowkey);
Cell[] cells = rs.rawCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength())+"::"+
Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
System.out.println("-----------------------------------------");
}
}
列名前缀过滤器
@Test
public void columnPrefixFilter() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan = new Scan();
ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes("name"));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
for(Result rs:scanner) {
String rowkey = Bytes.toString(rs.getRow());
System.out.println("row key :"+rowkey);
Cell[] cells = rs.rawCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength())+"::"+
Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
System.out.println("-----------------------------------------");
}
}
过滤器集合
@Test
public void FilterSet() throws IOException {
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan = new Scan();
FilterList list = new FilterList(Operator.MUST_PASS_ALL);
SingleColumnValueFilter filter1 = new SingleColumnValueFilter( Bytes.toBytes("testfm"), Bytes.toBytes("age"),
CompareOperator.GREATER, Bytes.toBytes("23")) ;
ColumnPrefixFilter filter2 = new ColumnPrefixFilter(Bytes.toBytes("weig"));
list.addFilter(filter1);
list.addFilter(filter2);
scan.setFilter(list);
ResultScanner scanner = table.getScanner(scan);
for(Result rs:scanner) {
String rowkey = Bytes.toString(rs.getRow());
System.out.println("row key :"+rowkey);
Cell[] cells = rs.rawCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength())+"::"+
Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
System.out.println("-----------------------------------------");
}
}
@After
public void closeConn() throws IOException {
conn.close();
}
}
查询是分成Scan和get两种的
按指定rowkey获取唯一一条记录:get方法。
按指定条件获取一批记录:scan方法。
实现条件查询功能使用的就是scan方式,scan在使用时有以下几点值的注意:
scan可以通过setCaching与setBatch方法提高速度(以空间换时间)
scan可以通过setStartRow与setEndRow来限定范围。范围越小,性能越高。
scan可以通过setFilter方法添加过滤器,这也是分页(性能差)、多条件查询的基础。