kaggle项目地址
1. 数据探索
import pandas as pd
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
train.info()
test.info()
abs(train.corr()['target']).sort_values(ascending=False)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 241 entries, 0 to 240
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 241 non-null int64
1 sex 241 non-null int64
2 cp 241 non-null int64
3 trestbps 241 non-null int64
4 chol 241 non-null int64
5 fbs 241 non-null int64
6 restecg 241 non-null int64
7 thalach 241 non-null int64
8 exang 241 non-null int64
9 oldpeak 241 non-null float64
10 slope 241 non-null int64
11 ca 241 non-null int64
12 thal 241 non-null int64
13 target 241 non-null int64
dtypes: float64(1), int64(13)
memory usage: 26.5 KB
训练数据241条,13个特征(全部为数字特征),标签为 target
- 特征与 标签 的相关系数
target 1.000000
cp 0.457688
exang 0.453784
ca 0.408107
thalach 0.390346
oldpeak 0.389787
slope 0.334991
thal 0.324611
sex 0.281272
age 0.242338
restecg 0.196018
chol 0.170592
trestbps 0.154086
fbs 0.035450
Name: target, dtype: float64
- 查看特征的值
for col in train.columns:
print(col)
print(train[col].unique())
age
[37 41 56 44 52 57 54 48 64 50 66 43 69 42 61 71 59 65 46 51 45 47 53 63
58 35 62 29 55 60 68 39 34 67 74 49 76 70 38 77 40]
sex
[1 0]
cp
[2 1 0 3]
trestbps
[130 140 120 172 150 110 160 125 142 135 155 104 138 128 108 134 122 115
118 100 124 94 112 102 152 101 132 178 129 136 106 156 170 117 145 180
165 192 144 123 126 154 148 114 164]
chol
[250 204 294 263 199 168 239 275 211 219 226 247 233 243 302 212 177 273
304 232 269 360 308 245 208 235 257 216 234 141 252 201 222 260 303 265
309 186 203 183 220 209 258 227 261 221 205 318 298 277 197 214 248 255
207 223 160 394 315 270 195 240 196 244 254 126 313 262 215 193 271 268
267 210 295 178 242 180 228 149 253 342 157 175 286 229 256 224 206 230
276 353 225 330 290 266 172 305 188 282 185 326 274 164 307 249 341 407
217 174 281 288 289 246 322 299 300 293 184 409 283 259 200 327 237 319
166 218 335 169 187 176 241 264 236]
fbs
[0 1]
restecg
[1 0 2]
thalach
[187 172 153 173 162 174 160 139 144 158 114 171 151 179 178 137 157 140
152 170 165 148 142 180 156 115 175 186 185 159 130 190 132 182 143 163
147 154 202 161 166 164 184 122 168 169 138 111 145 194 131 133 155 167
192 121 96 126 105 181 116 149 150 125 108 129 112 128 109 113 99 177
141 146 136 127 103 124 88 120 195 95 117 71 118 134 90 123]
exang
[0 1]
oldpeak
[3.5 1.4 1.3 0. 0.5 1.6 1.2 0.2 1.8 2.6 1.5 0.4 1. 0.8 3. 0.6 2.4 0.1
1.9 4.2 1.1 2. 0.7 0.3 0.9 2.3 3.6 3.2 2.2 2.8 3.4 6.2 4. 5.6 2.1 4.4]
slope
[0 2 1]
ca
[0 2 1 4 3]
thal
[2 3 0 1]
target
[1 0]
- 一些特征不能用大小来度量,将其转为 分类变量(string 类型,后序onehot编码)
object_cols = ['cp', 'restecg', 'slope', 'ca', 'thal']
def strfeatures(data):
data_ = data.copy()
for col in object_cols:
data_[col] = data_[col].astype(str)
return data_
train_ = strfeatures(train)
test_ = strfeatures(test)
2. 特征处理管道
- 数字特征、文字特征分离
def num_cat_split(data):
s = (data.dtypes == 'object')
object_cols = list(s[s].index)
num_cols = list(set(data.columns)-set(object_cols))
return num_cols, object_cols
num_cols, object_cols = num_cat_split(train_)
num_cols.remove('target')
- 抽取部分数据作为本地验证
# 本地测试,分成抽样,分割训练集,验证集
from sklearn.model_selection import StratifiedShuffleSplit
splt = StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=1)
for train_idx, valid_idx in splt.split(train_, train_['target']):
train_part = train_.loc[train_idx]
valid_part = train_.loc[valid_idx]
train_part_y = train_part['target']
valid_part_y = valid_part['target']
train_part = train_part.drop(['target'], axis=1)
valid_part = valid_part.drop(['target'], axis=1)
- 数据处理管道
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.pipeline import Pipeline
from sklearn.pipeline import FeatureUnion
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_name):
self.attribute_name = attribute_name
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_name].values
num_pipeline = Pipeline([
('selector', DataFrameSelector(num_cols)),
# ('imputer', SimpleImputer(strategy='median')),
# ('std_scaler', StandardScaler()),
])
cat_pipeline = Pipeline([
('selector', DataFrameSelector(object_cols)),
('cat_encoder', OneHotEncoder(sparse=False, handle_unknown='ignore'))
])
full_pipeline = FeatureUnion(transformer_list=[
('num_pipeline', num_pipeline),
('cat_pipeline', cat_pipeline)
])
3. 训练模型
# 本地测试
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import Perceptron
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
rf = RandomForestClassifier()
knn = KNeighborsClassifier()
lr = LogisticRegression()
svc = SVC()
gbdt = GradientBoostingClassifier()
perceptron = Perceptron()
models = [perceptron, knn, lr, svc, rf, gbdt]
param_grid_list = [
# perceptron
[{
'model__max_iter' : [10000, 5000]
}],
# knn
[{
'model__n_neighbors' : [3,5,10,15,35],
'model__leaf_size' : [3,5,10,20,30,40,50]
}],
# lr
[{
'model__penalty' : ['l1', 'l2'],
'model__C' : [0.05, 0.1, 0.2, 0.5, 1, 1.2],
'model__max_iter' : [50000]
}],
# svc
[{
'model__degree' : [3, 5, 7],
'model__C' : [0.2, 0.5, 1, 1.2, 1.5],
'model__kernel' : ['rbf', 'sigmoid', 'poly']
}],
# rf
[{
# 'preparation__num_pipeline__imputer__strategy': ['mean', 'median', 'most_frequent'],
'model__n_estimators' : [100,200,250,300,350],
'model__max_features' : [5,8, 10, 12, 15, 20, 30, 40, 50],
'model__max_depth' : [3,5,7]
}],
# gbdt
[{
'model__learning_rate' : [0.02, 0.05, 0.1, 0.2],
'model__n_estimators' : [30, 50, 100, 150],
'model__max_features' : [5, 8, 10,20,30,40],
'model__max_depth' : [3,5,7],
'model__min_samples_split' : [10, 20,40],
'model__min_samples_leaf' : [5,10,20],
'model__subsample' : [0.5, 0.8, 1]
}],
]
for i, model in enumerate(models):
pipe = Pipeline([
('preparation', full_pipeline),
('model', model)
])
grid_search = GridSearchCV(pipe, param_grid_list[i], cv=3,
scoring='accuracy', verbose=2, n_jobs=-1)
grid_search.fit(train_part, train_part_y)
print(grid_search.best_params_)
final_model = grid_search.best_estimator_
pred = final_model.predict(valid_part)
print('accuracy score: ', accuracy_score(valid_part_y, pred))
Fitting 3 folds for each of 2 candidates, totalling 6 fits
{'model__max_iter': 10000}
accuracy score: 0.4489795918367347
Fitting 3 folds for each of 35 candidates, totalling 105 fits
{'model__leaf_size': 3, 'model__n_neighbors': 3}
accuracy score: 0.5306122448979592
Fitting 3 folds for each of 12 candidates, totalling 36 fits
{'model__C': 0.1, 'model__max_iter': 50000, 'model__penalty': 'l2'}
accuracy score: 0.8979591836734694
Fitting 3 folds for each of 45 candidates, totalling 135 fits
{'model__C': 1, 'model__degree': 5, 'model__kernel': 'poly'}
accuracy score: 0.6326530612244898
Fitting 3 folds for each of 135 candidates, totalling 405 fits
{'model__max_depth': 5, 'model__max_features': 5,
'model__n_estimators': 250}
accuracy score: 0.8775510204081632
Fitting 3 folds for each of 7776 candidates, totalling 23328 fits
{'model__learning_rate': 0.05, 'model__max_depth': 7,
'model__max_features': 20, 'model__min_samples_leaf': 10,
'model__min_samples_split': 40, 'model__n_estimators': 150,
'model__subsample': 0.5}
accuracy score: 0.8163265306122449
LR,RF,GBDT 表现较好
4. 预测
# 全量数据训练,提交测试
# 采用随机参数搜索
y_train = train_['target']
X_train = train_.drop(['target'], axis=1)
X_test = test_
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
import numpy as np
select_model = [lr, rf, gbdt]
name = ['lr', 'rf', 'gbdt']
param_distribs = [
# lr
[{
'model__penalty' : ['l1', 'l2'],
'model__C' : np.linspace(0.01, 0.5, 10),
'model__max_iter' : [50000]
}],
# rf
[{
# 'preparation__num_pipeline__imputer__strategy': ['mean', 'median', 'most_frequent'],
'model__n_estimators' : randint(low=50, high=500),
'model__max_features' : randint(low=3, high=30),
'model__max_depth' : randint(low=2, high=20)
}],
# gbdt
[{
'model__learning_rate' : np.linspace(0.01, 0.3, 10),
'model__n_estimators' : randint(low=30, high=500),
'model__max_features' : randint(low=5, high=50),
'model__max_depth' : randint(low=3, high=20),
'model__min_samples_split' : randint(low=10, high=100),
'model__min_samples_leaf' : randint(low=3, high=50),
'model__subsample' : np.linspace(0.5, 1.5, 10)
}],
]
for i, model in enumerate(select_model):
pipe = Pipeline([
('preparation', full_pipeline),
('model', model)
])
rand_search = RandomizedSearchCV(pipe, param_distributions=param_distribs[i], cv=5,
n_iter=1000, scoring='accuracy', verbose=2, n_jobs=-1)
rand_search.fit(X_train, y_train)
print(rand_search.best_params_)
final_model = rand_search.best_estimator_
pred = final_model.predict(X_test)
print(model,"\nFINISH !!!")
res = pd.DataFrame()
res['Id'] = range(1,63,1)
res['Prediction'] = pred
res.to_csv('{}_pred.csv'.format(name[i]), index=False)
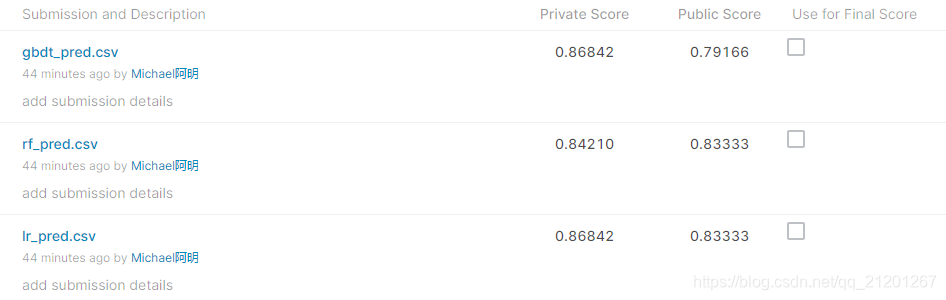
测试效果如下。