因为公司的技术栈里,业务数据和日志的搜索使用的是ElasticSearch这一开源项目,学习不能光停留在使用阶段,要搞清楚就搞个彻底。于是自学了ElasticSearch的相关知识,整体的内容学习都遵循这个框架图
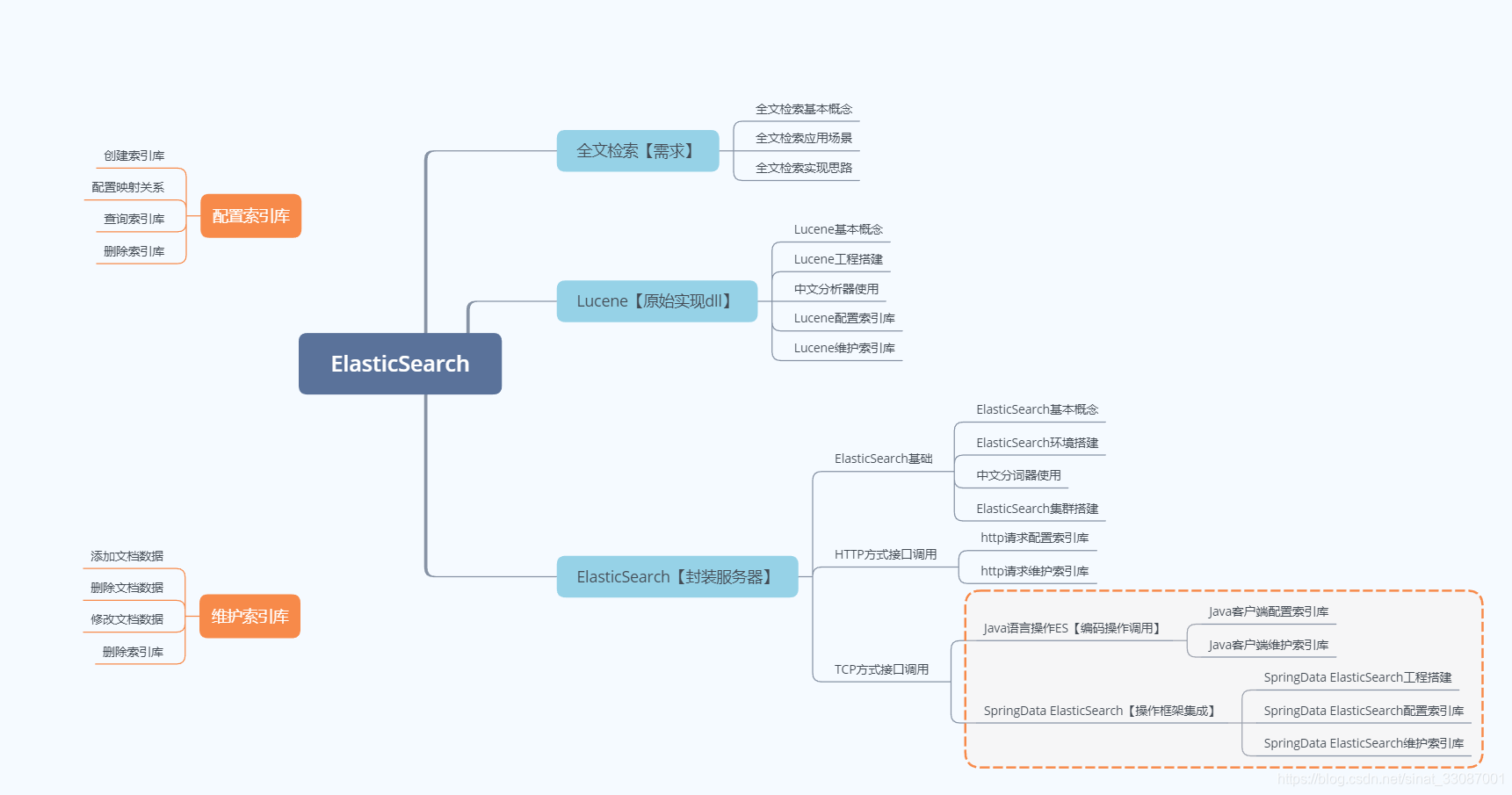
分为几个部分从底至上的去学习,可以用如下的方式去理解:
第一阶段:需求的产生:对于非结构化的数据,如何快速的获取想要的数据,说白了就是如何能进行全文检索
第二阶段:全文检索引擎:Lucene这个开源的jar包可以帮助实现全文检索
第三阶段:便捷的中间件:Lucene的使用较为繁琐,于是在Lucene的基础之上封装了ElasticSearch这样一个中间件来简化Lucene的操作,ElasticSearch的使用方式分为两种:
- 一种是通过HTTP方式进行操作
- 一种则是通过TCP的方式进行操作,也就是我们说的代码调用,可以直接引用ES的Jar包来使用java语言操作,当然代码调用的过程中依然有些不必要的步骤,那么在此之上又封装了一层框架进行调用,也就是SpringData ElasticSearch。
可能我们经常使用的是封装好的SpringData ElasticSearch,或者是基础服务团队自己封装的ElasticSearch框架,但是对于其中的原理我觉得还是有必要深挖,只有知道原理,出了问题才能快速定位问题。本篇blog重点探索需求的产生,接下来的两篇分别讨论Lucene的实现和ElasticSearch的使用。
数据的分类
先来了解一个前置概念:数据类型的分类,数据的来源按数据类型可分为:结构化数据、半结构化数据、非结构化数据。
- 结构化数据:一般是从内部数据库和外部开放数据库接口中获得,一般都是存储产品业务运营数据以及用户操作的结果数据,比如注册用户数、下单量、完单量等数据。这类数据格式规范,典型代表就是关系数据库中的数据,可以用二维表来存储,有固定字段数,每个字段有固定的数据类型(数字、字符、日期等),每个字节长度相对固定。这类数据易于维护管理,同时对于查询、展示和分析而言也是最为方便的一类数据格式。
- 半结构化数据:应用的点击日志以及一些用户行为数据,通常指日志数据、xml、json等格式输出的数据,格式较为规范,一般是纯文本数据,需要对数据格式进行解析,才能用于查询或分析数据。每条记录预定义规范,但是每条记录包含信息不同,字段数不同,字段名和字段类型不同,或者还包含着嵌套的格式。
- 非结构化数据:指非纯文本类数据,没有标准格式,无法直接解析相应值,常见的非结构化数据有富文本、图片、声音、视频等数据。一般将非结构化数据存放在文件系统中,数仓中记录数据的信息,如标题、摘要、创建时间等,方便进行索引查询
对于结构化数据来说我们的查询、展示和分析很方便,强大的SQL语句和规范的表结构让这一点很容易做到,但是对于非结构化数据来说并不容易,尤其是进行查询的时候,如果给你一推文件,让你找出包含某个字符串的所有文件是很难实现的,一个两个还可以目测,多了就不行了。所以如何快速定位到满足查询条件的文档(数据)呢?
全文检索
要想实现上述需求,我们可以按照非结构化数据的处理思路来看:一般将非结构化数据存放在文件系统中,数仓中记录数据的信息,如标题、摘要、创建时间等,方便进行索引查询
于是我们将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
如何实现
可以使用开源的Lucene实现全文检索。Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能
应用场景
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等,总而言之,只要用到搜索的地方,都可以使用全文检索进行搜索,当然这些搜索方式使用的不一定是lucene。
为什么不是关系型数据库
从开始到现在一直在说我们不得不使用全文检索来实现非结构化数据的快速查找,那么有人会问,既然非结构化数据这么麻烦,干嘛咱不都使用结构化数据,使用Mysql的强大功能?有这么几点:
- 数据结构不固定:这个是最关键的一点,关系型数据库是存储不了类型复杂的数据的,而且扩展性也很差,如果需要添加一个字段,那么首先要改表,其次如果有存储过程这些的话还需要全都改一遍,不好维护
- 不满足高并发读写:在web2.0时代,需要依据用户个性化需要高并发读写,关系型数据库读还可以,写就很难做到了。例如论坛这样的站点, 网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈
- 不满足高效访问:海量数据高效率存储和访问, 网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的,类似facebook这样的社交网站、社区。
- 不满足高可拓展性和高可用性:在基于web的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移
对于非关系型数据库再加上全文检索的能力,这些都很容易做到。那这个时候你就会问,那我还用啥关系型啊,其实使用那些要看应用场景:
- 少量数据存储:对于一些关键的元数据、结构简单但非常重要的数据或者一些银行的数据,对事务级别要求高的,用关系型数据库就比较好
- 海量数据存储:对于业务增长量特别大的,业务数据没有特别严格的要求的,事务级别要求低的一些用户数据,用非关系型数据库就比较好
不提应用场景的技术对比就是耍流氓hhh,所以其实还是各有千秋的。下一篇聊聊如何实现需求,Lucene如何大力出奇迹。